用Transformer分清女排运动员,时空双路框架刷群体行为识别SOTA
编辑:好困
【新智元导读】本文作者提出了一种简洁的Dual-AI框架,它以两种互补的顺序灵活地安排空间和时间Transformer,通过整合不同时空路径的优点来增强个体间的关系。
群体行为识别(Group Activity Recognition)不同于寻常的关于个体动作的行为识别(Action Recognition),需要通过分析视频中所有参与群体活动的个体之间的关系,进一步结合场景信息,对群体活动的行为类别做出判别。
以下面排球比赛视频为例,算法需要分析场上12位运动员的动作、交互以及场景内容,综合判断得到场上在进行左侧击球(left-spike)群体行为。

被忽略的互补建模顺序
由于群体行为识别的多粒度特性以及明确的粒度含义(个体-群体),GCN、transformer以及CNN的attention模块都经常被用作对群体进行建模的工具。
但是,以往的工作,如ARG、SAM和Actor Transformer都仅以一个时空顺序对个体关系进行建模,即时间-空间(TS,Temporal- Spatial)或空间-时间(ST,Spatial-Temporal)。
最近,来自悉尼科技大学、新加坡国立大学以及中科院深圳先进院等机构的作者发现,不同的时空建模顺序对于个体之间的关系模型,进一步对群体行为关系判别有着不同的优势。
如图1(a)所示,个体1和4分别进行起跳击球和起跳拦网的动作,先进行时间建模可以更好地捕捉个体的动作特性;进一步分析个体1-4的空间场景关系,可以通过左侧队伍(个体2/3在等待个体1起跳击球)和右侧队伍(多个个体起跳拦网)的空间关系,更好地表达左侧击球的群体特征(left-spike)。
而在图(b)中,个体2和个体1都在进行起跳(一个佯攻,一个传球)的动作,如果先进行时间建模,则会混淆后续的空间建模和群体行为判定;反而,先进行空间建模,可以更好地得到同侧队友之间的场景信息和空间关系,进一步的时间建模,可以更好地区分个体1和个体2的起跳行为,进而得到正确的群体行为分类。
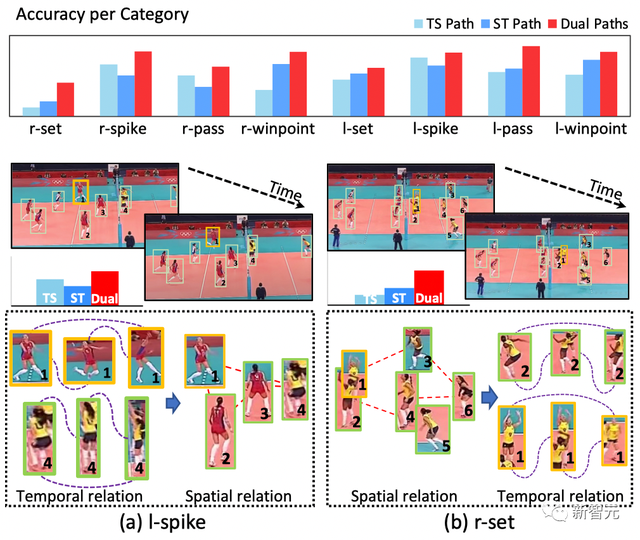
图1 不同的时空建模顺序适合于不同的群体行为类别
Dual-AI互补的时空建模
基于上述观察和动机,作者提出了简洁的Dual-AI框架,通过对视频中所有个体特征的关系建模,得到互补的个体和群体行为特征。论文已被CVPR 2022 Oral收录。

论文地址:https://arxiv.org/abs/2204.02148
如图2所示,空间建模(S-Trans)仅对一帧内的N个个体进行关系建模,时间建模(T-Trans)建模一个个体在不同帧中的关系。
通过对T-Trans和S-Trans不同顺序的堆叠,即可以得到互补的时空特征表达,在分类器得到行为判别后, late-fusion得到融合结果。
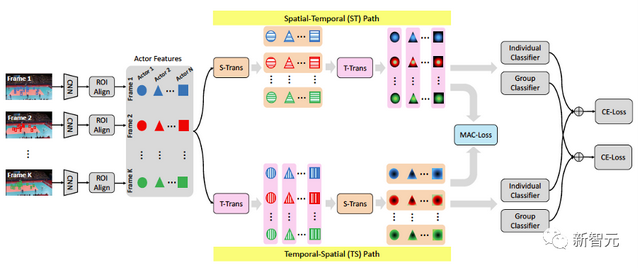
图2 简洁的互补时空建模Dual-AI
另外,为了更好地约束两个独立分支的特征交互,作者提出了多尺度的个体对比损失函数(MAC-Loss,Multi-scale Actor Contrastive Loss)。其核心是在时空建模后,相比于其他个体特征,同一个体特征表达应该有着一定的相似性。
如图3所示,作者提出个体在帧(Frame)级别和视频(Video)级别特征表达在不同建模分支间的对比损失关系,即帧-帧(F-F,Frame-Frame)、帧-视频(F-V,Frame-Video)和视频-视频(V-V,Video-Video)。
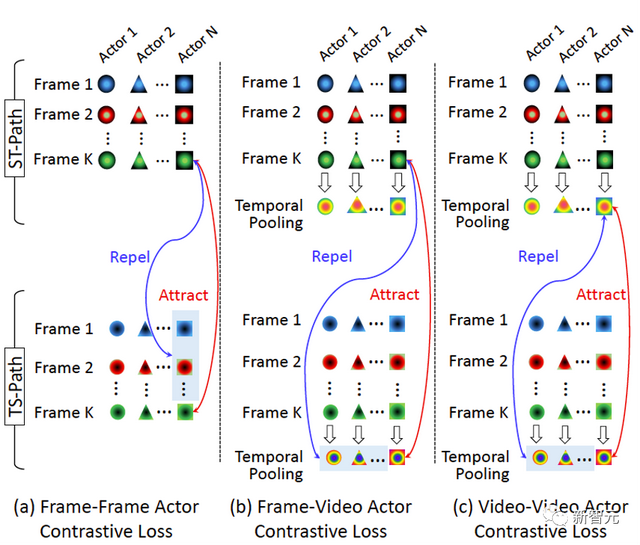
图3 多尺度的个体损失函数MAC-Loss
多种数据设定验证
在全监督设定下,模型通常需要场上参与群体行为的个体的标注包围框、个体的动作标签以及群体行为标签,如图4所示。

图4 全监督提供12位运动员的精细标注
为了进一步减少标注成本,也为了检验模型的鲁棒性,文章提出有限数据设定(limited data),验证模型在有限标注数据(如50%)下的表现;同时,文章也在弱监督设定(不提供个体真值标注,如包围框和行为类别,如图5)下验证了方法的有效性。

图5 弱监督引入场外噪声,减少标注成本
先进和鲁棒的实验结果
如表1和表2所示,以最常用的Volleyball dataset为例,作者用同一个模型在全监督和弱监督设定下都实现了当前最优的结果。
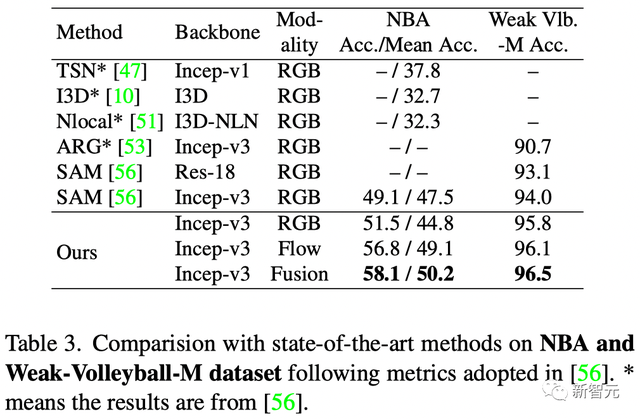
表1 弱监督设定下的精度比较
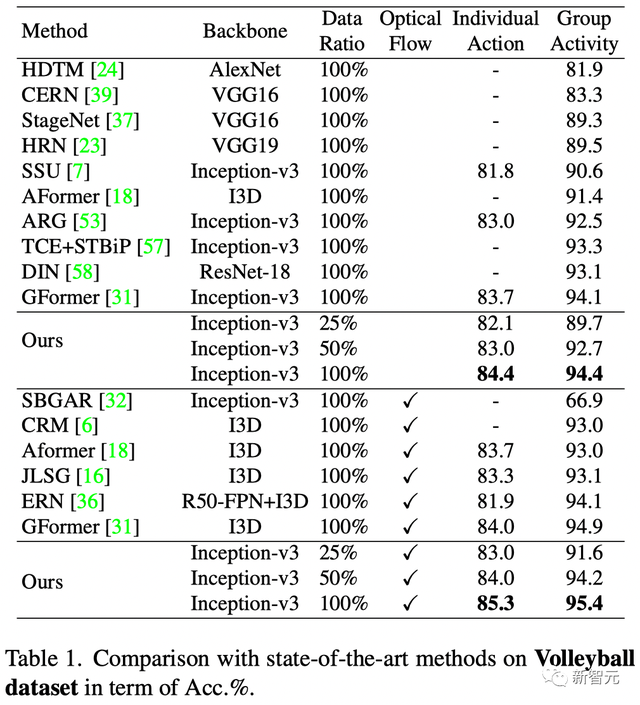
表2 Volleyball Dataset下的精度比较
更令人印象深刻的是,如图6所示,作者用50%的数据可以达到以往SOTA方法100%数据的精度;在仅适用25%数据的情况下(同时使用光流输入),仍得到与其他方法相持平的表现。
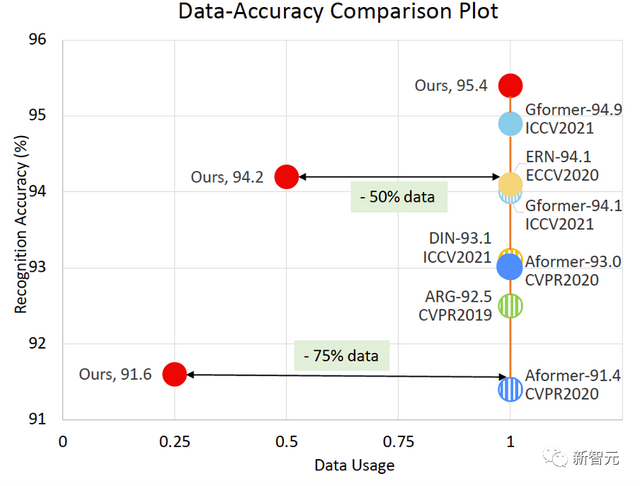
图6 不同数据量下的精度,实心点表示同时使用光流输入
导师介绍
王亚立,中国科学院深圳先进技术研究院,副研究员。中国科学院青年创新促进会成员、深圳市孔雀人才、后备级人才、领航人才。
重点从事深度学习与计算机视觉、模式识别与机器学习等人工智能前沿研究。在CVPR、ICCV、ECCV、ICLR、NeurIPS、ICML、AAAI等相关领域顶级刊物发表高水平论文近50篇,包括9篇Oral论文。
获得广东省技术发明一等奖、吴文俊人工智能科技进步二等奖、深圳市科技进步奖二等奖。获得加拿大FRQNT国际奖学金、腾讯AI Lab犀牛鸟基金、国家留学基金委公派留学奖学金等奖励。
作为项目负责人获批国家自然科学基金(面上、青年)、深圳市基础研究项目,重点参与国家重点研发计划、NSFC-深圳机器人基础研究中心项目、广东省应用研发等10余重大科技项目。
近5年申请30项发明专利,授权发明专利8项,通过横向项目转移给华为、腾讯等龙头人工智能公司9项。
王亚立老师课题组欢迎各位同学报考及联系,招聘类别包括:即将参加硕士生保研及夏令营推免的同学(2023年入学),客座学生(已完成课程的本科生、研究生,长期招聘),2023年考研等。
SIAT多媒体技术研究中心
中国科学院深圳先进技术研究院多媒体技术研究中心主要致力于计算机视觉、深度学习、多媒体、智能机器人等领域的研究和开发。
中心团队在包括PAMI、T-IP、IJCV、CVPR、ICCV、ECCV、AAAI等会议和期刊上发表学术论文300余篇,多次在ChaLearn、LSun、ActivityNet、EmotionW等国际评测中取得第一, 获AAAI 2021杰出论文奖。
简历投递(邮箱地址):
夏令营推免相关信息:
http://szs.siat.ac.cn/#/detail?item=%5Bobject%20Object%5D&list=%5Bobject%20Object%5D&contentId=1374
多媒体中心简介:
http://mmlab.siat.ac.cn/aboutus?menu=1
参考资料:
https://arxiv.org/abs/2204.02148