第三章:文本信息抽取模型介绍——实体抽取方法:NER模型(下)
3.1.4 常用的实体抽取模型
Lattice LSTM
新加坡科技设计大学的研究者2018年在论文《Chinese NER Using Lattice LSTM》中提出了新型中文命名实体地识别方法Lattice LSTM。
作为信息抽取的一项基本任务,命名实体识别(NER)近年来一直受到研究人员的关注。该任务一直被作为序列标注问题来解决,其中实体边界和类别标签被联合预测。英文 NER 目前的最高水准是使用 LSTM-CRF 模型实现的,其中字符信息被整合到词表征中。
中文 NER 与分词相关。命名实体边界也是词边界。执行中文 NER 的一种直观方式是先执行分词,然后再应用词序列标注。然而,分割 → NER 流程可能会遇到误差传播的潜在问题,因为 NE 是分割中 OOV 的重要来源,并且分割错误的实体边界会导致 NER 错误。这个问题在开放领域可能会很严重,因为跨领域分词仍然是一个未解决的难题。已有研究表明,中文 NER 中,基于字符的方法表现要优于基于词的方法。
lattice LSTM算法原理:
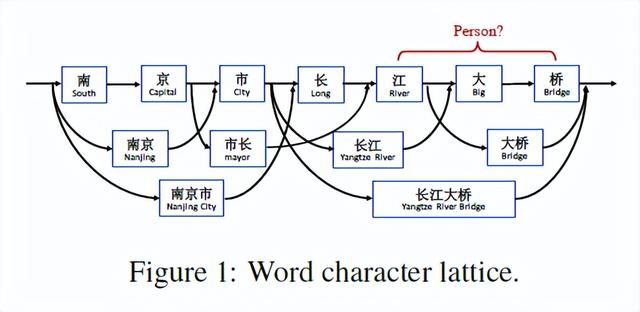
基于字符的 NER 的一个缺陷在于无法充分利用显性的词和词序信息,而它们是很有用的。为了解决这一问题,研究者利用 lattice LSTM 来表征句子中的 lexicon word,从而将潜在词信息整合到基于字符的 LSTM-CRF 中。如图 1 所示,研究者使用一个大型自动获取的词典来匹配句子,进而构建基于词的 lattice。因此,词序如「长江大桥」、「长江」和「大桥」之类的单词序列来消除上下文中潜在相关命名实体的歧义,如人名「江大桥」。
由于在网格中存在指数级数量的词-字符路径,因此研究者利用 lattice LSTM 结构自动控制从句子开头到结尾的信息流。如图 2 所示,门控单元用于将来自不同路径的信息动态传送到每个字符。在 NER 数据上训练后,lattice LSTM 能够学会从语境中自动找到更有用的词,以取得更好的 NER 性能。与基于字符和基于词的 NER 方法相比,lattice LSTM提出的模型的优势是具有利用显式单词信息进行字符序列标记的优势,而且不会出现分词错误。。

结果表明,lattice LSTM模型显著优于基于字符的序列标注模型和使用 LSTM-CRF 的基于词的序列标注模型,在不同领域的多个中文 NER 数据集上均获得最优结果。
算法模型:
研究者遵循最好的英文 NER 模型,使用 LSTM-CRF 作为主要网络结构。形式上,指定输入句子为 s = c1,c2,…, cm,其中 cj 指第 j 个字符。s 还可以作为词序列 s = w1,w2, …,wn,其中 wi 指句子中的第 i 个词,使用中文分词器获得。研究者使用 t(i, k) 来指句子第 i 个词中第 k 个字符的索引 j。以图 1 中的句子为例。如果分词是「南京市 长江大桥」,索引从 1 开始,则 t(2, 1) = 4 (长),t(1, 3) = 3 (市)。研究者使用 BIOES 标记规则进行基于词和基于字符的 NER 标记。
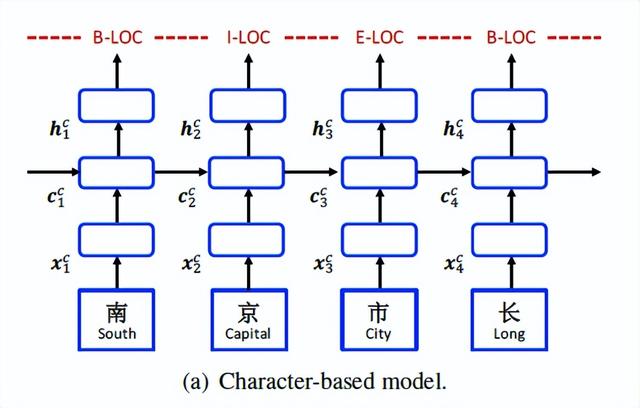
Character-Based Model:
在基于字符的模型中,使用LSTM-CRF对子序列c1,C2,…,cm建模,每个c j的表示为下:
![]()
ec表示字嵌入的查找表,即xc j;表示查找到的第j个字符的向量
双向的LSTM使用x1,x2,·.·,xm得到双向的隐藏状态,每个字的隐藏状态向量表示为:

标准CRF模型会使用 hc 1,hc 2,;...,hc m进行序列标注,得到对应的实体信息。
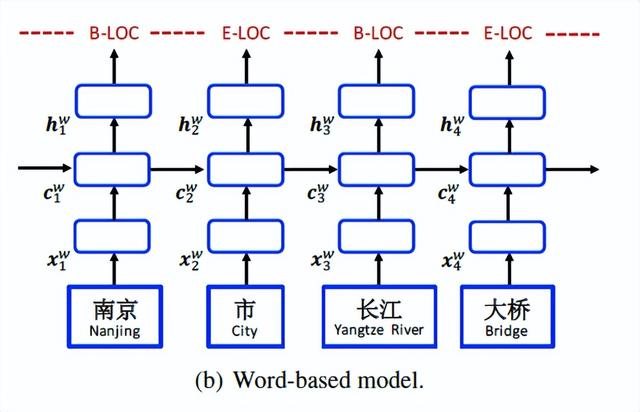
Word-Based Model:
基于词汇的模型如图(b)所示。它采用单词嵌入e w(w I )表示每个单词w I :
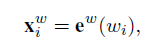
其中e w 表示单词嵌入查找表。
双向LSTM(等式11)用于获得单词w1,w2,…,wn的从左到右的隐藏状态序列和从右到左的隐藏状态序列。最后,对于每个单词,将其连接为其表示形式。将w i中的字符表示为xc i通过将ew(wi)和xc i串联得到新的单词表示:

Lattice model:
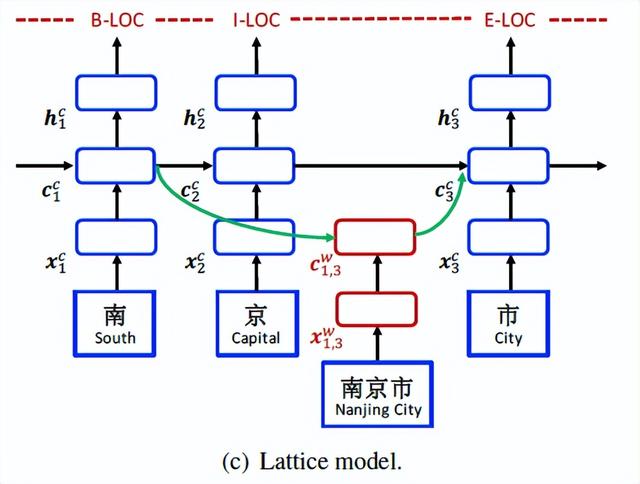
word-character lattice 模型的总体结构如图2所示。它可以看作是基于字符模型的扩展,集成了基于字符的单元和用于控制信息流的附加门。
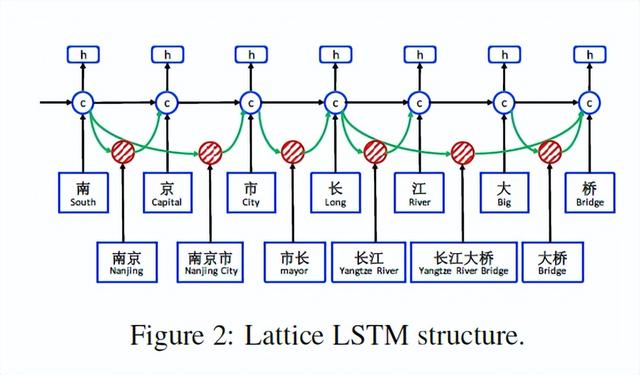
如图(c)所示,模型的输入是字符序列c1,c2,…,cm,以及匹配词典D中单词的所有字符子序列。如前文所示,模型使用自动分割的大型原始文本构建D。使用wd b,e表示以字符索引b开始,以字符索引e结束的子序列,即wd 1,2为“南京(Nanjing)”和wd 7,8是“大桥(Bridge)”。
该模型涉及四种类型的向量,即输入向量、输出隐藏向量、单元向量和门向量。作为基本组件,字符输入向量用于表示基于字符的模型中的每个字符c j:
![]()
与基于字符的模型不同,cc j的计算现在考虑了词典子序列句子中的wd b,e。特别地,每个子序列w d b,e表示为:
![]()
此外,从句首开始加入word cell cw b,e用于表示xw b,e的循环状态。带有cw b,e,信息流入每个cc j有更多的循环路径。例如,在图2中,cc 7的输入源包括xc 7(桥 Bridge)、cw 6,7(大桥 Bridge)和cw 4,7(长江大桥 Yangtze River Bridge)。最终隐藏向量hc j仍按基本recurrent LSTM函数计算。
解码:
解码部分使用的是标准的CRF层。使用一阶Viterbi算法在基于单词或基于字符的输入序列上找到得分最高的标签序列。
实验结果:
在Lattice LSTM论文中,总共选取了四个数据集作为实验数据。分别是:OntoNotes 4 、MSRA 、Weibo NER 以及研究者自行标注的中文数据集。
得到了如下4个表所示的实验结果。
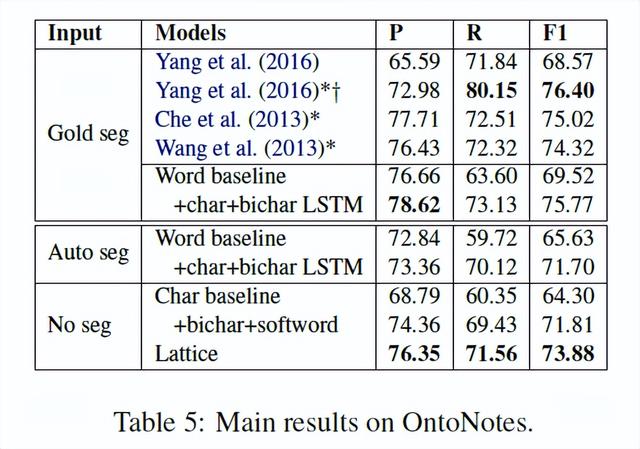
OntoNotes测试结果如表5所示。通过黄金比例分割,Lattice LSTM基于单词的方法在双语数据集上得到了与最先进的方法(Che et al.,2013《Named entity recognition with bilingual constraints.》;Wang et al.,2013《Effective bilingual constraints for semi-supervised learning of named entity recognizers.》)有竞争力的结果。这表明,与其他语言一样,LSTM-CRF是基于单词的中文NER的竞争选择。此外,结果表明,Lattice LSTM基于word的模型可以作为具有高度竞争力的基线。在自动切分的情况下,word+char+bichar LSTM的F1得分从75.77%下降到71.70%,显示了切分对NER的影响。与开发集上的观察结果一致,添加Lattice信息会达到88.81%!F1成绩比character baseline从88.81%提高到93.18%!添加bichar+softword,会提高到91.87%。Lattice LSTM模型在自动分割方面也得到了最好的F1-score。
MSRA数据集的结果如表6所示。对于这个基准测试,测试集上没有可用的goldstandard分段。Lattice LSTM选择的分割器在5倍交叉验证训练集上的准确率为95.93%。数据集上的最佳统计模型利用了丰富的手工特征和字符嵌入特征(Lu et al.,2016《Multi-prototype Chinese character embedding.》)。Dong等人(《Character-based LSTM-CRF with radical-level features for Chinese named entity recognition.》)开发了具有激进特征的神经LSTM-CRF。与现有的方法相比,Lattice LSTM的基于单词和基于字符的LSTM-CRF模型具有较高的精度。lattice模型显著优于基于字符和基于单词的最佳模型(p<0:01),在这个标准基准上取得了最好的结果

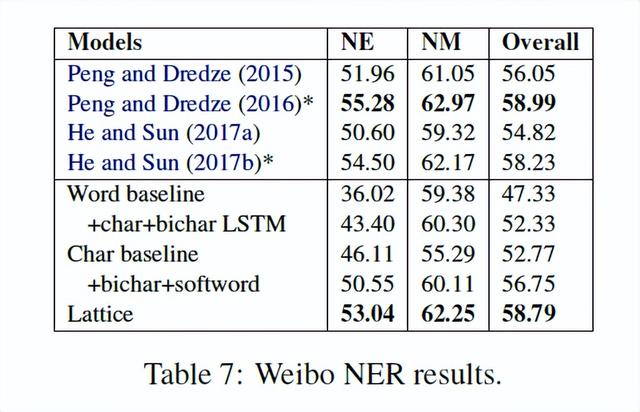
微博NER数据集的结果如表7所示,其中NE、NM和OVERALL分别表示命名实体、标称实体(不包括命名实体)和两者的F1分数。此数据集没有黄金标准分段。现有最先进的方法包括Peng和Dredze(《Improving named entity recognition for Chinese social media with word segmentation representation learning.》)以及He和Sun(《A unified model for cross-domain and semi-supervised named entity recognition in Chinese social media.》),他们探索了丰富的嵌入特征、跨域和半监督数据。
中文标注数据集NER测试数据的结果如表8所示。与OntoNotes和MSRA上的观察结果一致,lattice模型在微博和简历上的表现明显优于基于单词的模式和基于字符的模式(p<0:01),提供了最先进的结果。

结论:
总的来说,这篇论文是在中文NER领域引入词汇信息,改善了之前仅利用字符来做NER的情况,这也是中文本身的特点,仅仅按字符来划分丢失了太多语境。作为中文NER领域引入词汇信息的开山之作,其对后续研究工作有较深的影响。
CAN-NER
2019年论文《CAN-NER: Convolutional Attention Network for Chinese Named Entity Recognition》提出了用基于注意力机制的卷积神经网络架构。
采用一种卷积注意网络CAN,它由具有局部attention的基于字符的CNN和具有全局attention的GRU组成,用于获取从局部的相邻字符和全局的句子上下文中信息,增强了模型隐式捕捉字符序列间局部上下文关系的能力。首先模型输入的是字符,卷积注意力层用来编码输入的字符序列并隐式地对局部语义相关的字符进行分组。对输入进行向量嵌入,包含字向量、分词向量和位置向量,得到输入向量后,采用局部 local attention来捕捉窗口范围内中心词和周围词的依赖,局部 attention 的输出被送到 CNN 中,最后采用加和池化方案。得到局部特征后,进入到BiGRU-CRF 中,而后采用全局的 attention来进一步捕捉句子级别的全局信息。后面接 CRF,得到分类结果。self-attention 可以捕捉广义的上下文信息,减少无用中间词的干扰。
CAN-NER算法原理:

CAN-NER模型使用BiGRU-CRF作为基本模型结构,其完整模型结构为:Embedding+ Convolution Attention + GRU + Global Attention + CRF
Convolution Attention层:卷积注意层的目的是对输入字符序列进行编码,并在本地上下文中隐式分组与意义相关的字符。
Global Attention:捕获长序列句子级别的关系
首先模型输入的是字符,卷积注意力层用来编码输入的字符序列并隐式地对局部语义相关的字符进行分组。输入用x=[xch; xseg]表示,其中 xch代表word2vec的词向量, xseg表示分词信息。
对输入进行向量嵌入,包含字向量、分词向量和位置向量,de=dch+dpos +dseg 得到输入向量后,在窗口内应用局部 attention来捕获中心字符和每个上下文标记之间的关系,然后加上带有加和池化层的CNN。将隐藏维度设置为dh 。
在通过卷积注意层提取局部上下文特征后,将其输入到基于BiGRU-CRF的模型中,以预测每个字符的最终标签。该层对顺序句子信息进行建模。而后采用全局的 attention来进一步捕捉句子级别的全局信息。最后,在BiGRU和global attention层输出的串联顶部使用标准CRF层。在解码时,模型使用Viterbi算法来获得预测的标签序列。
实验结果:
实验中使用了四个数据集。对于新闻领域,CAN-NER在OntoNotes 和SIGHAN Bakeoff 2006 的MSRA NER数据集上进行了实验。对于社交媒体领域,CAN-NER采用了与PENG和Dredze (2015)的注释微博语料库,该语料库摘自新浪微博。为了让测试领域更加多样化,CAN-NER还使用了从新浪财经收集的中文注释数据集。
下表是各数据集的统计情况:

下表是CAN-NER在Weibo NER数据集上的实验结果。在这里,实验将CAN-NER的模型与微博数据集上的最新模型进行比较。表2显示了命名实体(NE)、标称实体(NM,不包括命名实体)和两者(总体)的F1分数。可以观察到,实验提出的模型达到了最先进的性能。

先进的方法包括Peng and Dredze (2016《Improving named entity recognition for chinese social media with word segmentation representation learning.》)、He and Sun (2017b《A unified model for cross-domain and semi-supervised named entity recognition in Chinese social media.》)、Cao et al. (2018《Adversarial transfer learning for Chinese named entity recognition with self-attention mechanism.》)以及Zhang and Yang (2018《Chinese ner using lattice lstm》),它们利用了丰富的外部数据,如跨域数据、半监督数据和词典,或联合训练NER和中文分词(CWS)。在表2的第一部分,实验报告了最新模型的性能。Peng and Dredze (2015《Named entity recognition for chinese social media with jointly trained embeddings.》)提出了一种与NER联合训练嵌入的模型,该模型的总体性能F1得分为56.05%。联合训练NER和CWS的模型(Peng和Dredze,2016)F1得分达到58.99%。He和Sun(2017b)提出了一种利用跨域和半监督数据的统一模型,与He和Sun(2017a)提出的模型相比,F1得分从54.82%提高到58.23%。Cao等人(2018年)使用对抗性迁移学习框架整合CWS中的任务共享单词边界信息,F1得分为58.70%。Zhang和Yang(2018)利用晶格结构将词典信息集成到他们的模型中,F1得分为58.79%。
在表2的第二部分中,实验给出了Baseline和CAN-NER模型的结果。虽然BiGRU+CRF基线只获得了53.80%的F1分数,但添加一个正常的CNN层作为特征化器将分数提高到55.91%。用CAN-NER的卷积注意层取代CNN,F1得分大大提高到59.31%,优于其他模型。改进证明了CAN-NER的模型的有效性。
中文标注数据集测试结果如表3所示。Zhang和Yang(2018)发布了中文标注数据集,他们的F1得分为94.46%。可以看出,实验提出的Baseline(CNN+BiGRU+CRF)优于Zhang和Yang(2018),F1得分为94.60%。添加CAN-NER的卷积注意力会导致进一步的改进,并达到最先进的F1分数94.94%,这进一步证明了CAN-NER的模型的有效性。
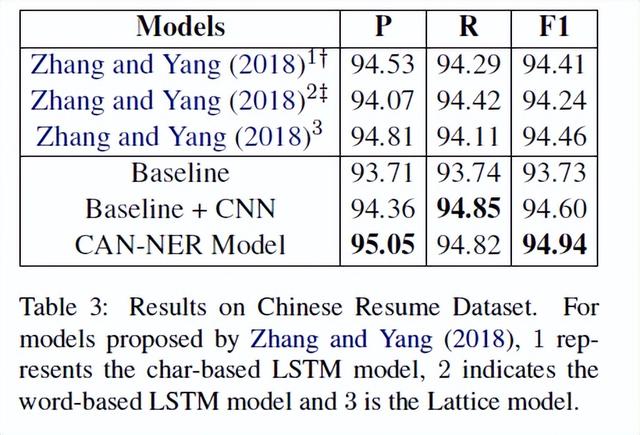
表4显示了在OntoNotes 4数据集的比较。表中的第一块列出了中文NER以前方法的性能。Yang et al.(2016《Combining discrete and neural features for sequence labeling》)提出了一种神经和离散特征相结合的模型,例如词性标注特征、CWS特征和正交特征,将F1得分从68.57%提高到76.40%。利用双语数据,Che et al.(2013《Named entity recognition with bilingual constraints.》)和Wang et al.(2013《Effective bilingual constraints for semi-supervised learning of named entity recognizers.》)的F1成绩分别为74.32%和73.88%。Zhang and Yang(2018)是一个新的模型,它使用了基于角色的模型,并使用了bichar和softword。
表4的第二部分显示了Baseline和CAN-NER模型的结果。与微博和中文标注数据集上的观察结果一致, CAN-NER卷积注意力层导致F1分数大幅增加。CAN-NER的模型在不使用外部数据的情况下,在基于字符的模型中,F1得分达到73.64%(例如,Zhang和Yang(2018))。

表5显示了MSRA 2006数据集的实验结果。Chen et al.(2006)、Zhang et al.(2006)和Zhou et al.(2013)利用丰富的手工特征,Lu et al.(2016)利用多原型嵌入特征。Dong等人(2016)将字根特征引入LSTM-CRF。Cao等人(2018年)利用对抗性迁移学习和global self-attention来提高模型性能。Yang等人(2018a)提出了一种基于字符的CNN BiLSTM CRF模型,以结合笔划嵌入并生成n-gram特征。Zhang和Yang(2018)引入了一种晶格结构,将词典信息纳入神经网络,神经网络实际上包含单词嵌入信息。虽然该模型达到了最先进的F1分数93.18%,但它利用了外部词典数据,因此结果取决于词典的质量。在表格的底部,可以看到Baseline+CNN已经优于以前的大多数方法。与Zhang和Yang(2018)相比,CAN-NER的基于字符的方法在没有任何额外的词典数据和单词嵌入信息的情况下获得了92.97%的F1分数。此外,CAN-NER模型在基于角色的模型中取得了最先进的结果。

实验结果分析:
CAN-NER的模型优于之前在Weibo和自行标注的数据集上的研究,在不使用任何外部资源的情况下,在MSRA和OntoNotes 4数据集上都取得了有竞争力的结果。实验结果证明了CAN-NER的有效性,尤其是在基于字符的模型中。添加卷积注意层和全局注意层后的性能改进验证了CAN-NER能够捕捉角色与其局部上下文之间的关系,以及单词与全局上下文之间的关系。然而,尽管CAN-NER可以获得与不使用外部资源的其他模型相当或更好的结果,但实验发现CAN-NER在OntoNotes 4数据集上的模型性能仍有改进的余地(与利用额外数据的最佳模型相比,F1分数差距为2.76%)。这可能是因为特定的离散特征和外部资源(例如,其他标记数据或词汇)对该特定数据集具有更积极的影响,而CAN-NER无法仅从训练集中学习足够的信息。但研究员无法根据可用的相应资源确定造成差距的确切原因。
结论:
CAN-NER提出了一种卷积注意网络模型,以提高中文NER的性能,避免单词嵌入和额外的词汇依赖;从而使模型更加高效和健壮。在CAN-NER中,模型实现了具有global self-attention结构的local-attention CNN和Bi-GRU,用字符级特征捕获单词级特征和上下文信息。大量实验表明,在不同领域的数据集上,CAN-NER优于最先进的系统。
参考文献:
Jing Li, Aixin Sun, Jianglei Han, and Chenliang Li,“A Survey on Deep Learning for Named Entity Recognition,” IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, 2020
Yuying Zhu,Guoxin Wang,“CAN-NER: Convolutional Attention Network for Chinese Named Entity Recognition”,Proceedings of NAACL-HLT 2019, pages 3384–3393
Yue Zhang,Jie Yang,“Chinese ner using lattice lstm” In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, volume 1, pages 1554–1564.





















评论