写代码总是莫名其妙的乱码?这一篇教你从原理出发彻底干掉它

前言
中文乱码问题在我们日常开发中司空见惯,那么乱码问题是如何产生的呢?又怎样去解决乱码问题呢?本文将结合基本概念和例子展开阐述,希望大家有收获。
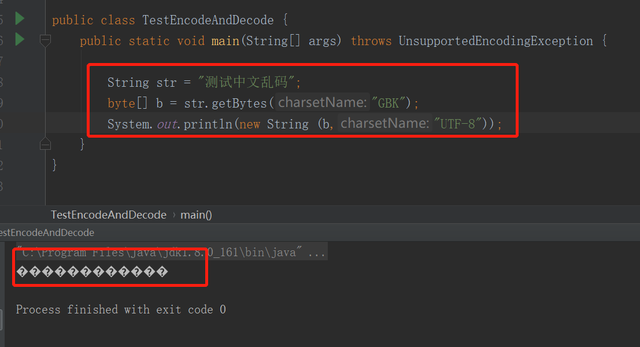
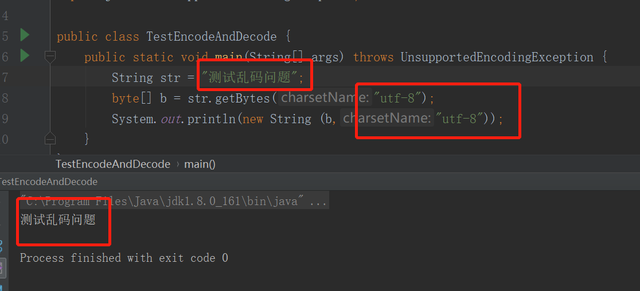
一个简单乱码的例子package whx;import java.io.UnsupportedEncodingException;public class TestEncodeAndDecode { public static void main(String[] args) throws UnsupportedEncodingException { String str = "测试中文乱码"; byte[] b = str.getBytes("GBK"); System.out.println(new String (b,"UTF-8")); }}复制代码
用GBK编码,用utf-8解码,产生乱码,运行结果如下:
相关基础概念
要理解乱码的根源,需要先了解清楚位、字节、字符、字符集等相关概念。
位(bit)
位是计算机存储数据的最小单位,1或者0就表示1位,如10010010就表示8位的二进制数。
字节
字节是计算机信息技术用于计量存储容量的一种计量单位,作为一个单位来处理的一个二进制数字串,是构成信息的一个小单位。
1 B = 8 bit (1字节等于8位)1 KB = 1024 B = 1024 字节1 MB = 1024 KB 1 GB = 1024 MB1 TB = 1024 GB复制代码字符
字符是指计算机中使用的字母、数字、字和符号,是数据结构中最小的数据存取单位。如a、A、B、b、大、+、*、%等都表示一个字符;
在 ASCII 编码中,一个英文字母字符存储需要1个字节。在 GB 2312 编码或 GBK编码中,一个汉字字符存储需要2个字节。在UTF-8编码中,一个英文字母字符存储需要1个字节,一个汉字字符储存需要3到4个字节。在UTF-16编码中,一个英文字母字符或一个汉字字符存储都需要2个字节在UTF-32编码中,世界上任何字符的存储都需要4个字节复制代码字符集
字符集是多个字符的集合,字符集种类较多,每个字符集包含的字符个数不同。常见字符集名称:
ASCII字符集GB2312字符集Unicode字符集复制代码编码、解码
计算机只认识二进制的1和0,而人类都是有自己的语言的,双方要能进行信息交流,必须要有从文字到0、1的转化,以及0、1到文字转化。
编码: 就是将文本字符转换成计算机可以识别的0、1机器码。
解码: 将存储在计算机中的二进制数解析成文字、字符。
常见字符集及其编码方式
常见字符集有ASCII、GBK、Unicode等
ASCII字符集
ASCII字符集:它包括英文字母、阿拉伯数字和西文符号等可显示字符,以及回车键、退格等控制字符。
ASCII 编码:它是美国制定的字符编码,用于将英语字符转化为二进制,规定了128个字符的编码。
GBXXXX字符集
GBXXXX系列包括GB2312、GBK、GB18030,适用于汉字处理、汉字通信等系统之间的信息交换。
GB2312
- 全称是《信息交换用汉字编码字符集》,支持六千多汉字。
- 国家简体中文字符集,兼容ASCII,中国大陆和新加坡都采用此编码。
- 每个汉字及符号以两个字节来表示。
- 高字节从A1~F7, 低字节从A1~FE。将高字节和低字节分别加上0XA0即可得到编码。
GBK
- GBK全称《汉字内码扩展规范》,扩展了GB2312,加入对繁体字的支持,支持两万多汉字。
- 每个汉字及符号也是以两个字节来表示。
- 高字节从81~FE,低字节从40~FE。
GB18030
- GB 18030,全称《信息技术 中文编码字符集》,与GB2312、GBK编码兼容,可支持27484个文字
- 采用变长多字节编码,每个字可以由1个、2个或4个字节组成。
- 1字节从00~7F; 2字节高字节从81~FE,低字节从40到7E和80到FE;4字节第一三字节从81~FE,第二四字节从30~39。
Unicode 字符集
Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。UNICODE字符集有多种编码方式,分别是UTF-8,UTF-16和UTF-32。
UTF-8
- 是针对Unicode的一种可变长度字符编码。
- 它可以用来表示Unicode标准中的任何字符,而且其编码中的第一个字节仍与ASCII相容,使得原来处理ASCII字符的软件无须或只进行少部份修改后,便可继续使用。
- UTF-8使用1~4字节为每个字符编码(ASCIl字符只需1字节编码, 拉丁文、希腊文等需要两个字节编码, 中日韩文字使用三字节编码, 其他极少使用的语言字符使用4字节编码号)
UTF-16
- 把Unicode字符集的抽象码位映射为16位长的整数(即码元)的序列,用于数据存储或传递。
- UTF-16比起UTF-8,好处在于大部分字符都以固定长度的字节 (2字节) 储存,但UTF-16却无法兼容于ASCII编码。
UTF-32
- 一种将Unicode字符编码的协定,对每一个Unicode码位使用恰好32位元,其它的 Unicode 编码方式则使用不定长度编码。
- 采用4字节编码,处理速度比较快,但是浪费空间,传输速度慢。
一个例子理解编码解码的庐山面目
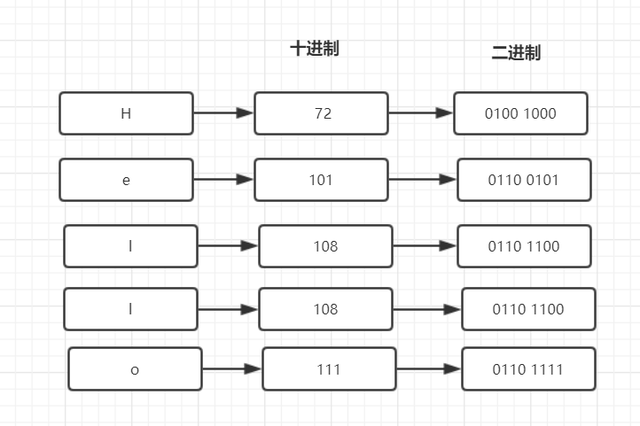
我们敲代码的程序员,接触最多的就是“hello word”。计算机只认识0和1,它是怎么展示hello word的呢?
上一小节,我们已经知道编码、字符集的知识。我们可以用ASCII编码,把“hello word”翻译成计算机认识的0、1。有兴趣的朋友可以去查一下 ASCII对照表
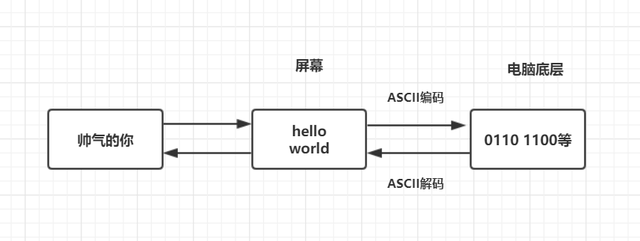
计算机存储的是hello world的0、1二进制码,先将二进制码解码成对应的字符,然后在屏幕上渲染出来,我们看到的就是hello world了
乱码如何产生的呢?
乱码产生的原因主要有两个,一是文本字符编码过程与解码过程使用了不同的编码方式,二是使用了缺少某种字体库的字符集引起的乱码。
编码与解码使用了不同的编码方式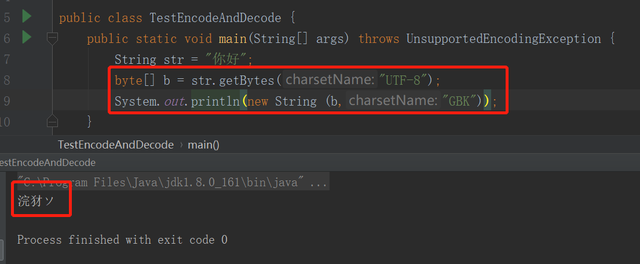
例子中,用了utf-8编码,使用了GBK解码,结果产生了乱码。因为在utf-8中,一个汉字用三个字节编码,而GBK中,每个汉字用两个字节表示,所以产生了乱码。
使用了缺少某种字体库的字符集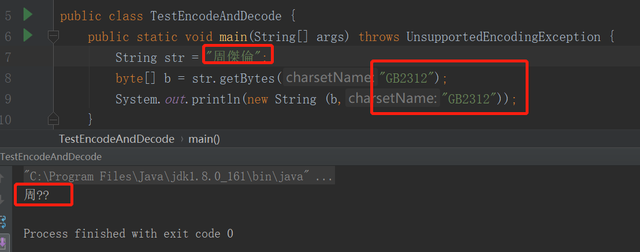
我们知道GB2312是不支持繁体字的,所以使用缺少某种字体库的字符集编码,会产生乱码。
乱码又如何解决呢
使用支持要展示字体的字符集编码,并且编解码使用同一种编码方式,就可以解决乱码问题了。
接下来列举一下乱码的经典场景与解决方案
IntelliJ Idea乱码问题
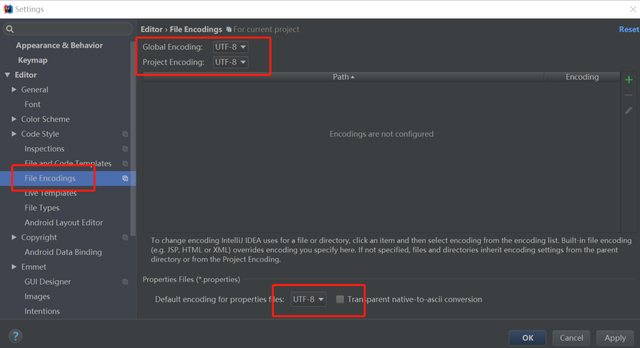
IDE项目中的中文乱码问题?File->settings->Editor->File Encodings,设置一下编码方式utf-8
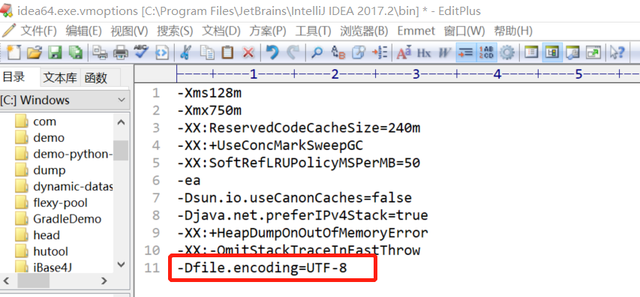
IDE控制台中文乱码?尝试一下这种方式,打开IDE安装目录,找到
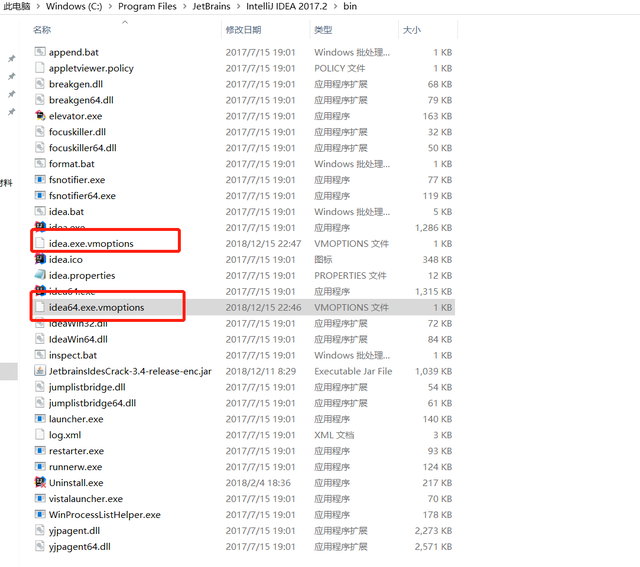
在文本末尾添加-Dfile.encoding=UTF-8
数据库乱码问题
查看数据库编码:
show variables like 'character_set%'复制代码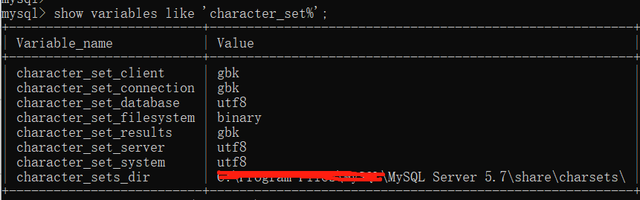
设置session、global范围的编码方式
//session 范围set character_set_server=utf8;set character_set_database=utf8;//global 范围set global character_set_database=utf8;set global character_set_server=utf8;复制代码
session、global范围编码,重启mysql可能编码又变回去了,可以尝试另外一种方式。在mysql(windows环境)的my.ini配置文件中修改或添加下列内容
[mysql]default-character-set=utf8 [mysqld]default-character-set=utf8 [client]default-character-set=utf8复制代码编码角度的乱码问题
写代码的时候出现中文乱码?追踪定位到编码解码的地方,设置用同一种编码方式。
写在最后
需更加深入学习java知识的小伙伴以及即将参加面试的小伙伴可以购买以下教程哦!