WAIC 2023 | 新加坡国立大学尤洋教授 :AI大模型的挑战与系统优化
机器之心报道
演讲:尤洋
编辑:微胖
在 WAIC 2023 AI 开发者论坛上,新加坡国立大学校长青年教授、潞晨科技创始人兼董事长尤洋发表了主题演讲 《Colossal-AI:AI 大模型的挑战与系统优化》。演讲中,尤洋首先介绍了大模型「巨人症」问题所在以及开源软件 Colossal-AI 社区目前发展情况。接下来,尤洋介绍了 Colossal-AI 背后的一些技术细节,主要是训练大模型的并行系统以及内存优化方面的努力。最后展示了 Colossal-AI 在产业应用上取得的成果。
以下为尤洋在 WAIC 2023 AI 开发者论坛上的演讲内容,机器之心进行了不改变原意的编辑、整理:
今天的演讲主要介绍我们公司做的开源软件 Colossal-AI 的一些技术原理和应用。
首先简单介绍一下我本人。我在加州大学伯克利分校获得博士学位,现在在新加坡国立大学任教,同时创立了潞晨科技。公司另外一位核心成员 James Demmel 教授是美国科学院工程院院士,也是加州大学伯克利分校前计算机系主任兼院长。
今天的演讲分四个部分。第一部分简单介绍大模型的挑战以及目前 Colossal-AI 社区的发展情况,接下来两个部分介绍一些技术细节,最后一部分介绍具体应用上的效果。
首先给大家展示一张图:横坐标是时间,纵坐标是 AI 模型的参数量。过去六年中,最好的 AI 模型参数量已经上升了 1 万倍左右。
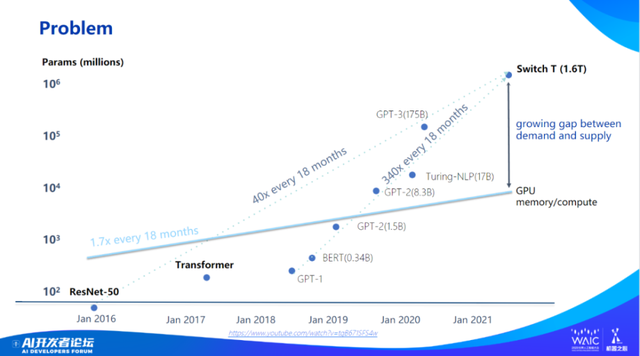
比如,2016 年 ResNet-50 只有 2000 万参数,2020 年 GPT-3 已经达到 1750 亿参数的规模。据说 GPT-4 也是用的混合专家系统,跟谷歌 Switch Transformer、智源的「悟道」都是同一种技术。Switch Transformer 参数规模大概 1.6 万亿,据说 GPT-4 有 16 个专家(模型),每个专家(模型)有千亿左右(参数)。
所以说,过去六、七年 —— 从 ResNet-50 到 GPT-4—— 最好模型的参数量刚好大了 10 万倍左右。
但是,以 GPT-3 为例,模型构造没有到 100 层,ResNet-50 也是 50 层左右,层数基本上没变化,模型不是变得更深而是变得更宽,大了 1-10 万倍左右,也给 GPU 内存造成更大压力,但 GPU 内存每 18 月只增长 1.7 倍,这就需要对下一代人工智能基础设施进行优化或者重建。
所以,我们打造了 Colossal-AI 系统。这是 Colossal-AI 系统结构图,包括三个层次。
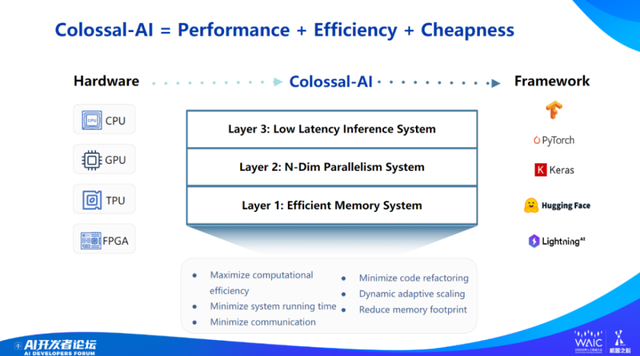
第一个层次是内存管理系统,因为大模型太吃内存。
第二部分是 N-Dim 并行技术(N 维并行技术)。据说 OpenAI 已经用 10 万张 GPU 卡训练大模型。前两天一家美国创业公司融资了 13 亿美金,背后基础设施据说已经有 2 万张 GPU 卡。未来,从 1 个 GPU 到 10、100、10000 个 GPU ,自动扩展效率会对训练系统产生根本性影响,所以我们打造了 N 维并行系统。
第三部分是低延迟的推理系统,也是目前 Colossal-AI 的主要模块。模型训练好后要服务用户,用户每调用一次模型就是做一次推理,这跟成本有直接关系。所以,推理的延迟要很低,成本要降到最低。
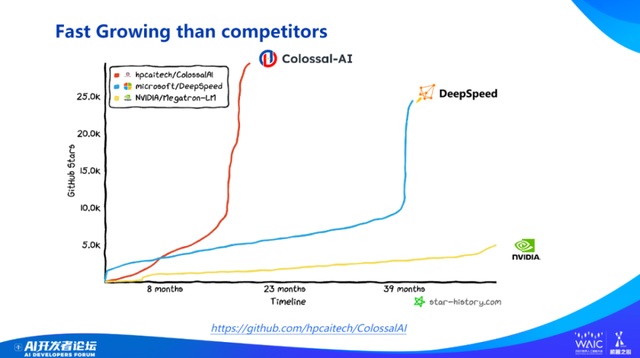
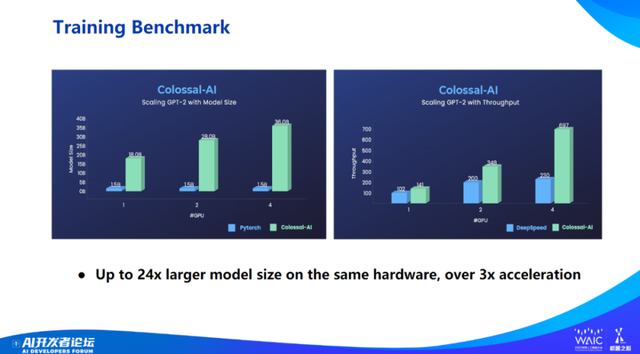
虽然 Colossal-AI 开源社区只推出了 20 个月左右,但发展速度非常快。(下图)横坐标是时间,纵坐标是 GitHub 上的星数,可以看出 Colossal-AI 增长速度远超于传统开源软件。
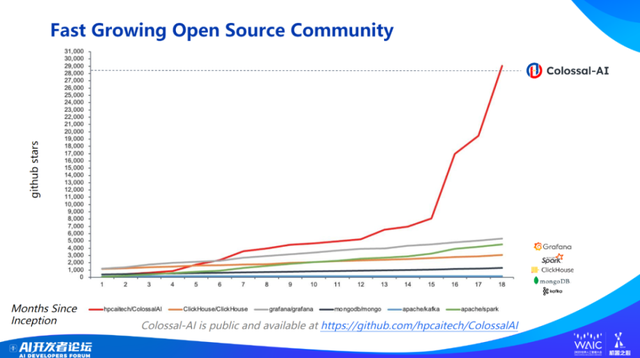
Colossal-AI 增速也远超与 Colossal-AI 类似软件,比如 DeepSpeed。
目前 Colossal-AI 用户遍布全球。中国、美国、欧洲、印度、东南亚都有很多用户。在全球 AI 生态系统中也都发挥了更重要的作用。
目前世界公认的第一大 AI 生态是 PyTorch ,它的生态图中有一个链接指向了 Colossal-AI。Lightning AI 是 PyTorch 第一大子生态,直接依赖于 Colossal-AI。

HuggingFace 世界公认的第二大 AI 生态,很多应用也是基于 Colossal-AI 做的。
现在开源生态做的最好的是 PyTorch 也由 Facebook 主导,我们的开源大模型很多基于 Facebook 的 LLaMA。
OPT 也是 Facebook 的一个很重要模型。OPT 官网截图显示,它也有一个链接指向了 Colossal-AI,OPT 用户也可以通过 Colossal-AI 进行优化。

第二部分讲一下技术细节。假设未来需要用 1 万或者 10 万张 GPU 卡训练大模型,怎么充分利用这些 GPU 卡呢?与二十年前相比,今天特别是下层系统软件面临的问题有很大不同。
20 年前,英特尔芯片快了 3 倍,因为都是串行代码,一行代码都不用改就可以直接快 3 倍。但在今天,提升算力主要靠并行计算,不管是单个 GPU 内的多线程还是多个 GPU,甚至于两三周之前英伟达 CEO 黄仁勋在演讲中说到,要把成百上千个 GPU 用高速网络连接在一起(现在已经是这样的状况了)。如何最大化算法或者说上层应用并行度,将对机器的性能发挥产生非常实质性影响。在同样条件下,好的分布式软件导致速度上出现 5-10 倍的差距也很正常,所以,并行系统非常重要。
目前,训练 AI 大模型的并行系统主要有三个。最开始也是黄仁勋在 GTC 中介绍的,包括数据并行、模型并行和流水线并行。
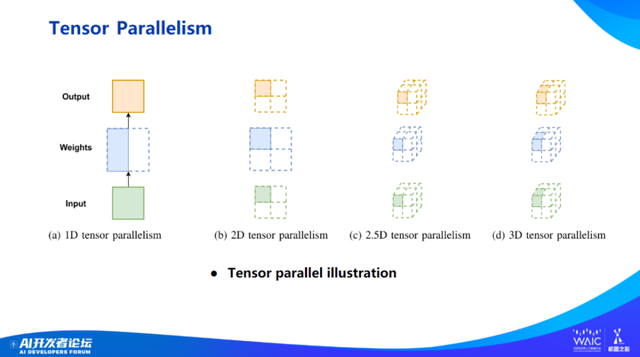
模型并行是指层内并行。刚才也说了,现在处在宽度学习时代,而不是深度学习时代。从 ResNet-50 到 GPT-3,层的数量基本没有变化,但参数量大了 1 万倍,变宽了很多。在层的宽度越来越大、每层计算量越来越大的情况下,张量并行有可能发挥更加重要的作用。
当然,张量并行最大的弊端是它的通信开销太大,这也是黄仁勋在 2021 年演讲里提到把所有张量并行都放在服务器内的原因,跨服务器的通信开销太大,得不偿失。所以,如何优化张量并行的通信就非常重要。我们又打造了二维张量并行、三维张量并行、2.5 倍张量并行,去最小化数据移动。

另一个是数据序列并行。我们前段时间看到一些工作,看能不能把 sequence 增长到 4K 的量级。比如对 ChatGPT 应用而言,sequence 越长,一定概率上,预测效果也会更好,因为上下文得到了更多信息。但是,Transformer 的架构决定了每个 token 都需要跟其他的 token 算 Attention score,内存开销非常大。数据序列并行主要优化的也是 sequence 划分之后,如何尽量减少它们的数据移动。
当然,最传统的还是数据并行。我会一一介绍这三种并行系统。
先介绍一下最简单的数据并行。最开始我们训练 ResNet、AlexNet 甚至 BERT,很大程度上可以把模型下放到单个芯片,只要单个芯片能把模型放下去,芯片和芯片之间做数据并行就可以了。
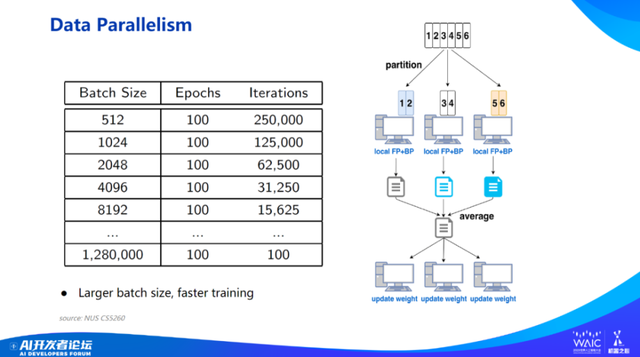
比如,将一堆数据分 10 份,每个 GPU 放十分之一。这样情况下,工作就很理想了 —— 只需要增大 batch size 10 倍,假定能把循环次数减少 10 倍,这样 batch size 线性增大、循环次数线性减少就变成了一个很理想的扩展性问题,这样我们可以保持 Epoch 不变,但总体运行时间显著减少。
数据并行的通信,其实就是每次循环的时候大概需要交换一下梯度就可以了。当然,梯度大小和参数大小是一样的,对传统 CNN 而言,它们参数也不太多,所以,通信也非常友好,数据并行之前也是最常用的一种方式。
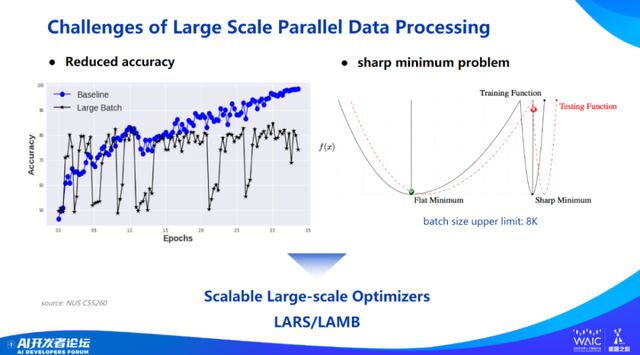
但是,大模型时代面临的问题是循环次数逐渐减少情况下,收敛变得越来越困难 —— 假如之前用 1 万次循环做收敛,batch size 增加 10 倍就需要在 1000 次循环中完成收敛。所以,数据并行的难度在于它的 accuracy 有时候会掉很多。因此需要看能不能设计出更好的优化方法,去解决这个问题。
我们团队打造了 LARS 和 LAMB 的方法,也发表在 ICLR 论文上,现在引用次数也快 700 次。最近,我们基于 LAMB 方法做了另外的工作,今年年初也获得了 ACL 杰出论文,另一篇获得 AAAI 2023 杰出论文。其实都是基于这个工作线,优化训练的收敛性和效率。
包括谷歌,Facebook SEER,Deepmind BYOL 等使用了 LARS 和 LAMB 方法。我们也帮助谷歌把 BERT 训练时间从三天缩减到 76 分钟。

说完数据并行,再说一下模型并行。模型并行就像盖楼 —— 要盖一个很宽的楼,每层 1 万平,直接用 10 个工程队把它分成 10 份,每个工程队一份,同步盖完一层后,再盖下一层。所以,层内并行的问题是通信开销太大。
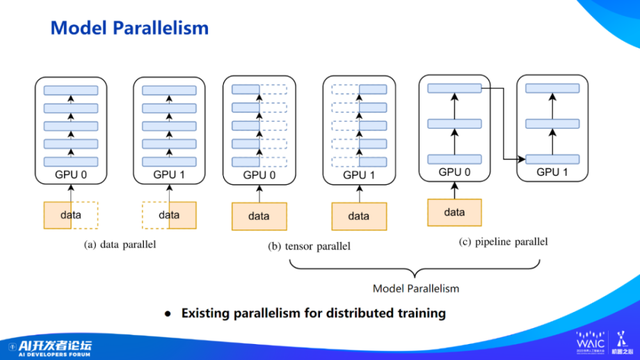
第三个是流水线并行。并行的字面意思可以理解为,算完这一层算下一层,第 N 层要依赖于第 N-1 层的结果,第 N+1 层也要依赖于第 N 层的结果,前后依赖。比如,现在要盖 1000 栋楼,有 20 个工程队。第一个工程队先盖第一栋楼第一层,盖好之后,第二个工程队才能入场盖第二层。这时,第一个工程队移步第二栋楼,开始盖第一层,直到盖完 20 栋楼的第一层时,所有 20 个工程队才能都进入施工现场。
流水线并行的层数和 GPU 数量之间关系,就像工程队数量(类似 GPU 数量)与楼层数(相当于流水线并行的层数)关系一样密切。数据流水线数和 GPU 之间比值越大,并行效率越高。20 个工程队盖 1000 栋楼,很多时候并行度可以达到 20,但用 20 个工程队去盖 30 栋楼,效率就不是很高。所以,流水线并行本质上还是需要将 batch size 扩得很大,因为不同流水线进行了不同计算,本质上它的并行也来源于数据并行。
这是三种传统并行方式。GPT-3 刚出来的时候,OpenAI 用了 1 万个 GPU 训练 GPT-3,但是英伟达优化之后发现 3072 个 GPU 就够:把 64 个服务器分成一组,每个服务器内有 8 个 GPU,8 个 GPU 做张量并行。64 个服务器之间就做流水线并行,每个组有 64 个服务器,组之间再做数据并行,因为流水线并行的传输代价非常小,只传层和层之间的信息。
我们之前的工作做了很多张量并行的优化。张量并行未来发展空间也是最大的,因为模型的层变得更宽,通信开销也非常高昂。而二维张量并行、三维张量并行的核心思想是用更多的局部序列化替换全局序列化 ,用更多局部通信换取全局通信,从而降低通信成本,提高效率。
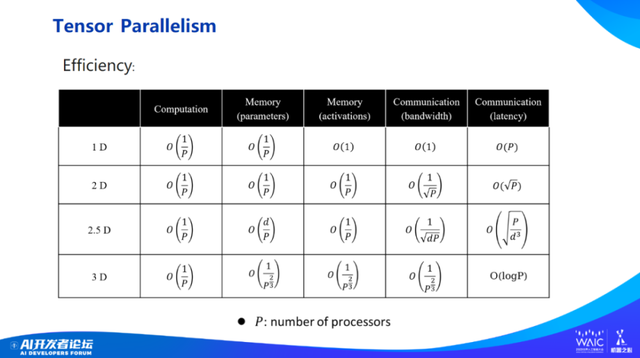
这几种张量并行方式的训练效率差异非常大,特别是二维和三维张量并行。可以看一下最后两列(最右侧两列):第一个是通信带宽上的代价,第二个是通信延迟的代价。二维、三维、2.5 维张量并行可以大幅度降低通信和内存开销。
数据序列并行非常重要。前段时间有一个美国创业公司发了一个大新闻,可以把单次数据序列的 input sequence length (输入序列长度) 做到 4K Token。这个事情很重要,这张图可以说明一些问题:
横坐标反映数据序列长度,纵坐标预测下一个词的精度 —— 数据序列越长我们预测的越准确,因为它有更多的上下文信息。
虽然不好的地方在于计算变得更加复杂,但长的 Sequences 是算法侧需求,下层的基础设施也应该尽可能去满足。
这两天我又看到一篇论文,有团队声称把数据序列甚至能做到 100 万(当然需要再求证)。数据序列变长的需求还是会长期存在,越长确实效果就越好。

这张图展示的是为什么变长之后,给下层实现、基础设施带来很多麻烦。
现在基于 Transformer 的架构,每个 Sequence 都有很多 token,每两个 token 之间都需要算 Attention score,导致内存开销非常大,特别是 Sequence 长度到一定级别后,内存开销会指数级上涨。

Transformer 结构内存压力本来很大。比如训练 GPT-3 ,如果按照 2000 亿参数量计算,假设用单精度,每个参数要占 4 个字节,仅参数就要占 800G 内存,梯度要占 800G 内存,等等。何况 Transformer Attention score 等更是指数级上升,内存压力非常大。因此,如果数据序列想变得更长,就需要并行,把不同 Token 划分到不同的 GPU 上。
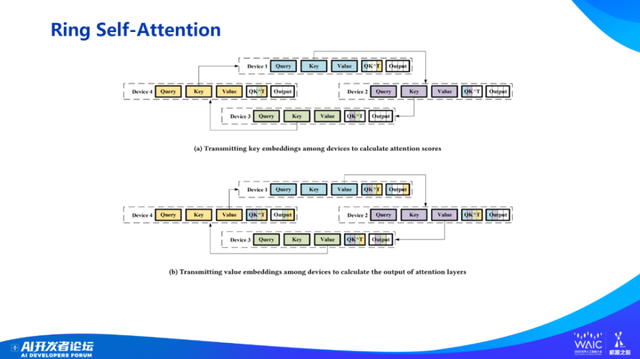
另一个问题是如何减少 GPU 之间的数据移动。100 个 GPU,所有都需要跟其他 GPU 交换数据,这是 Transformer 的 Attention 机制决定的。我们打造了环状 self-attention 通信算法,尽量减少数据之间移动,每次循环只需要跟左右邻居打交道,把通信复杂度从 P 平方降低到 P-1(P,指 GPU 数量或服务器数量)。
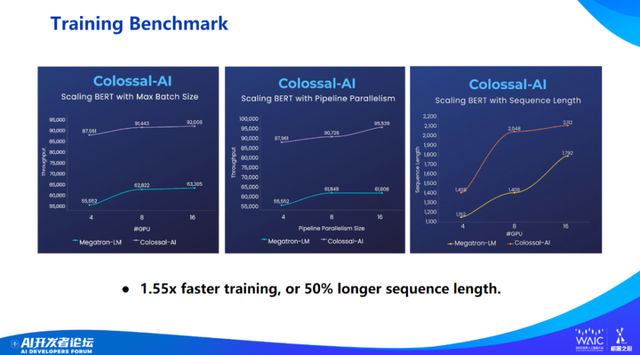
时间关系,实验结果就不介绍了,感兴趣的话可以看一下我们的官网,Colossal-AI 做了很多优化。
比如接下来要介绍的内存优化。其实就是减少 GPU 和 CPU 之间、CPU 与 NVME 硬件之间的数据移动。这一点在未来非常重要。因为 GPU 内存有限,我们需要用 CPU 甚至 NVME 硬件,但它们之间的数据移动可能比计算慢上千倍,如何最小化它们之间的数据移动,以更低成本容纳大模型将非常重要。

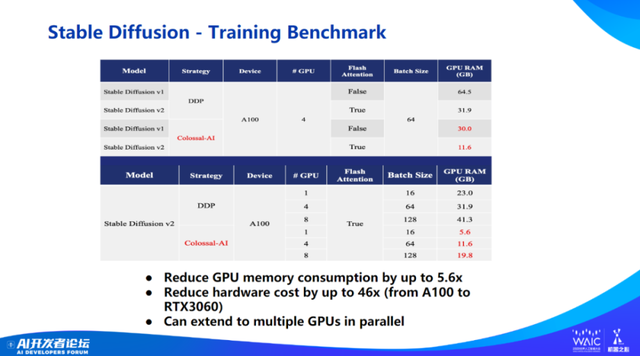
快速过一下一些应用效果。在一些重要应用比如 Stable diffusion 上,Colossal-AI 取得了很好的加速。我们可以把内存开销降低 5.6 倍,硬件成本降低 46 倍。Colossal-AI 经过了很多业界检验。
用 Colossal-AI 加速过的效果图是没有任何损失的。


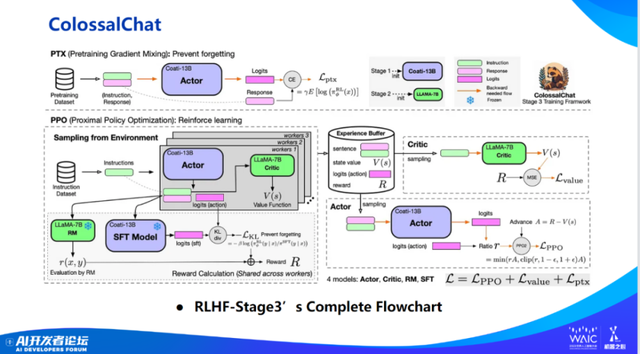
我们通过 Colossal-AI 做了 ColossalChat,是世界上首个开源的最接近 ChatGPT 原始技术方案,具备完整 RLHF 流程的低成本 ChatGPT 复现方案。只有 70 亿或 100 亿的参数模型可以达到更好效果。

这是原理图。
相对于业界标准,Colossal-AI 可以将推理上获得 30-50% 的提速,在训练上获得大概 7 倍加速。
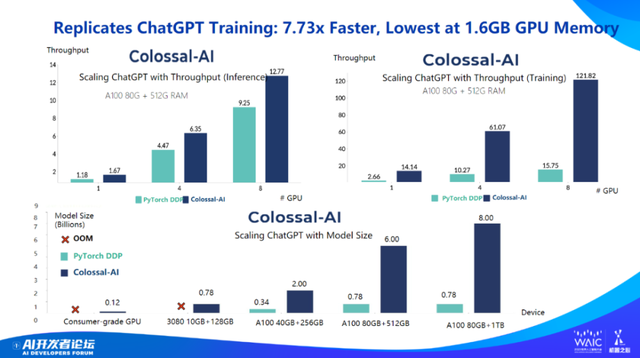
包括可以把 ChatGPT 训练成本从 300 万美金降低到 140 万美金左右。
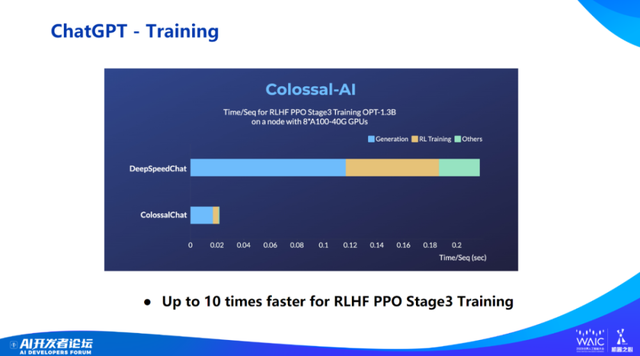
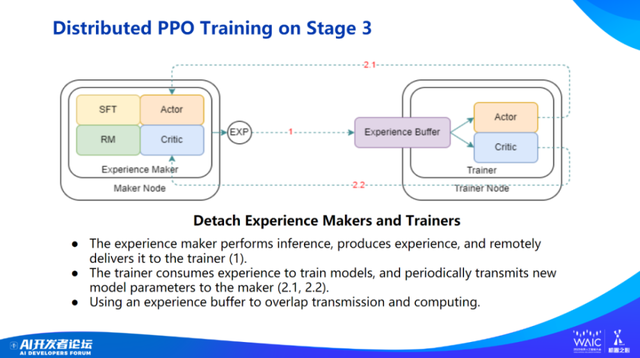
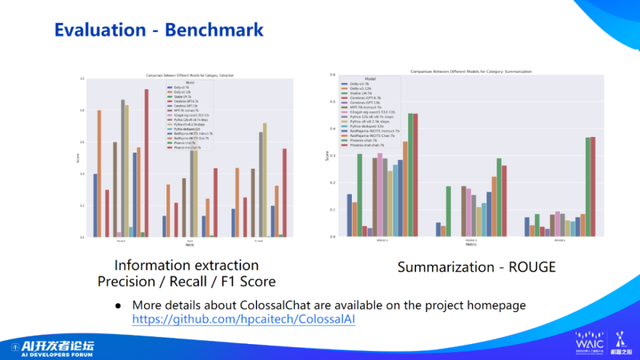
接下来是一些 demo 展示和与斯坦福羊驼的对比,以及一些更进一步分布式 PPO 和 evaluation 的工作。




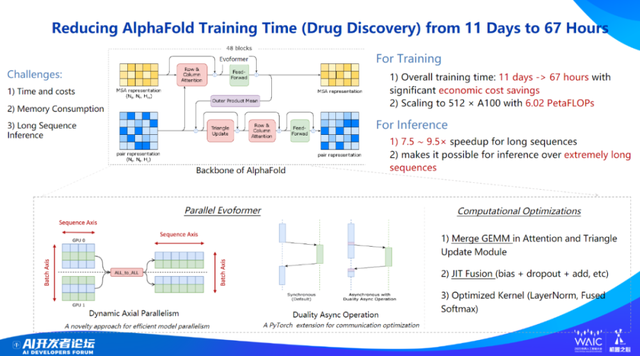
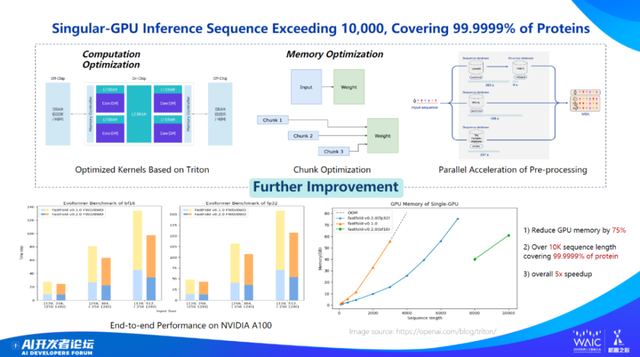
当然,由于我们做的是计算优化,因此不会限制于某个特定行业或者模型,具备良好的通用性。例如对于生物医药行业的蛋白质预测模型 AlphaFold2,我们也可以优化提升约 10 倍的训练推理速度。




















评论