采用BERT的无监督NER

图1. 展示了未微调的BERT(bert-large-cased)无监督NER标记的句子样本。 上图仅挑选了用这种方法(BERT)标记的几个实体类型。标记500个句子可以生成大约1000个独特的实体类型——其中一些映射到如上所示的合成标签。BERT模型无法区分GENE和PROTEIN,因为这些实体的描述符(descriptors)与屏蔽词(masked terms)的预测分布落在同一尾部区域(所以无法将它们与基本词汇表中的词汇区分开来)。区分这些密切相关的实体可能需要对特定领域的语料库进行MLM微调,或者使用scratch中自定义词汇进行预训练(下文将进一步阐述)。
TL;DR
在自然语言处理中,为了在句子中识别出感兴趣的实体(NER),如人物、地点、组织等, 我们需要对句子进行标记。其中我们可以手动对每个句子进行标记,或通过某种自动的方法对每个句子进行标记(通常使用启发式方法来创建一个噪声/弱标记的数据集)。随后用这些标记好的句子训练模型以用于识别实体,这可以看作一个监督学习任务。
本文描述了一种无监督NER的方法。NER是使用BERT模型在没有标记句子的情况下无监督地完成的,并且BERT模型仅在屏蔽词模型目标的语料库上进行了无监督训练。
该模型在25个实体类型(维基文字语料库)小型数据集上的F1得分为97%,在CoNLL-2003语料库上的人员和位置的F1得分为86%。 对于CoNLL-2003语料库的人员、位置和组织,F1得分较低,仅为76%,这主要是由于句子中实体的歧义(在下面的评估部分中进行了阐述)。完成这两项测试时都没有对测试的数据进行任何模型的预训练/微调(这与在特定领域数据上对模型进行预训练/微调,或在监督训练中使用带标签的数据形成了鲜明对比)。
它是如何工作?
如果要问术语(term, 术语指文章中的单词和短语)的实体类型到底是什么,即使我们以前从未见过这个术语,但是也可以通过这个术语的发音或句子结构猜得八九不离十。 即,
- 术语的子词结构为它的实体类型提供了线索。
Nonenbury是_____。
- 这是一个杜撰的城市名称,但从它的后缀“bury”可以猜出这可能是一个地点。此时即便没有任何语境,术语的后缀也给出了实体类型的线索。
- 句子结构为术语的实体类型提供了线索。
他从_____飞到切斯特。
此处句子的语境给出了实体类型的线索,未知的术语是一个地点。即便以前从未见过它,但也可以猜测出句子中的空白处是一个地点(如:Nonenbury)。
BERT的 MLM前端(Masked Language Model head)(MLM-图7)可以对上述屏蔽的候选词进行预测,如前所述:它的训练目标是通过预测句子中空白的单词来进行学习。 然后在推理过程中使用这种学习后的输出对屏蔽术语进行预测,预测是基于BERT固定词汇表的概率分布。 这种输出分布有一个明显短小的尾部(大约小于总数的0.1%),其中包括了术语语境敏感实体类型的候选词,此短尾便是用BERT词汇表表示的语境敏感术语的标识。 例如句子中屏蔽位置的语境敏感标识如下所示:
Nonenbury是_____。
语境敏感性预测:村庄(village,Village) 、小镇(hamlet,Hamlet)、 聚居区、教区村、农场 、小镇(Town, town)
BERT固定词汇表(bert-large-cased 为28996个词)是一组通用的描述符集合(如:专有名词、普通名词、代词等)。通过下述聚类过程获得这个描述符集合的子集(有可能重叠),其特征为一个独立于句子语境术语的实体类型。这些子集是独立于语境的术语标识。 在BERT的词汇表中获取接近语境敏感标识的实体类型的过程如下:
['villages', 'towns', 'village', 'settlements', 'villagers', 'communities', 'cities']
['Village', 'village']
['city', 'town', 'City', 'cities', 'village']
['community', 'communities', 'Community']
['settlement', 'settlements', 'Settlement']
['Township', 'townships', 'township']
['parish', 'Parish', 'parishes']
['neighborhood', 'neighbourhood', 'neighborhoods']
['castle', 'castles', 'Castle', 'fortress', 'palace']
['Town', 'town']
在BERT词汇表的嵌入空间中实现最近的匹配函数(基于单词嵌入的余弦相似度),匹配函数在语境敏感标识/集群和语境独立标识/集群之间产生一个表示术语的NER标签的语境独立标识子集。 具体来说,m组术语 {B1,B2,C3,…. Bm} 构成语境敏感标识的集合, n组术语{C11、C12、C13、… Ck1}、{C21、C22、C23、… Ck2}、…{Cn1、Cn₂、Cn₃、… Ckn}构成语境独立标识,生成带有NER标签的语境独立标识子集(如下图2)。
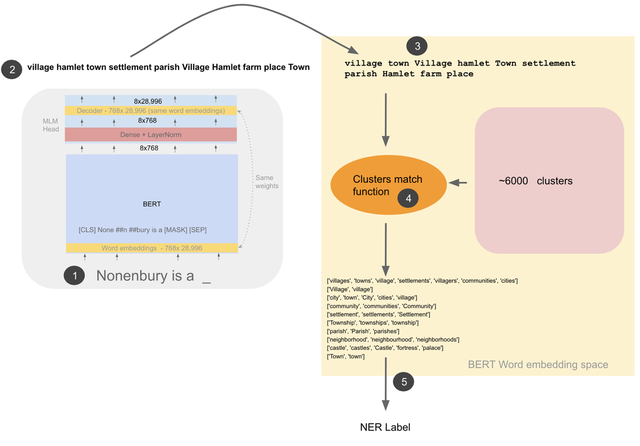
图2. 句子的NER标记。 (1)经过最小预处理后,将带有屏蔽词的句子输入到模型中。 (2)得到BERT词汇表中28996个词汇的前10位预测术语。 (3)这10个术语在BERT的字嵌入空间中通过一个函数重新进行排序。 (4)重新排序后排位位于顶部的k个术语以及6000个集群(离线计算)作为输入,输入到输出匹配集群的集群匹配函数之中。 然后,这些集群的标签(可以是一次性手动标记,或在某些用例中使用)聚合后输出NER标签。 在图中执行3、4和5的函数均在BERT的嵌入空间中使用了单词向量之间的余弦相似性,一次性离线生成约6000个集群也是通过计算BERT词嵌入空间的余弦相似度完成的。 图中BERT基模型隐含的大小为768。文中BERT large cased示例隐含大小为1024。
给定语境独立标识的数目,可以从BERT的词汇表中自动获取数千个标识(bert-large-cased 为6000)。利用这种方法,可以实现在细粒度级别上对大量实体类型进行无监督识别,而无须对数据进行标记。
上述无监督的NER方法应用十分广泛。
- 通过BERT词汇表中的其他词汇,BERT的原始词嵌入可以捕获BERT有用信息和可分离信息(通过词汇量小于0.1%直方图尾进行区分),用它可以生成6000多个集群。
- 带有MLM head的BERT模型输出经过转换之后,可用于对屏蔽词进行预测。 这些预测结果也有一个易于区分的尾部,这一尾部可用于为术语选择语境敏感标识。
执行无监督NER的步骤
一次性离线处理
一次性离线处理为从BERT的词汇表中获取的语境独立的标识集合创建映射,将其映射成单个描述符/标签。
第1步:从BERT的词汇表中筛选对语境敏感的标识术语
BERT词汇表是普通名词、专有名词、子词和符号的混合体,对此集合的最小化过滤是删除标点符号、单个字符和BERT的特殊标记。 进而生成包含21418个术语的集合--普通名词和专有名词相混合,作为描述实体类型的描述符。
第2步: 从BERT的词汇表中生成语境独立的标识
如果简单地从它的尾部为BERT词汇表中的每个术语创建语境独立标识,即便选择较高的余弦相似阈值(对于bert-large-cased模型来说,大约有1%的术语位于平均余弦阈值超过0.5的尾部),也会得到数目相当大的集群(大约20000个)。即便有这么大量的集群,也无法捕捉到这些标识之间的相似性。 所以我们要
- 迭代BERT词汇表中的所有术语(子词和大多数单个字符将被忽略),并为每个术语选择余弦阈值超过0.5的语境独立标识。 将单词尾部的术语视为一个完整的图,其中边的值为余弦相似值。
- 选择与图中所有其他节点具有最大连接强度的节点。
- 将该节点视为由这些节点组成的语境独立标识的主元,此节点是此图中所有其他节点的最近邻居。
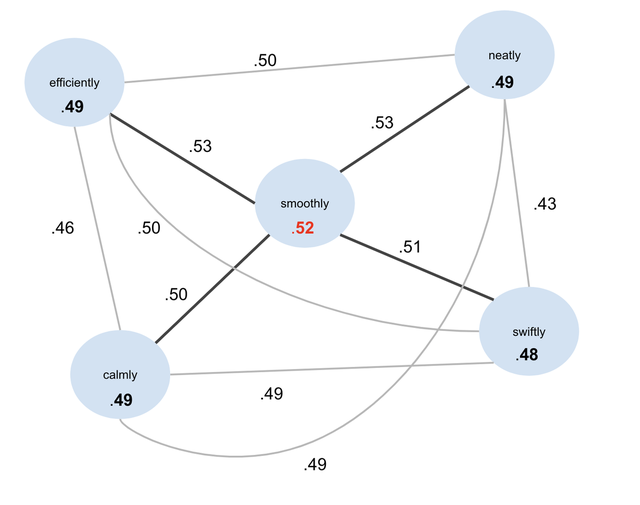
图3. 找到完整图中的主元节点。 在上面的完整图中,“smoothly”节点与其邻居具有最大的平均连接强度。 因此,“smoothly”是此图的主元节点-与此图中所有其他节点最为近邻。
- 一旦术语被选为标识的一部分,它将不会成为候选的评估主元(但是,如果计算出另一个术语的主元节点,它则可能成为间接的主元)。 从本质上讲一个术语可以成为多个集合的元素,可以是主元,也可以是间接主元。
airport 0.6 0.1 Airport airport airports Airfield airfield
stroking 0.59 0.07 stroking stroked caressed rubbing brushing caress
Journalism 0.58 0.09 Journalism journalism Journalists Photography
journalists
smoothly 0.52 0.01 smoothly neatly efficiently swiftly calmly
在上述示例标识中,两个数值是子图中边的平均值和标准差,第一列术语称为该标识的主元术语。 这些术语作为实体标签代理,可以手动映射(一次性操作)成为用户自定义的标签。 图4a和图4b显示了映射这些实体集群的示例,只需对那些代表与我们特定应用程序相关的实体类型的集合进行映射。 可以自动将其余集合映射为合成标签“其他/misc”。 图中的参注部分描述了一种方法,通过使用模型本身来引导/加速描述符,从而手动将其映射到用户自定义标签。
由于大约30%的BERT词汇是专有名词(人名、地点等),我们也仅对一个小的术语集合进行标记(如图4和4b所示:手动标记2000个左右集群需花费约5个工时),而没有对大量的句子进行标记,这看上去有点像是在作弊。将对句子的标记问题转化成标记语境非敏感描述符的主要优点是:它是一个一次性过程。 与有监督训练方法相比,这不可避免地创建出更多的标记数据,不仅要对模型进行训练,而且要对训练完成之后生成的句子(通常是在部署中)重新训练。 然而在这个例子中,最坏的情况是必须重新对BERT模型训练/微调,对这些新句子进行无监督训练-而无需再多做任何标记。
上述的语境非敏感标识将生成大约6000个集合,平均基数约为4/7个节点。 这6000个集合的集群强度平均值为0.59,偏差为0.007-这些集群是相当紧密的集群,集群平均值远远高于从分布中获得的阈值(图4c)。有大约5000个术语(占词汇表的17%)为单例集合,将被忽略。 如果改变阈值,这些数字也会随之改变。 例如阈值选为0.4,总尾质量将增加到0.2%,集群平均值也会相应增加(但如果实体类型混合在一起,集群开始变得嘈杂)。
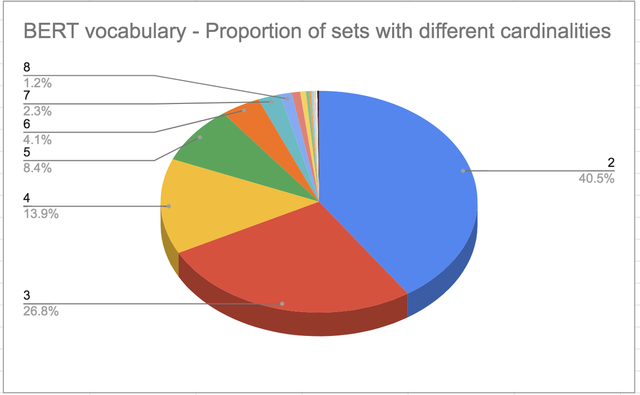
图4. BERT (bert-large-cased)语境独立标识集数据集。平均基数越为4,标准差为7。 这6110个数据集合的集群强度的平均值是0.59,偏差是0.007 -因为平均值远远高于从分布中选取的阈值,这些集群是非常紧密的集群。可以看出:语境敏感的术语往往是相对比较弱的集群,有大约17%的BERT词汇是单例集合。 子词、特殊标记和大多数单字符标记将不会当作集群来考虑。
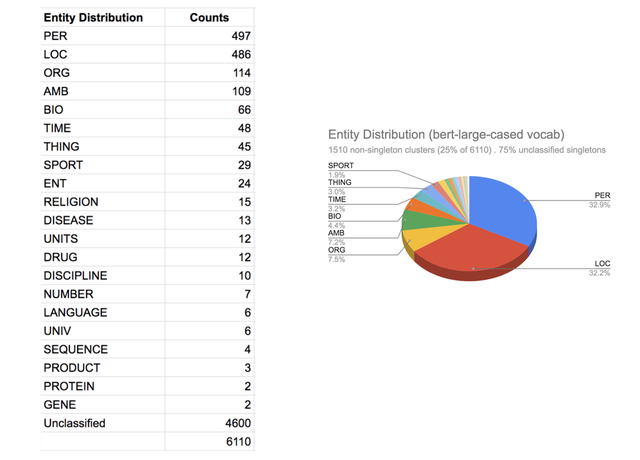
图4a BERT (bert-large-cased)词汇集群的实体分布。 大部分实体为人员、地点和组织(ORG)。 AMB是指集群中的术语不明确的集群,例如,如下图4b所示,有7个集群在人员和地点之间存在歧义,其他集群在人物、事物、体育/传记等方面存在歧义。 当想要找出特定领域的实体类型时,使用自定义词汇表是很有必要的。这些自定义类型可能会消除对人员(PERSON)、地点(LOCATION)和组织(ORG)的歧义。
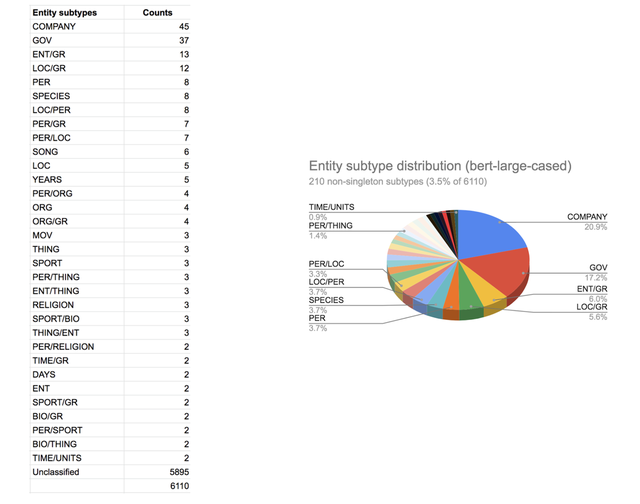
图4b BERT (bert-large-cased)词汇表的实体子类分布。这些是图4a中主要类型的细粒度实体子类型。
从BERT词汇表中获取的语境独立集群示例
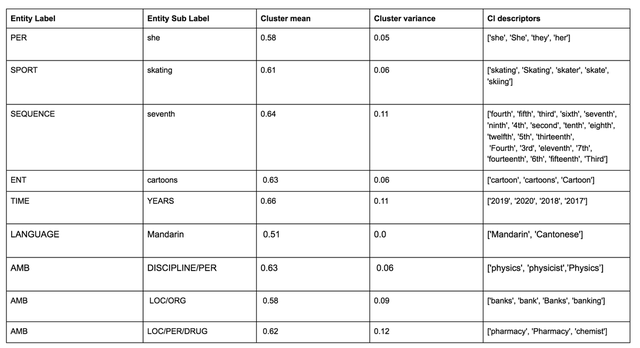
图4c BERT’s (bert-large-cased)词汇表中获取的集群示例。 语境非敏感的集群为模糊集群,标记为AMB。另外要考虑将子词进行聚类时的子词聚类(尽管本文中的实体识别结果已过滤掉类似结果)。
为每个输入的句子预测实体
执行下述步骤为输入的句子标记术语。
第3步:输入句子的最小化预处理
在给一个输入句子标记实体之前,需对输入进行小量的预处理。 其中之一是大小写规一化-所有大写的句子(通常为文档标题)被转换为小写,每个单词中的首字母保持原始状态。 这有助于提高下一步检测短语跨度的准确性。
He flew from New York to SFO
转化为
He flew from New York to Sfo
第4步:识别句子中的短语跨度
用一个POS标签来标记输入句子(理想状态下,训练也会处理所有小写单词句子),这些标签用于识别短语,并将名词首字母转为大写。
He flew from New York to Sfo
上述标记为名词的术语用粗体表示。 BERT的屏蔽词预测对大写非常敏感,为此要使用一个POS标记来可靠地标记名词,即便只有小写才是标记性能的关键所在。 例如对下面句子的屏蔽词进行预测,可以通过改变句子中一个字母的大写来改变实体意义。
Elon Musk is a ____
CS Predictions: politician musician writer son student businessman biologist lawyer painter member
CS预测:政治家、音乐家、作家、儿子、学生、商人、生物学家、律师、画家、成员
Elon musk is a ____(注:musk意为麝香)
CS Predictions: brand Japanese beer German common Turkish popular French Russian Brazilian
CS预测:品牌、日本语、啤酒、德国、通用、土耳其、流行、法国、俄罗斯、巴西
此外,BERT的屏蔽词预测只能可靠地侦测实体类型(上面第一个例子中的人物),并不能对事实进行准确的预测,虽然BERT偶尔也可能会对事实做出准确的预测。
第5步:利用BERT‘s MLM head 预测每个屏蔽词的位置
对于句子中的每个名词术语,生成一个带有该术语屏蔽词的句子。利用BERT的MLM head来预测屏蔽词位置的语境敏感标识。
He flew from __ to Sfo
CS Predictions: Rome there Athens Paris London Italy Cairo here Naples Egypt
CS预测:罗马,雅典,巴黎,伦敦,意大利,开罗,那不勒斯,埃及
He flew from New York to ___
CS Predictions: London Paris Singapore Moscow Japan Tokyo Chicago Boston France Houston
CS预测:伦敦、巴黎、新加坡、莫斯科、日本、东京、芝加哥、波士顿、法国、休斯顿
与在图2中查找主元节点的方法一样,找出集合中每个节点和其它节点之间的强度。然后按强度大小进行排序,得到单词嵌入空间中CS预测的重新排序列表。 重新排序后,有相近实体意义的术语被汇集在一起,此外还需要对嵌入空间中的与语境无关的词重新排序。 例如在下面第一个示例中,经过重新排序之后,将术语“那里”和“这里”(空白位置的有效语境敏感预测)推到了末尾。在下一步中,将选取这些重新排序后节点的前k(k≥1)个节点。
He flew from __ to Sfo
他从__飞到斯佛
CS Predictions: Rome there Athens Paris London Italy Cairo here Naples Egypt
这里、
CI space ordering of CS predictions: Rome Paris Athens Naples Italy Cairo Egypt London there here
CS预测的CI空间排序:罗马、巴黎、雅典、那不勒斯、意大利、开罗、埃及、伦敦、那里、这里
He flew from New York to __
他从纽约飞往__
CS Predictions: London Paris Singapore Moscow Japan Tokyo Chicago Boston France Houston
CI space ordering of CS predictions: Paris London Tokyo Chicago Moscow Japan Boston France Houston Singapore
CS预测的CI空间排序:巴黎、伦敦、东京、芝加哥、莫斯科、日本、波士顿、法国、休斯顿、新加坡
第6步:找出语境敏感标识和语境独立标识之间的密切匹配
利用一个简单的紧密匹配函数便可生成合理的结果,它从上一个术语中选择一个语境敏感标识的主元节点,使之与语境独立标识集中的所有6000个主元做点积,然后对它们进行排序,以获得候选实体标记。此时从本质上来讲,紧密匹配函数是找出离语境敏感集群主元最近的那个语境非敏感集群主元的关键。为提高标签/预测的可信度(图5),我们选取顶部前k个主元,而非选取顶部的那个主元。

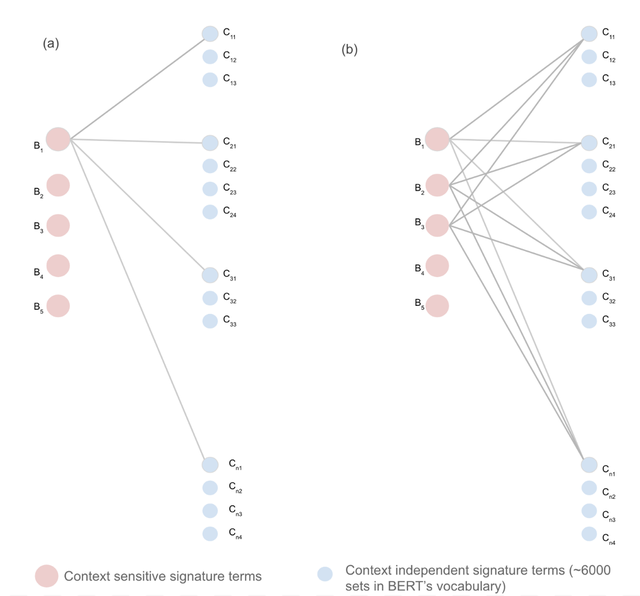
图5. 词嵌入空间中语境敏感标识和语境独立标识之间的紧密匹配。实现紧密匹配的最为有效简单的方法是:语境敏感标识的主元节点与语境独立标识中集合的主元之间的点积。此时,紧密匹配函数本质上是找出离语境敏感集群主元最近的那个语境非敏感集群主元。另外一个更优的实现是:根据语境敏感标识中节点的均值和标准差决定是否将其选为主元节点,然后在二分图中选定要考虑的主元数,以找到与每个语境敏感集群主元最近的那个语境非敏感集群主元。(b)图中显示的情况为:当语境敏感词计数是3,并且只有一个语境独立的术语节点(为中断二者之间的关系,在这里选取奇数可能相对更优一些;同样,也无需从语境非敏感集合中选取三个节点,因为它们是紧密的集群,正如前面所述,平均偏差为.007)。 在计算中使用所有语境敏感标识中的节点不太可能生成良好的结果,因为语境敏感节点的平均标准差要高出许多。由于在嵌入空间中评估语境敏感标识时,会扩展到在更大的区域范围,即使在捕获单个实体类型时也是如此。
对语境敏感的标识中顶部那个主元的标记预测如下所示。 标记以及用户标签如下所示:
He flew from __ to Sfo
他从__飞到斯佛。
CI space ordering of CS predictions: Rome Paris Athens Naples Italy Cairo Egypt London there here
CS预测的CI空间排序:罗马、巴黎、雅典、那不勒斯、意大利、开罗、埃及、伦敦、这儿、那儿
Tags: Italy Venice Athens Bologna Madrid Carthage Roma Sicily Turin Vatican
标记:意大利、威尼斯、雅典、博洛尼亚、马德里、迦太基、罗马、西西里、都灵、梵蒂冈
User Label - location location location location location location location location location location
用户标签-地点 地点 地点 地点 地点 地点 地点 地点 地点 地点 地点 地点 地点
He flew from New York to __
他从纽约飞往__。
CI space ordering of CS predictions: Paris London Tokyo Chicago Moscow Japan Boston France Houston Singapore
CS预测的CI空间排序:巴黎、伦敦、东京、芝加哥、莫斯科、日本、波士顿、法国、休斯顿、新加坡
Tags: London Madrid Geneva Vienna Bordeaux Chicago Metz Athens Cologne Istanbul
标记:伦敦、马德里、日内瓦、维也纳、波尔多、芝加哥、梅茨、雅典、科隆、伊斯坦布尔
User Label - location location location location location location location location location location
用户标签-地点 地点 地点 地点 地点 地点 地点 地点 地点 地点 地点 地点 地点
评价结果
该模型在两个数据集上进行了评估:(1)具有三种实体类型(人员,位置,组织)的标准数据集CoNLL-2003,以及(2)具有约25种实体类型的Wiki文本数据集。
在CoNLL-2003集中,所有三种数据类型(PER-81.5%; LOC-73%; ORG — 66%; MISC-83.87%)的平均F1得分仅为76%。这是由于两个原因:
- 测试数据中很大一部分的CoNLL文本结构不是完整的句子,而是板球分数的简洁报告,它并没有规则的句子结构。由于该模型未经过句子的预训练或微调,因此很难预测这些分布句子中的掩盖词。实际上,可以通过预训练或对新句子结构上的模型进行微调来改善这种情况。
- 测试数据将许多来自特定地区的球队标记为一个位置。该模型总将它们标记为位置,而不是团队名称(org)。使用这种无监督NER方法无法轻松解决此问题。它总会选最能与屏蔽位置匹配的实体描述符来标记术语,而不是那些人工标记术语。尽管从某种意义上讲这是个弊端,但这也是模型的关键优势-它用来标记屏蔽位置的描述符自然是从受过训练的语料库中出现的,而非从外部标记的人那里学到的。将这些描述符映射到用户定义的标签可能是一种方法,但可能不是一个完美的解决方案(例如上述将位置的描述符视为组织和位置的模糊标签的情况)。
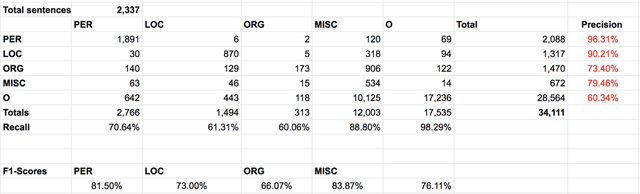
图 5a. CoNLL-2003 结果
该模型评价基于少量测试数据,但其具有完整的自然句集和大约25种标签类型,平均F1-分数约为97%。
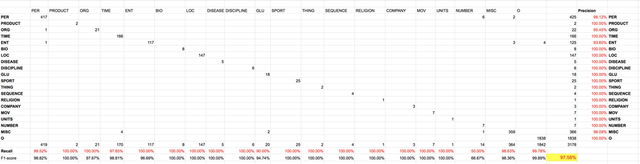
图 5b. 25个实体类型的 Wiki 数据结果
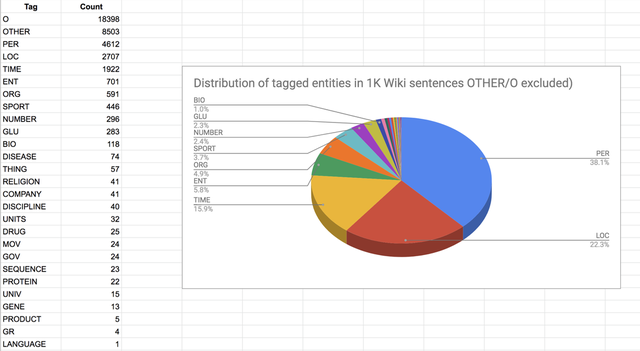
图5c. Wiki数据集的实体分布。在该数据集上,F1平均成绩为97%。这种方法的主要区别在于,不仅不对模型进行标签数据训练,甚至不对模型进行预训练(对模型进行测试)
方法的局限性和挑战
语料库偏倚
尽管单实体预测展现了模型如何运用子词信息解释实体类型的能力,但在实际应用中,它们只能与具有多个实体类型的句子一起使用。 没有太多语境的单个实体句子对语料库偏倚非常敏感,如对谷歌和Face book的预测:
Facebook is a __
脸书网是__。
CS Predictions: joke monster killer friend story person company failure website fault
CS预测:笑话、怪物、杀手、朋友、故事、人物、公司、失败、网站、故障
Microsoft is a __
微软是个__。
CS Predictions: company website competitor people friend player Winner winner person brand
CS预测:公司、网站、竞争对手、朋友、玩家、赢家、人物、品牌
Google is a __
谷歌是个__。
CS Predictions: friend website monster company killer person man story dog winner
CS预测:朋友、网站、怪物、公司、杀手、人物、男士、故事、狗、赢家
实体预测的模糊性
这种方法会产生两种歧义:
- 以语境非敏感描述符为特征的实体类型中存在模糊性(图4c中的示例)。 包含“banks, bank, Banks, banking”的集群可以代表一个组织或地点。 然而这种模糊性通常可以得到解决,当通过实体类型的多数投票将语境敏感标识与语境非敏感标识紧密匹配时,即使一些匹配的语境非敏感标识也是模糊的。
- 下文描述的第二种歧义难以解决。
有一些句子允许用不同的实体类型填充一个屏蔽后的术语。例如在下面的句子中预测纽约的实体类型时:
He felt New York has a chance to win this year's competition
他觉得纽约有机会赢得今年的比赛。
屏蔽单词的实体预测可能会是一个暗示人物的词,句子同样通顺,如下所示:
He felt __he____ has a chance to win this year's competition
他觉得__他____有机会赢得今年的比赛。
模糊性由屏蔽词引起,大多数情况可以通过确定屏蔽术语本身的实体类型-纽约来解决。
New York is a _____
纽约是个_____。
CS Predictions: city town place City capital reality square country dream star
CS预测:城市、小镇、城镇、首府、现实、广场、乡村、梦、星星
然而,在某些情况下,即使是被屏蔽的术语也是模棱两可的,从而使得实体的确定富有挑战性。 例如如果原句为:
He felt Dolphins has a chance to win this year's competition.
他觉得海豚有机会赢得今年的比赛。
海豚可以是一个音乐团体或运动队。
这些挑战可以通过以下多种方法得以改善:
- 在专有术语语料库上,对模型进行微调,可以帮助减少特定领域实体类型中的歧义。 例如,BERT预训练中的BRA F(是一个基因)在其特征没有基因意义,而基因意义却存在于一个在生物医学语料库上微调的模型之中。
BRAF is a _____
BRAF是_____。
CS Prediction: British German new standard the variant name version World world
CS预测:英、德、新的标准、变体名称、版本、世界
在一个生物医学语料库模型上微调之后:
BRAF is a _____
BRAF是_____。
CS Prediction: protein gene kinase structural non family reaction functional receptor molecule
CS Prediction:蛋白基因、激酶结构、非家族反应、功能、受体、分子
- 先从一个用户自定义的词汇表开始对模型进行预训练(附链接:https://towardsdatascience.com/pre-training-bert-from-scratch-with-cloud-tpu-6e2f71028379),可以帮助解决实体歧义的问题,更为重要的是:它还可以提高实体标记性能。虽然BERT默认的词汇非常丰富,有完整的单词和子词来检测实体类型,如人物、地点、组织等(图4a和b),但是它无法捕获在生物医学领域的全部和部分术语。 例如,imatinib, nilotinib, dasatinib等药物的标记则不会考虑“tinib”这个常见的亚词。 imatinib被标记为i##mat##ini#b,而dasatinib被标记为das##at i##ni##b。 如果利用生物医学语料库上的句型来创建自定义的词汇,便会得到im##a##tinib和d ##as ##a ##tinib ,进而得到了常用的后缀。 此外自定义词汇包含来自生物医学领域的完整单词,能更好地捕捉生物医学领域的特征,比如像先天性、癌、致癌物、心脏病专家等医学领域专业词汇,它们在默认的BERT预先训练的模型中不存在。 在默认的BERT的词汇表中捕获人和地点信息将被在生物医学语料库中捕获药物和疾病条件等专有名词和子词所取代。此外从生物医学语料库中提取的自定义词汇约有45%的新全词,其中只有25%的全词与公开可用的BERT预训练模型重叠。 当微调BERT模型添加100个自定义词汇表时,会为之提供一个选项,但却为数不多,而且如前面提到的,默认的BERT的词汇表对人物、地点、组织等实体类型会产生严重歧义,如图4a所示。
Token: imatinib dasatinib
BERT (default): i ##mat ##ni ##b das ##ati ##nib
Custom: im ##a ##tinib d ##as ##a ##tinib
文后的一些想法
NER是从输入句子到与句子中术语对应的一组标签的映射任务。传统的方法通过对模型训练/微调,利用标记后数据的监督任务来执行该映射。不同于BERT这样的预训练模型,该模型在语料库上进行无监督学习。
本文描述了一种在没有改变预训练/细调的BERT模型情况下,对屏蔽语言目标执行无监督NER的方法。通过对学习的分布式表示(向量)端到端操作来实现,向量处理的最后阶段使用传统算法(聚类和最近邻)来确定NER标签。 此外与大多数情况下顶层向量用于下游任务的情况相反,BERT对屏蔽句子的输出只作为种子符号信息,在其自己的最低层实现单词嵌入,从而获取句子的NER标签。
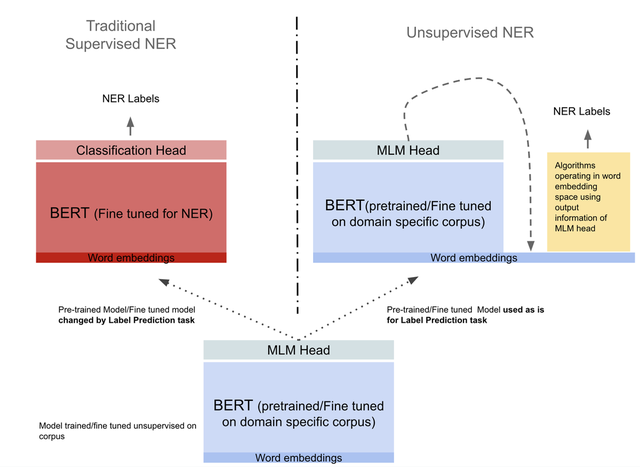
图6. 传统的监督NER(左侧图)与本文描述的无监督NER(右侧图)对比图。 传统的监督NER是有监督的标签映射任务,通过对模型的训练/微调来执行任务(左侧图)。 相反无监督的NER则使用一个预训练/微调模型,训练无监督的屏蔽词模型目标,并将模型的输出作为种子信息,在BERT模型的最底层-单词嵌入上进行算法操作,从而获取句子的NER标签。
总之执行NER所需的所有信息,从传统意义上来讲是一个有监督的学习任务,它也已存在于无监督的BERT模型中,其底层的关键部分即为单词嵌入。
关联工作/参考文献
https://homes.cs.washington.edu/~eunsol/open_entity.html 2018年发表的这篇文章采用了远程监督进行实体识别。 细粒度标签为众包的训练模型。
https://www.aclweb.org/anthology/N19-1084.pdf .本文利用有监督的多标签分类模型,对10,000多个实体类型进行细粒度实体键入
命名实体识别一直是一个广泛研究的问题,迄今为止,在arXiv上大约有400篇相关论文,谷歌学者自2016年至今大约有62,000个搜索结果。
检查BERT的原始嵌入:https://towardsdatascience.com/examining-berts-raw-embeddings-fd905cb22df7
补充说明
Berts MLM head-简要回顾
BERT MLM head本质上是BERT顶部的单一转换层。下图中显示了BERT输出的一个带有9个标记的句子(在标记化之后),它是一个9x768矩阵(BERT基模型的维数是768)。 然后传递给MLM head的稠密层,在9x768输出上对所有28996个单词向量执行点积,以找出句子中哪个位置的向量输出与28996个单词向量的相似度最高。对于位于这个位置的被屏蔽单词,生成一个预测的标签。 在训练/细调模式下,屏蔽词的预测误差被反向传播到模型中,一直传播到嵌入的单词(解码器权重和嵌入层权重绑定/等值)。 在推断模式下,用嵌入来表示标记文本,以及在头顶层的输出日志。
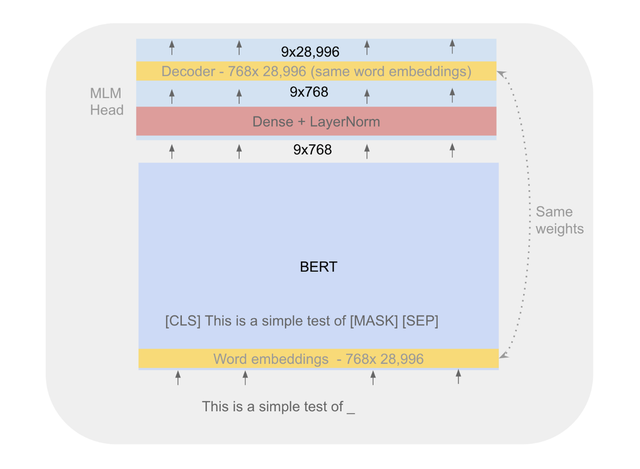
图7. BERT’s MLM head--显示流过模型的一个9字标识输入及其MLM head。 解码器使用来自嵌入层的同一向量(在代码中绑定权重-但单独驻留在pytorch.bin文件中)。
方法性能
对于下述句子,
![]()
在典型的采用BERT的监督方法中,通过将整个句子完整输入到一个微调的BERT模型, 我们可以得到如下所示的NER输出标签(B_PER、I_PER、O...)。

本文中描述的无监督NER方法,要求将上述句子分四次传递给一个MLM’s head,以确定四个实体-John Doe,New York,RioDe Janiro和Miami (正如前面所描述,这四个实体的位置是由一个POS标签与一个chunker协同识别)。

具体而言,句子的下述4个标记版本将被传递到MLM模型中

检索出每个屏蔽词位置的语境敏感特征,然后将其与语境非敏感特征匹配,以生成每个位置的实体预测,如下所示。

虽然原则上可以通过一次性检索输入句中每个标识的MLM语境敏感标识,但实际上应将带有屏蔽词的句子单独发送给MLM模型,以确定实体类型,因为不清楚是否能将短语或子词的语境敏感预测结合起来进行预测 (如果原始句子只有一个单词实体,并且这些单词的标记版本也存在于BERT的词汇表中,便可以在一次传递中推断出敏感标识)。 举个例子:像诸如New York 等短语,以及Imatinib — I ##mat ##ini ##b等子词,均出现在BERT词汇表中。如果一个子词含有多个默认的含义的话,问题则变得复杂化,比如: I in Imatinib - I ##mat ##ini ##b,会产生一个高方差的语境敏感的标识。可以对子词进行波束搜索(beam search)生成新的可信的单个标记,但它可能不是基础词汇表的一部分,导致语境敏感标识的偏差变大。 可考虑将SpanBERT视为一个选项,来加大预测的跨度,但它也仅仅是对屏蔽短语的各个标记进行预测,而没有给出屏蔽短语的预测。
对带有多个屏蔽词的句子预测可以通过并行预测这个句子的所有屏蔽版本来解决。 在上面的例子中,屏蔽术语占句子中总术语数的50%,但在实际项目中往往低于这个平均数。 如果用一个独立的句子来确认每个术语在句子中的实体预测,如 “术语是一个___”这样的句子, (像“Nonenbury是一个___”这样的句子),那么发送给MLM模型进行预测的句子数量将是句子中屏蔽术语数量的两倍。
为用户自定义的标签引导映射标签描述符
如果是对应用的一组特定实体集合感兴趣,那么也可以利用任何未标记的语料库,其中这些实体主要是通过如下方式获得:
- 将这些句子输入到模型中,让模型输出它们的标签描述符。
- 对这些描述符的发生次数计数排序,得到最感兴趣的几个描述符。
- 手动扫描这些描述符并将它们映射到选定的实体标签。
- 如果用来获取这些标签的未标记语料库代表了真实的实体类型,那么它将涵盖绝大部分实体类型。
这种无监督的方法:
- 将句子与特定用例中感兴趣的实体的标记问题转化为标记代表感兴趣标签的语境非敏感描述符。正如前文所述,这样做减少了用更多标记数据重新训练模型的数目。
- 此外还采用了一个POS标签,用该标签对有监督训练的所有句子进行标记。然而,识别标识和候选描述符的关键部分是由BERT执行的,而BERT是经过训练/细调的无监督训练。
无子词过滤的语境无关群集统计信息
由于难以找到子词的标签,因此未考虑将子词用于创建语境无关的群集。 但是将它们纳入考虑的集群可以获取对某些应用有潜在价值的信息。BERT的模型词汇有6477个子词,其中1399个组成了主元。 其余的被分到59个非子词主元中(2872是单例)。
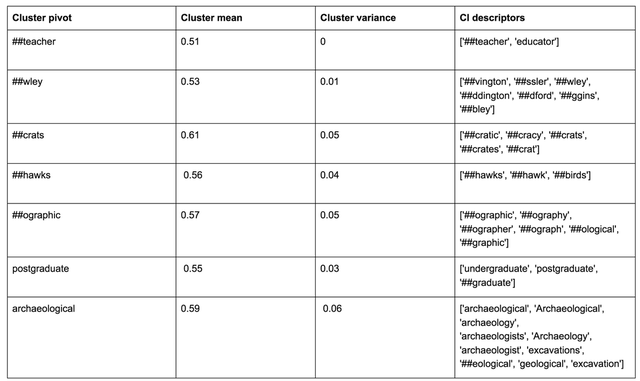
子词作为主元以及包括子词的其他非子词主元的语境不相关群集。 生成语境不敏感群集并未包含子词,在此处显示这些子词只是为了强调某些群集捕获了有趣的可解释信息(其他不构成实体标签的观点)。
本方法的其他应用
由于实体类型的确定纯粹是基于一组术语进行的,本方法可以应用于多种应用程序
- 查找两个或多个术语是否具有相同的实体类型。 分别输入包含这些术语的句子,找出语境敏感的标识,并检查模型输出的标签是否相同/相似。
- 获取特定实体类型的更多术语。
- 当不仅仅限于标记名词短语时,本方法的输出可以(可选择:与POS标签和依赖解析器一起)用于为下游监督任务生成标记数据,如分类、关系提取等。 在某些情况下,即便不对监督任务本身进行替换,至少也可以创建出一条基础线。
本文从Quora手工导入




















