「最佳实践」机器学习的实践 - categorization
简介: 如果你有基于消息的日志条目,但是这些日志条目是机器生成的,则在将它们用于异常检测之前,首先需要将它们组织成类似的消息类型。 该过程称为分类 (cateogrization),Elastic ML 可以帮助完成该过程。Categorization 将结构引入半结构化数据,以便对其进行分析。这样做的好处就是在事先在并不知道 message 含有什么,就能找到日志里的异常。
简介:
如果你有基于消息的日志条目,但是这些日志条目是机器生成的,则在将它们用于异常检测之前,首先需要将它们组织成类似的消息类型。 该过程称为分类 (cateogrization),Elastic ML 可以帮助完成该过程。Categorization 将结构引入半结构化数据,以便对其进行分析。这样做的好处就是在事先在并不知道 message 含有什么,就能找到日志里的异常。
文本作者:刘晓国,Elastic 公司社区布道师。新加坡国立大学硕士,西北工业大学硕士,曾就职于新加坡科技,康柏电脑,通用汽车,爱立信,诺基亚,Linaro,Ubuntu,Vantiq 等企业。
如果你想一站式快速体验 Elasticsearch 所有功能(免费提供机器学习、 X-pack 能力),开通 阿里云 Elasticsearch 1核2G,即可首月免费试用。
可以供 categorization 的信息种类
在定义此处要考虑的基于消息的日志行的类型时,我们需要稍微严格一些。 我们不考虑的是完全自由格式的日志行/事件/文档,并且很可能是人工创建的结果(电子邮件,tweet,评论等)。 这类消息过于随意,其结构和内容也不尽相同。
相反,我们专注于机器生成的消息,当应用程序遇到不同的情况或异常时,这些消息显然会发出,从而将其构造和内容限制为相对离散的可能性集(请注意,消息的确可能存在某些可变方面) 。 例如,让我们看一下应用程序日志的以下几行:
18/05/2016 15:16:00 S ACME6 DB Not Updated [Master] Table 18/05/201615:16:00 S ACME6 REC Not INSERTED [DB TRAN] Table 18/05/2016 15:16:07 S ACME6 Using: 10.16.1.63!svc_prod#uid=demo;pwd=demo 18/05/2016 15:16:07 S ACME6 Opening Database = DRIVER={SQLServer};SERVER=10.16.1.63;network=dbmssocn;address=10.16.1.63,1433;DATABASE=svc_prod;uid=demo;pwd=demo;AnsiNPW=No 18/05/2016 15:16:29 S ACME6 DBMS ERROR : db=10.16.1.63!svc_prod#uid=demo;pwd=demo Err=-11 [Microsoft][ODBC SQL Server Driver][TCP/IP Sockets]General network error. Check your network documentation.
在这里,我们可以看到每种消息都有不同的文本,但是这里有一些结构。 在消息的日期/时间戳和服务器名称之后(此处为ACME6),有消息的实际内容,应用程序在此通知外部世界当时正在发生的事情-是否正在尝试某些操作或 发生错误。
Categorization 流程
为了能从无序日志文件中能侦测出有序的规律,Elastic ML 将采用通过使用字符串相似性聚类算法将相似消息分组在一起的技术。 该算法的启发式方法大致如下:
• 重点放在(英文)词典单词而不是可变单词上(也就是说,network 和 address 是词典单词,但是 dbmssocn 可能是可能更改的字符串 - mutable/variable string)
• 通过字符串相似性算法(与 Levenshtein 距离相似)传入不可变字典单词,以确定对数行与过去的对数行有多相似
• 如果当前日志行与现有类别之间的差异很小,则将现有日志行分组到该类别中
• 否则,为当前日志行创建一个新类别
作为一个简单的示例,请考虑以下三个消息:
Error writing file "foo" on host "acme6"Error writing file "bar" on host "acme5"Opening database on host "acme7"
该算法会将前两个消息归为同一类别,因为它们将被视为在消息类型上 Error writing file,而第三个消息将被赋予其自己的(新)类别。
这些类别的命名很简单:ML 只会将它们称为 mlcategory N,其中N是递增的整数。 因此,在此示例中,前两行将与 mlcategory 1 关联,第三行将与 mlcategory 2 关联。在现实的机器日志中,可能会生成数千(甚至数万)个类别 由于日志消息的多样性,但是可能类别的集合应该是有限的。 但是,如果类别的数量开始达到数十万,那么很显然,日志消息不是一组有限的消息类型,因此也不适合用于这种类型的分析。
它是如何工作的?
假如我们有一组如下的信息:

上面是一组 Linux 的日志信息。我们看看 categorization 是如何起作用的。
第一步,就是去掉那些 mutable 文字,也就是可以被修改的文字:

因为日期, IP地址和上面的被隐去的字段是会经常变化的。去掉它们就是上面的样子。
第二步,将相似的消息聚集在一起
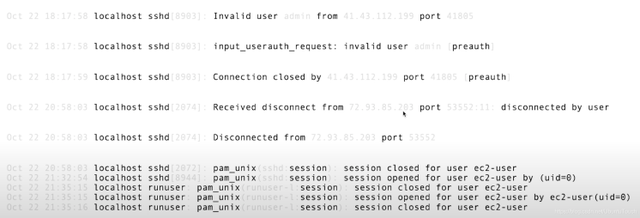
我们仔细查看一下,可以看出来如下的 category:
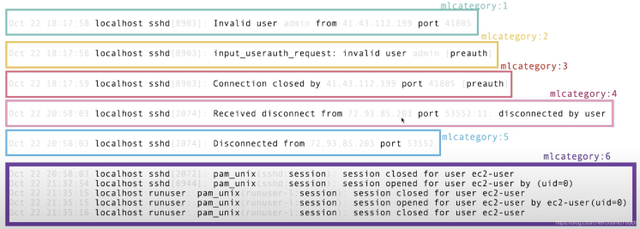
从上面我们可以看出来有6个不同 category。每个 category 的数据结构来说有很大的相似性。有的 category 里有一个文档,但是有的 category 里有很多的文档,比如 category 6。
第三步,对每个时间 bucket 进行统计

针对每个时间 bucket 进行事件数目的统计。我们可以通过 ML 来对这个计数进行异常分析。
动手实践导入实验数据
在接下来的实践中,我们想使用一个具体的例子来进行展示。你可以到如下的地址进行下载代码:
git clone https://github.com/liu-xiao-guo/ml_varlogsecure
我们下载上面的源码。我将使用 Filebeat 来把数据导入到 Elasticsearch 中:
filebeat_advanced.yml
filebeat.inputs:- type: log paths: - /Users/liuxg/data/ml_data/advanced/secure.log output.elasticsearch: hosts: ["http://localhost:9200"] index: varlogsecure pipeline: varlogsecure setup.ilm.enabled: falsesetup.template.name: varlogsecuresetup.template.pattern: varlogsecure
我们导入的索引的名字叫做 varlongsecure。记得修改上面的 secure.log 的路径。
secure.log 文件的事件内容如下:
Oct 22 15:02:19 localhost sshd[8860]: Received disconnect from 58.218.92.41 port 26062:11: [preauth]Oct 22 15:02:19 localhost sshd[8860]: Disconnected from 58.218.92.41 port 26062 [preauth]Oct 22 18:17:58 localhost sshd[8903]: reverse mapping checking getaddrinfo for host-41.43.112.199.tedata.net [41.43.112.199] failed - POSSIBLE BREAK-IN ATTEMPT!Oct 22 18:17:58 localhost sshd[8903]: Invalid user admin from 41.43.112.199 port 41805
在上面我们可以看出来,没有 year,信息。为了能够对这个信息进行处理,我们必须在 Elasticsearch 中运行 pipeline:
PUT /_ingest/pipeline/varlogsecure{ "processors": [ { "grok": { "field": "message", "patterns": [ "%{MONTH:month} %{MONTHDAY:day} %{TIME:time}" ] } }, { "set": { "field": "timestamp", "value": "2018 {{month}} {{day}} {{time}}" } }, { "date": { "field": "timestamp", "target_field": "@timestamp", "formats": [ "yyyy MMM dd HH:mm:ss" ] } }, { "remove": { "field": ["timestamp", "day", "time", "month"] } } ]}
在上面,我们定义了一个叫做 varlogsecure 的 pipeline。这个 pipleline 也在上面的 filebeat_advanced.yml 中引用。
我们可以启动 Filebeat 把数据导入到 Elasticsearch 中:
./filebeat -e -c filebeat_advanced.yml
运行完上面的 Filebeat 后,我们可以在 Elasticsearch 中找到最新生成的 varlogsecure 索引:
GET _cat/indices
我们接下来为 varlogsecure 创建一个 index pattern。这里就不再累述了。我们可以在 Discover 中看见:
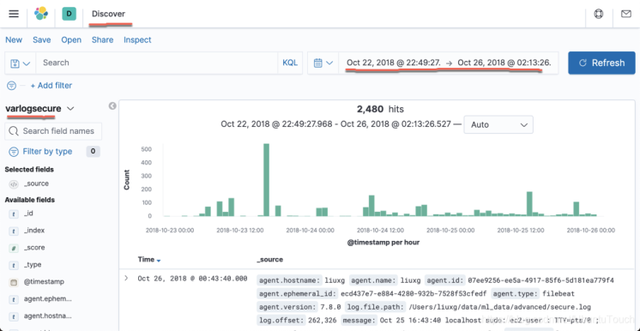
从上面我们可以看出来,我们的数据位于2018-10-22 日到2018-10-26之间。在上面我们可以看到一个叫做 message 的字段,它含有我们最原始信息的所有文字。这个 message 字段将在一下被用于 categorization。
机器学习 - categorization
选择机器学习应用:
点击 Manage jobs 或者 Create jobs (如果你从来还没有创建过机器学习作业)。
点击 Create job:
选择 varlogsecure 索引:
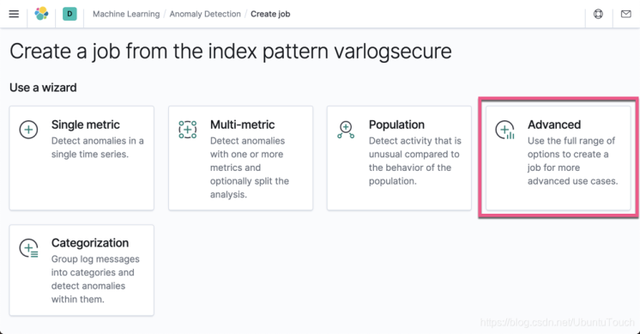
选择 Advanced:
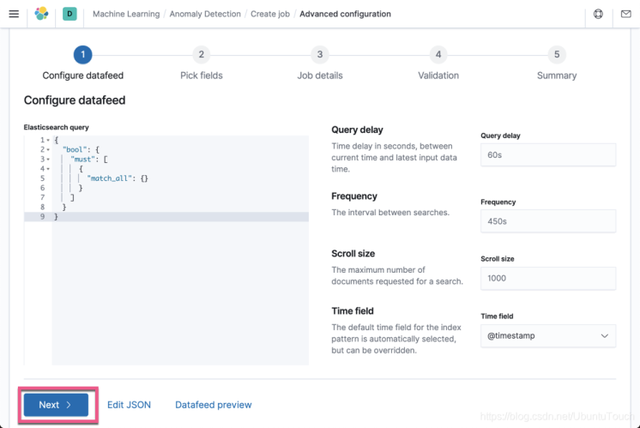
选择 Next:
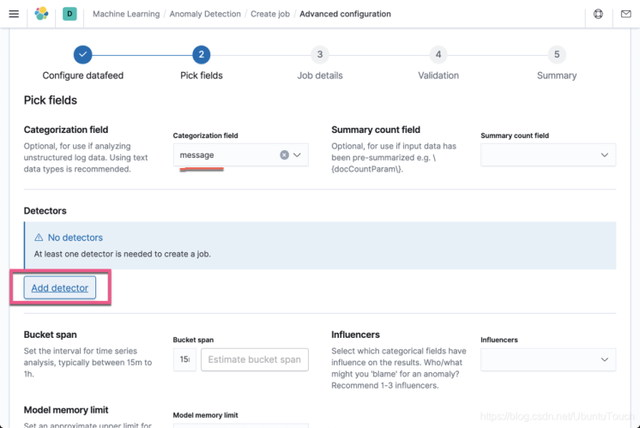
在 Categorization field 中,我们选择 message 字段。点击 Add detector:
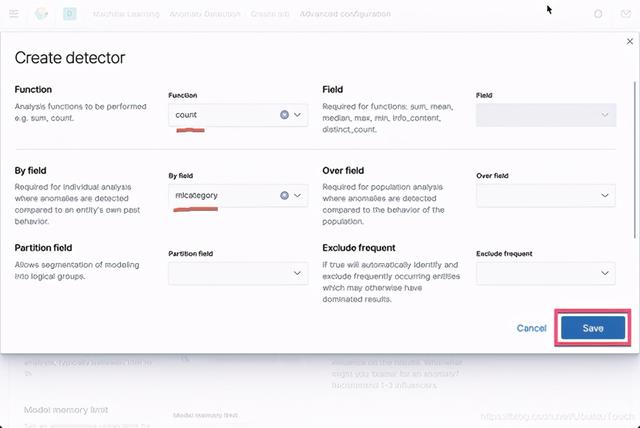
在上面 By field 里,我们选择 mlcategory。点击 Save 按钮:
点击 Next:
点击 Next 按钮:
点击 Next:
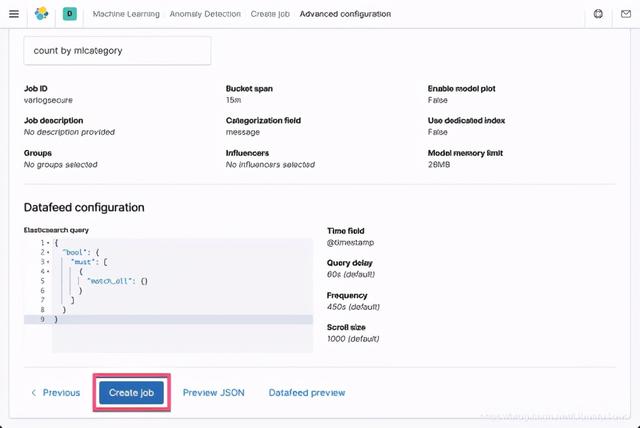
点击 Create job:
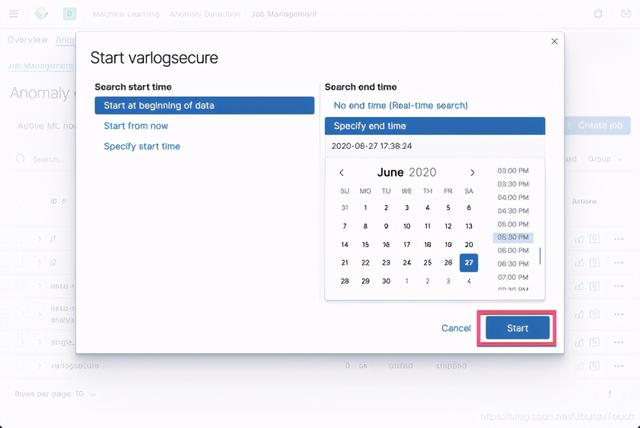
点击 Start:
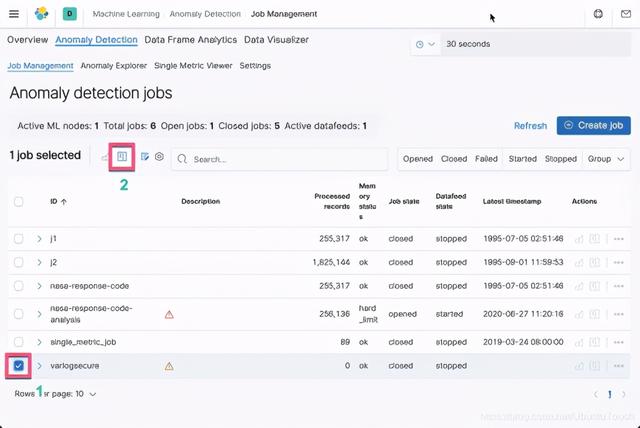
进入到 Anomly Explorer:
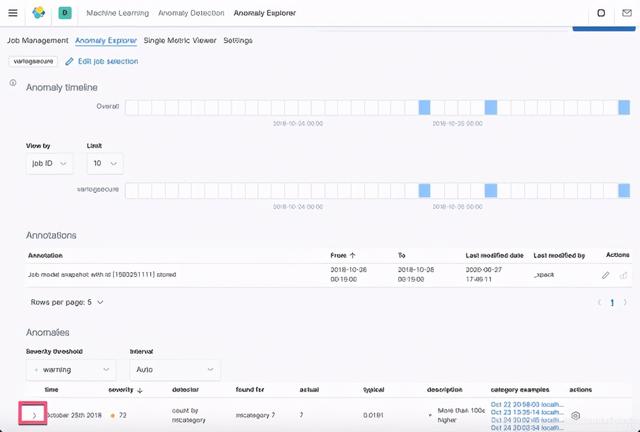
在这里,我们可以看到一些异常出现了。打开上面的 October 25th, 2018 这个异常事件:
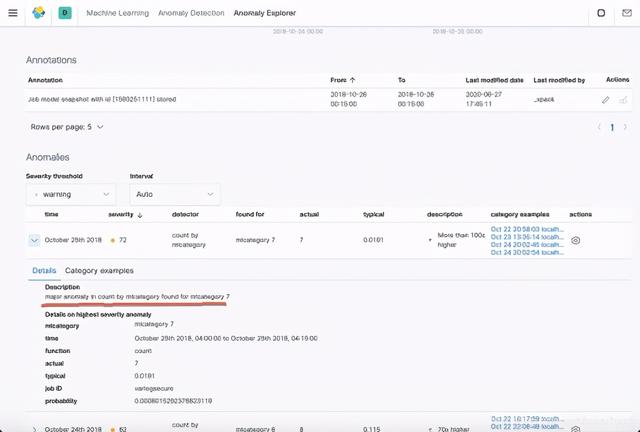
我们可以看到有一个是 mlcategory 7 的异常。它典型的值是0.00192,但是实际上它出现的事件总数是7 。属于一个不正常的事件。
总结
在今天的练习中,我们使用了 Elastic 的机器学习的 categorization 功能对我们的日志信息进行了分析。这个好处是我们不必事先对日志有任何了解的前提下,我们运行机器学习的功能对日志中的异常进行分析。
原文:https://developer.aliyun.com/article/778232?spm=a2c6h.12873581.0.0.7e9f767d4CcKTw&groupCode=othertech



















