CVPR 2022 | 南洋理工&商汤开源即插即用的SAM-DETR
作者丨轻尘一笑@知乎(已授权)
来源丨https://zhuanlan.zhihu.com/p/489839282
编辑丨极市平台
导读: 在CVPR 2022上,新加坡南洋理工大学和商汤研究院的科研团队提出了SAM-DETR —— 利用语义对齐匹配加速DETR检测器收敛。它仅引入一个简单的即插即用的模块,通过采样“目标显著点”的特征使object query和图像特征的语义对齐,使DETR能够在MS-COCO数据集上迅速收敛。由于此方法即插即用的特性,SAM-DETR可以轻易地与现有的其他加速收敛的方法结合,实现更好的结果。根据作者已开源的代码,在MS-COCO数据集上,仅用ResNet-50,所提出的方法能在12 epoch内达到42.8% AP的检测精度,并能在50 epoch内达到47.1% AP的检测精度。
论文名称:Accelerating DETR Convergence via Semantic-Aligned Matching
ArXiv:https://arxiv.org/abs/2203.06883
代码:https://github.com/ZhangGongjie/SAM-DETR

问题和挑战
DEtection TRansformer(DETR) [1] 是一个新颖的目标检测框架。相比传统的基于Faster R-CNN或YOLO的目标检测器,DETR因其无需人为设计的组件(如Anchor、Non-Maximum-Suppression、训练时正负样本的采样规则等)的优势以及更优秀的检测精度受到了很多的关注。然而,DETR的最大的一个问题是其收敛非常缓慢,因而需要长时间的训练才能达到较高的精度。在MS-COCO数据集上,Faster R-CNN一般只需要12~36个epoch的训练即可收敛,而DETR则需要训练500个epoch才能达到理想的精度。如此高昂的训练成本限制了基于DETR框架的检测器的广泛使用。
动机
DETR [1] 使用一组object query来表示图像中不同位置的潜在目标,作为Transformer decoder的输入。如上图左部所示,DETR的Transformer decoder中的Cross-Attention(Encoder-Decoder Attention)模块可以被理解为一个“匹配+信息提取”的过程:每个object query需要先匹配与之对应的区域,再从这些区域中提取特征以供后续的预测。此过程也可用公式描述为:

其中Q表示object query,F表示Transformer Encoder输出的图像特征,Q’表示包含从F中提取的特征的object query。
然而,作者观察到在Transformer decoder中的Cross-Attention模块里,object query很难精确地匹配到其所对应的区域,这使得object query无法在Cross-Attention中精准地提取其所对应区域的特征。这直接导致了DETR的训练困难。如上图右部所示,造成object query无法正确聚焦于特定区域的原因是Cross-Attention之间的多个模块(Self-Attention和FFN)对object query进行了多次映射,使得object query与图像特征F的语义未对齐,也就是说,object query和图像特征F被映射到了不同的嵌入空间(Embedding Space)内。这使得object query和图像特征F之间的点乘(Dot-Product)+ Softmax难以聚焦在特定区域。
方法介绍
基于上述观察,作者提出了Semantic-Aligned-Matching DETR(SAM-DETR)以实现快速收敛的DETR。其方法的核心思想是利用孪生网络(Siamese Network)在各类匹配任务中的优秀性能,使Cross-Attention中的object query能更容易地聚焦于特定区域。孪生网络(Siamese Network)的核心思想是利用完全相同的两个子网络使匹配的双方被映射到同一个嵌入空间内,也就是说,匹配的双方将在相同的语义下计算相似度。这降低了匹配的难度,并提升了匹配的精确度。
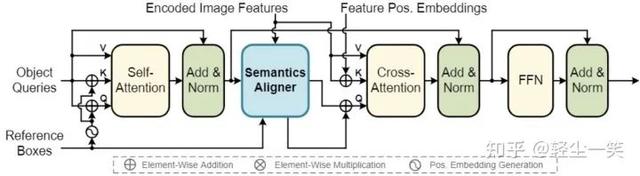
具体来说,如上图所示,SAM-DETR在每层Transformer Decoder Layer的Cross-Attention之前插入了一个“即插即用”的模块 – Semantics Aligner。Semantics Aligner对输入到Cross-Attention中的每一个object query从图像特征F中重采样,以确保匹配双方在语义上是对齐的。此外,不同于DETR [1] 为每一个object query建模一个对应的可学习的位置编码(Position Embedding),作者直接为每一个object query建模一个参考框(Reference Box),以限制重采样的范围。此外,其他设置与原始的DETR [1] 基本保持一致。由于所提出的SAM-DETR的核心部分是一个“即插即用”的模块,不需要对Cross-Attention进行魔改,所以SAM-DETR能够很轻易地与现有的DETR收敛解决方案进行结合,达到更好的效果。
1.利用重采样实现语义对齐的匹配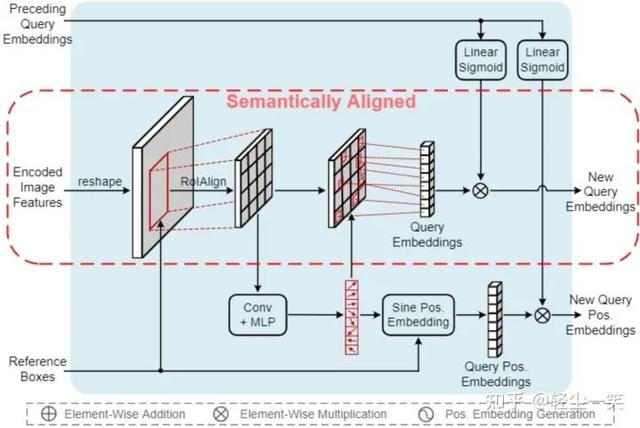
上图所示是作者提出的Semantics Aligner的主要结构。对每个object query,Semantics Aligner根据参考框(Reference Box)用RoIAlign从图像特征中得到其对应区域的2D特征,并从中重采样(Re-Sampling)作为输入到Cross-Attention中的object query embedding。作者尝试了多种重采样方式(包括AvgPool,MaxPool等,见实验结果部分),发现使用多个搜索到的显著点(Salient Point)的特征效果最好。
2.利用显著点特征进行重采样
对于检测任务而言,物体的显著点(Salient Point)(包括边界点、端点、强语义点等)是其识别和定位的关键。所以,作者对显著点的特征进行采样作为Semantics Aligner的输出。
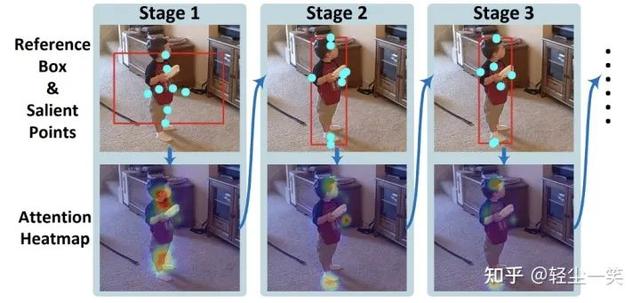
作者直接对RoIAlign得到的区域特征进行卷积+MLP的操作,预测出8个显著点的坐标,再利用双线性插值(Bilinear Interpolation)从图像特征中采样相应位置的特征,并concatenate到一起作为新的object query embedding。相似地,这些显著点的坐标也用于生成对应的位置编码(Position Embedding),同样也concatenate到一起作为输出。搜索到的显著点如下图所示。这样得到的新的object query及其位置编码也可以不加改动地输入到后续的多头注意力(Multi-Head Attention)机制中进行处理。
3.通过特征重加权利用先前的信息
通过上述操作,Semantics Aligner输出了新的object query作为Cross-Attention的输入。但先前的object query仍然包含对Cross-Attention有用的信息。为有效利用这些信息,作者用之前的object query产生重加权参数,对新的object query进行特征重加权(Feature Reweighting)。如此,先前的信息得到了有效的利用,同时也保持了输出的object query的语义仍是与图像特征对齐的。
4.与现有方法的结合
由于SAM-DETR仅引入了一个即插即用的模块,所以它可以很轻易地与现有方法进行结合。作者以SMCA-DETR [2] 为例,证明了SAM-DETR良好的可拓展性。
实验结果
下图为SAM-DETR与DETR [1] 的可视化对比。可以发现,SAM-DETR成功搜索到有意义的显著点,且相比DETR,SAM-DETR的Cross-Attention的响应更加集中。这证明了SAM-DETR能有效地降低object query与图像特征的匹配难度。

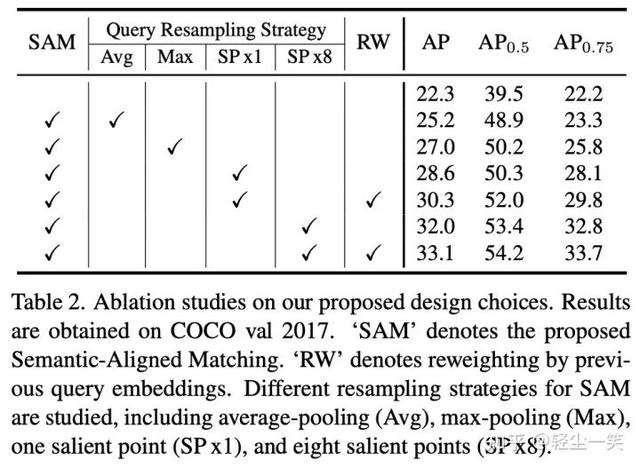
下表是消融实验的结果,证明了语义对齐和搜索显著点特征的有效性。
最后和当前SOTA的对比,SAM-DETR能在很短的训练周期下收敛。值得注意的是,当与SMCA [2] 结合时,即使仅在MS-COCO数据集上训练12个epoch,其检测精度也超过了Faster R-CNN。
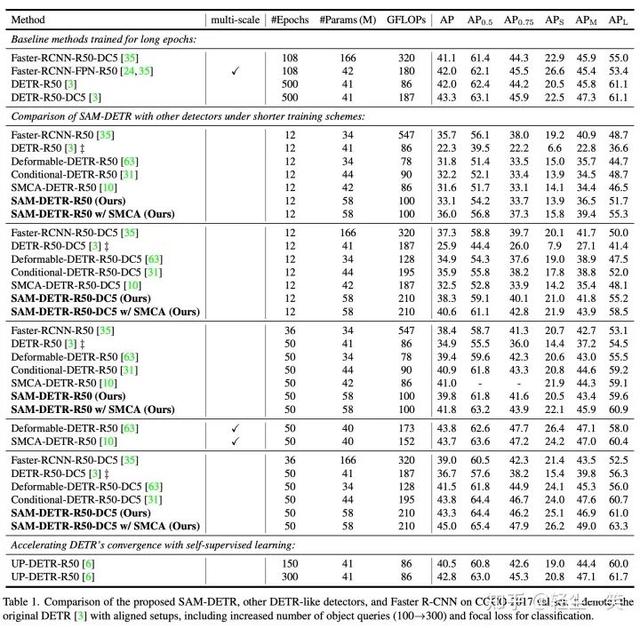
值得一提的是,在作者开源的代码中,还额外提供了SAM-DETR的多尺度版本和已训练好的模型。在MS-COCO数据集,12-epoch下检测精度可达42.8% AP,50-epoch下检测精度可达47.1% AP。
结语
本文介绍了SAM-DETR检测器以加速DETR的收敛。SAM-DETR 的核心是一个简单的即插即用模块,它能在语义上对齐object query和图像特征,以促进它们之间的匹配。此模块还显式搜索显著点的特征以进行语义对齐匹配。SAM-DETR 可以很容易地与现有的DETR收敛解决方案集成,以进一步提高性能。即使仅训练12个epoch,作者所提出的方法也可在MS-COCO数据集上超越Faster R-CNN的检测精度。
References
[1] Carion, Nicolas, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. "End-to-end object detection with Transformers." In European Conference on Computer Vision (ECCV), pp. 213-229. 2020.
[2] Gao, Peng, Minghang Zheng, Xiaogang Wang, Jifeng Dai, and Hongsheng Li. "Fast convergence of DETR with spatially modulated co-attention." In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp. 3621-3630. 2021.





















评论