常用的字符编码与那些特殊的字符
奇怪的现象
本文开始前先列举几个奇怪的字符比较(为了方便看效果请复制,否则会让人大失所望)
★“特殊字符”不相等
-- JS代码'‐'=='-'; //false-- SQL语句select "'‐'='-'" as '比较', '‐'='-' as '比较结果'; -- 0
★“常见字符”不相等
-- JS代码'abc'=='abc'; //false-- SQL语句select "abc=abc" as '比较', 'abc'='abc' as '比较结果'; -- 0
★“空字符”不相等
-- JS代码''==''; //false-- SQL语句select "''=''" as '比较', ''='' as '比较结果'; -- 0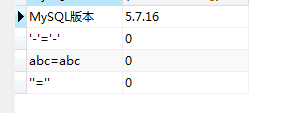
MySQL执行结果
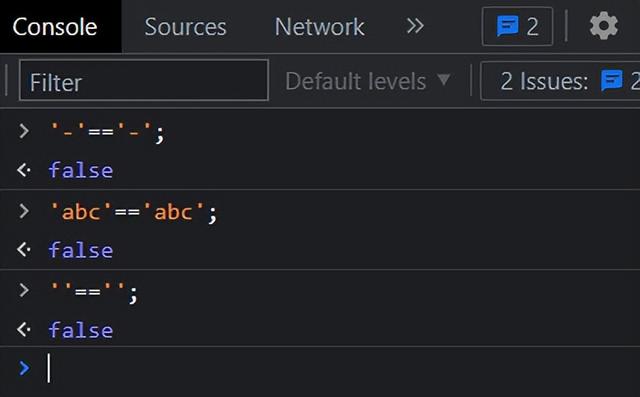
javascript运行结果
★记事本中诡异的现象
一个世界级拳王,一个相声演员,难道泰森跟牛群有瓜葛吗?以下是win10以下版本(不包含win10)操作。保存快捷键ctrl+s,或者点击关闭,然后选择保存,再次打开【注:文本文件一定要用操作系统默认的打开方式】

win10及以上,其实是修复了这个bug,不过按照以下方式还是可以重现这个bug的。
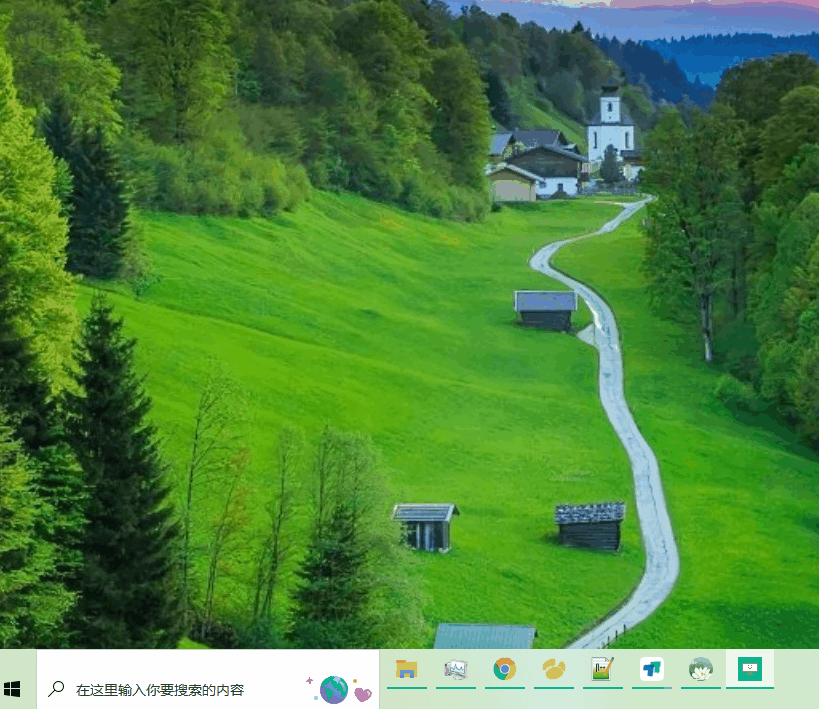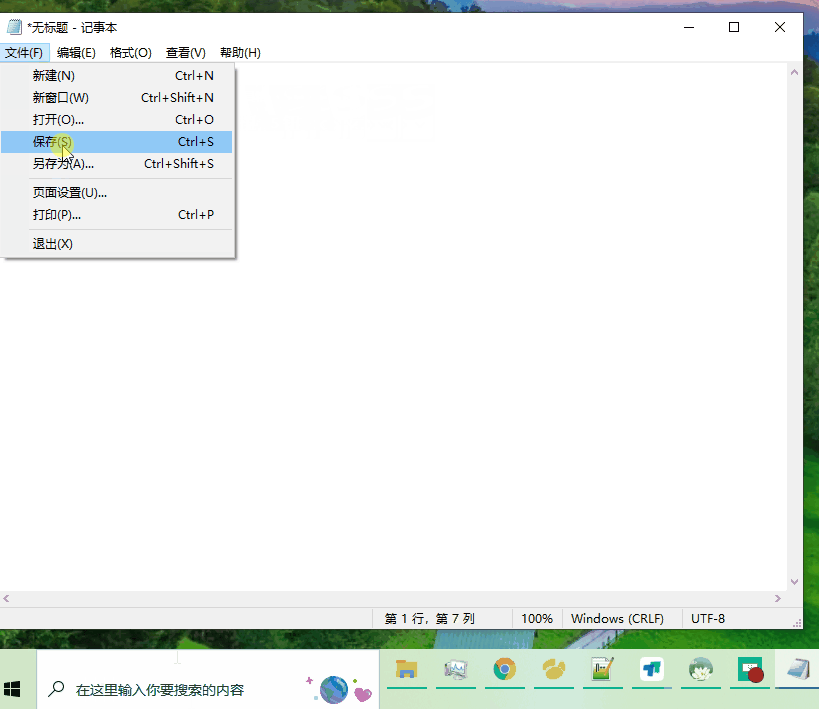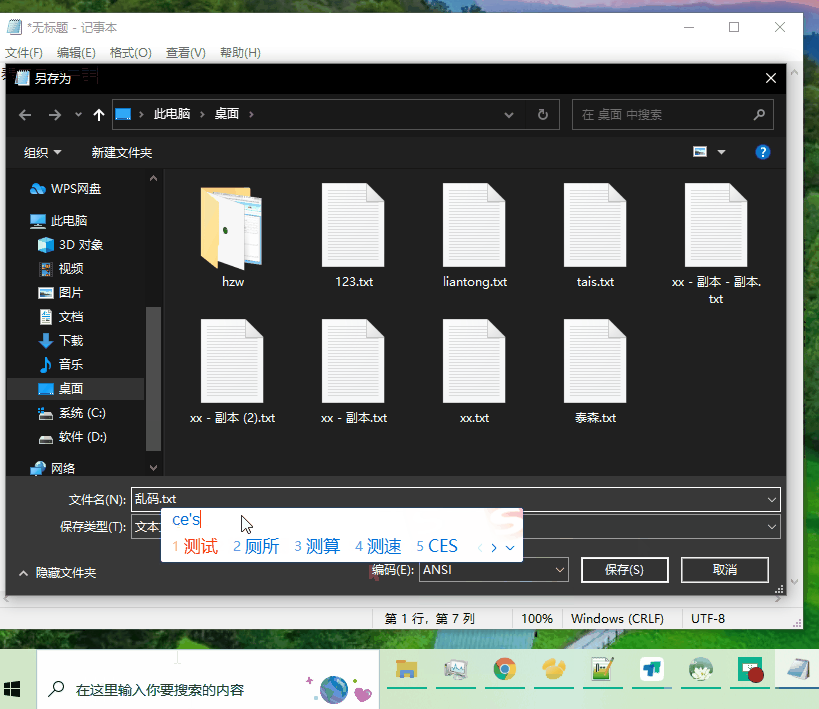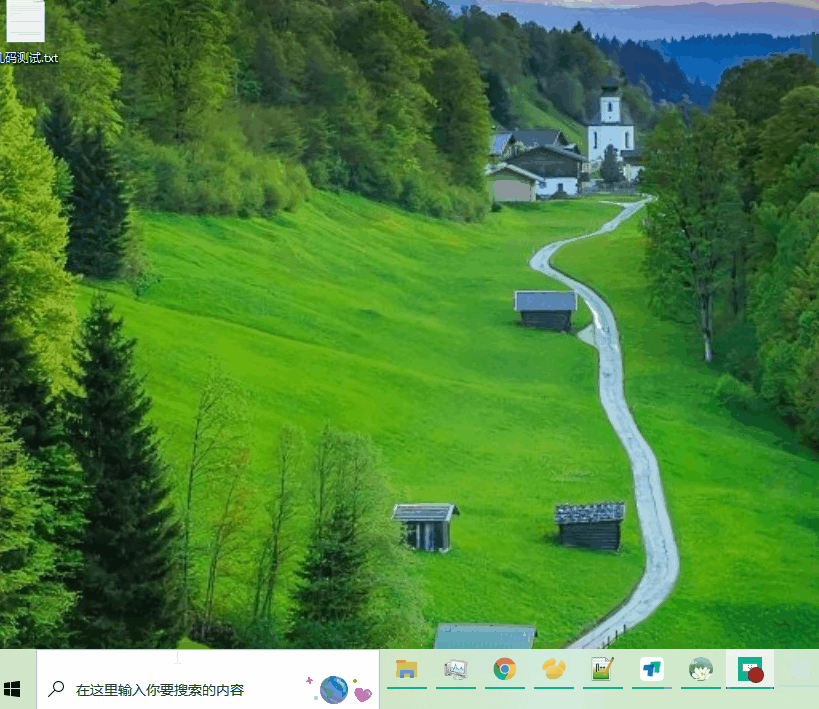
太神奇了“泰森血战牛群”是乱码,多加了一个“了”就正常显示。其实类似的还有“联通”、“搂”等。【注:“搂”保存之后会变成“§”,下面会用到该示例】

记事本中涉及到常用的编码ASCII、GBK编码(包括GB2312)、UTF-8编码、ANSI编码、unicode等多种编码,那我们先从记事本讲起吧!
一. 记事本的前世今生
记事本为什么会出现诡异的问题,一切要从计算机的发展历史说起。 大概70,80年代很早之前的操作系统(DOS系统前身)是没有图形化界面的,只有输入一串串英文数字符号。然而作为世界人口大国跟文明古国的中国人就郁闷了,这玩意不支持中文还咋用,于是撸起袖子干。
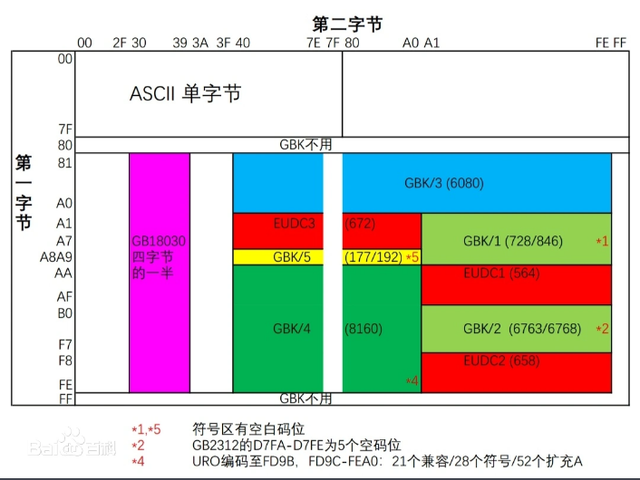
直到1980年中国国家标准总局发布了《信息交换用汉字编码字符集》,并于1981年5月1日开始实施的一套国家标准,标准号是GB2312—1980,简称GB2312。该编码适用于汉字处理、汉字通信等系统之间的信息交换,通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持它。GB2312的规则如图所示:

以下是微软dos系统自带记事本【注:非图形界面的记事本】的伪代码:
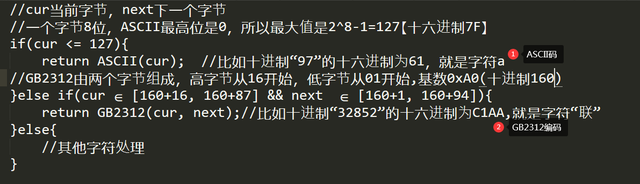
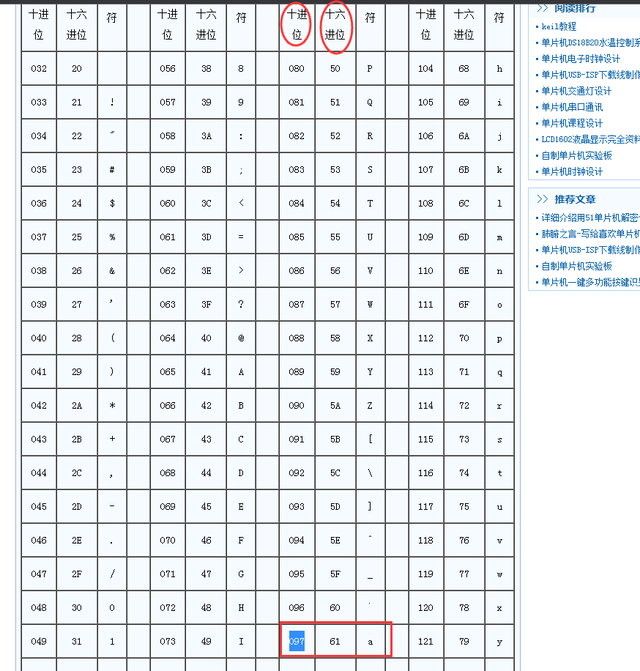
其中1: ASCII码参考 http://www.51hei.com/mcu/4342.html
其中2: GBK【注:GBK兼容GB2312】编码表 https://www.qqxiuzi.cn/zh/hanzi-gbk-bianma.php

后面随着1994年前后微软桌面操作系统Windows NT横空出世并进入中国市场,汉字编码也迎来了一个新的重大版本GBK【由两个字节组成,字节最高位为1,向上兼容GB2312】。它使用了双字节编码方案,其编码范围从8140至FEFE(剔除xx7F),共23940个码位,共收录了21003个汉字,完全兼容GB2312-1980标准,支持国际标准ISO/IEC10646-1和国家标准GB13000-1中的全部中日韩汉字,并包含了BIG5编码中的所有汉字。它的编码规则如下:
微软为了适应不同的市场,不同地区的文字,发明了一个ANSI编码,这个编码在不同国家地区会显示不同编码。对于英文文件是ASCII【由一个字节组成,字节最高位为0】编码,对于简体中文文件是GBK编码(只针对 Windows 简体中文版,如果是繁体中文版会采用 BIG5 码)。以下是window自带记事本更新后的伪代码:

一切都是那么清晰完美,怎么可能会出现乱码呢?确实如此,在当时没有出现过乱码。然而随着电脑越来越普及,世界上存在着越来越多的编码方式,同一个二进制数字可以被解释成不同的符号。
就拿中国来说,存在多个民族,也有不同的文字:
彝文:ꆍꆎꆏꆐꆑꆒ
维吾尔文:تاماق بارمۇ؟
藏文:ཙཚཛཛྷཝ
蒙古文:ᠢᠣᠤᠥᠦᠧ
外国的文字:
日文呢?ぜそぞただち
经常跟我们抢申遗的韩国? 뛞뛟뛠뛡뛢뛣
奇葩的泰国?อฮฯะัาำิีึืฺุู
可以找茬的契文?
上面是有国界的,那没有国界的字符如下:
音乐字符如何呈现?
盲文怎么办?⠸⠹⠺⠻⠼⠽
麻将怎么玩?
表情符又怎么表示?

预览时发现有些字符无法正常显示,只有编辑时才能发现,特此截图以说明
如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是 万国码Unicode【UTF-8编码是 Unicode 的实现方式之一】,就像它的名字都表示的,这是一种所有符号的编码。它支持世界上所有的字符。
Unicode编码比较复杂,下面只简单介绍最常用的实现方式之一的UTF-8.
UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。它的编码规则很简单,只有两条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
2)对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
下表总结了编码规则,字母x表示可用编码的位。
unicode符号范围 | UTF-8编码方式(红色是标记位)
(十六进制) | (二进制)
----------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
unicode字符集的二进制编码规则:删除标记位上的数字,将剩余的二进制数字合在一起,不足16位的,在数字前补足0。
微软为了布局全球于是支持了Unicode,但当时大部分软件都是用ANSI编码的,unicode还不流行,怎么办?Windows想了个办法,就是允许一个默认语言编码,就是当遇到一个字符串,不是unicode的时候,就用默认语言编码解释。而记事本的ANSI编码,就是这种默认编码,所以,一个中文文本,用ANSI编码保存,在中文版里编码是GBK模式保存的时候,到繁体中文版里,用BIG5读取,就全乱套了。
记事本也不甘心这样,所以它要支持Unicode,但是有一个问题,一段二进制编码,如何确定它是GBK还是BIG5还是UTF-16/UTF-8?记事本的做法是在TXT文件的最前面保存一个标签,如果记事本打开一个TXT,发现这个标签,就说明是unicode。标签叫BOM,如果是0xFF 0xFE,是UTF16LE,如果是0xFE 0xFF则UTF16BE,如果是0xEF 0xBB 0xBF,则是UTF-8。如果没有这三个东西,那么扫描文本中的所有字符,如果所有字符都满足这个编码规则,则就将改编码设置成默认编码。修改后的伪代码如下:
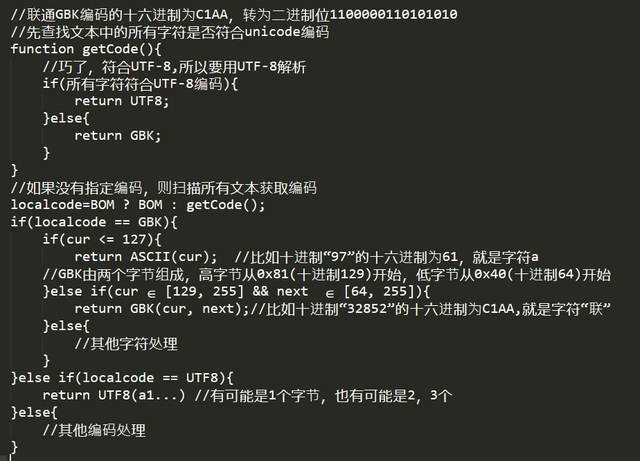
也就是输入“泰森血战牛群”中的了,由于“了”不满足unicode编码,所有字符都符合GBK编码规范,所以正常显示。微软自以为聪明完美拥抱了unicode,万无一失,此刻的心情是这样的

由于"泰森血战牛群"保存是乱码而且完全无法识别,下面用“搂”这个示例完整地看下window自带记事本的处理流程并验证我的猜想。
1.新建一个记事本文件:由于操作系统是中文,那么系统默认编码就是GBK,但是未指定编码(因为它不知道要存储的内容)
2.输入关键字“搂”:当前系统GBK,输入设备“搂”(十六进制C2A7)转成二进制字节11000010 10100111存储在内存

3. 判断字符编码:符合utf8编码方式110xxxxx 10xxxxxx,根据utf8转换成二进制00000000 10100111,转成十六进制就是A7,也就是§
4. 保存:将A7保存在磁盘中。
5. 用window自带记事本打开显示§

推荐以下在线工具对上述的进行验证:
unicode字符大全:https://www.qqxiuzi.cn/zh/unicode-zifu.php
在线进制转换:https://tool.oschina.net/hexconvert
到此就完全解开了记事本中那些诡异的字符,现在将那些符合Unicode编码又符合GB2312的汉字(乱码集合)奉献给大家:
馈愧溃坤昆捆困括扩廓阔垃拉喇蜡腊辣啦莱来赖蓝婪栏拦篮阑兰澜谰揽痢立粒沥隶力璃哩俩联莲连镰廉怜涟帘敛脸链恋炼练粮凉梁粱良两辆量隆垄拢陇楼娄搂篓漏陋芦卢颅庐炉掳卤虏鲁麓碌露路赂鹿潞禄录陆戮驴谩芒茫盲氓忙莽猫茅锚毛矛铆卯茂冒帽貌贸么玫枚梅酶霉煤没眉媒镁每摹蘑模膜磨摩魔抹末莫墨默沫漠寞陌谋牟某拇牡亩姆母墓暮幕募慕木目拧泞牛扭钮纽脓浓农弄奴努怒女暖虐疟挪懦糯诺哦欧鸥殴藕呕偶沤啪趴啤脾疲皮匹痞僻屁譬篇偏片骗飘漂瓢票撇瞥拼频贫品聘乒坪苹萍平凭瓶恰洽牵扦钎铅千迁签仟谦乾黔钱钳前潜遣浅谴堑嵌欠歉枪呛腔羌墙蔷强取娶龋趣去圈颧权醛泉全痊拳犬券劝缺炔瘸却鹊榷确雀裙群然燃冉染瓤伞散桑嗓丧搔骚扫嫂瑟色涩森僧莎砂杀刹沙纱傻啥煞筛晒珊苫杉山删煽省盛剩胜圣师失狮施湿诗尸虱十石拾时什食蚀实识史矢使屎驶始式示士恕刷耍摔衰甩帅栓拴霜双爽谁水睡税吮瞬顺舜说硕朔烁斯撕嘶思私司丝獭挞蹋踏胎苔抬台泰酞太态汰坍摊贪瘫滩坛檀痰潭谭谈坦毯袒碳探叹炭汀廷停亭庭挺艇通桐酮瞳同铜彤童桶捅筒统痛偷投头透凸秃突图徒途涂巍微危韦违桅围唯惟为潍维苇萎委伟伪尾纬未蔚味畏胃喂魏位渭谓尉慰稀息希悉膝夕惜熄烯溪汐犀檄袭席习媳喜铣洗系隙戏细瞎虾匣霞辖暇峡小孝校肖啸笑效楔些歇蝎鞋协挟携邪斜胁谐写械卸蟹懈泄泻谢屑薪芯锌选癣眩绚靴薛学穴雪血勋熏循旬询寻驯巡殉汛训讯逊迅压押鸦鸭呀丫芽摇尧遥窑谣姚咬舀药要耀椰噎耶爷野冶也页掖业叶曳腋夜液一壹医揖铱印英樱婴鹰应缨莹萤营荧蝇迎赢盈影颖硬映哟拥佣臃痈庸雍踊蛹咏泳涌浴寓裕预豫驭鸳渊冤元垣袁原援辕园员圆猿源缘远苑愿怨院曰约越跃钥铡闸眨栅榨咋乍炸诈摘斋宅窄债寨瞻毡詹粘沾盏斩辗崭展蘸栈占战站湛帧症郑证芝枝支吱蜘知肢脂汁之织职直植殖执值侄址指止趾只旨纸志挚住注祝驻抓爪拽专砖转撰赚篆桩庄装妆撞壮状椎锥追赘坠缀谆准捉拙卓
用自带的记事本打开上面的文字的效果如下:

当然如果想知道上面汉字如何来的,获取方式:三连(点赞 收藏 关注)哈,我将用java代码或者js代码的方式提供给关注我的小伙伴们!
如何快速查看中文的unicode编码点
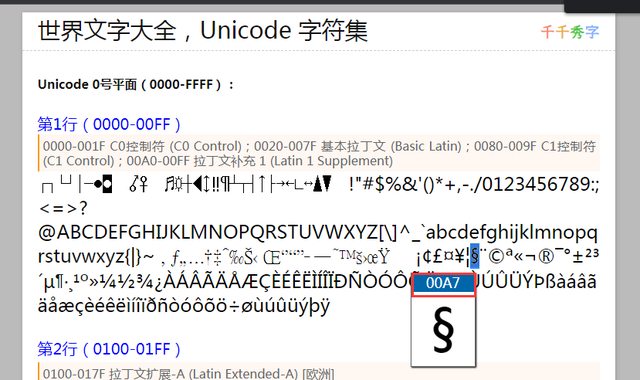
如何看到汉字的unicode编码呢?下面介绍三种简单的显示办法。下面以中为例,其编码如下:

①notepad++编辑器:使用方法见 https://www.cnblogs.com/yucloud/p/10934511.html
②sublime编辑器: 使用方法见https://blog.csdn.net/VariatioZbw/article/details/107974563
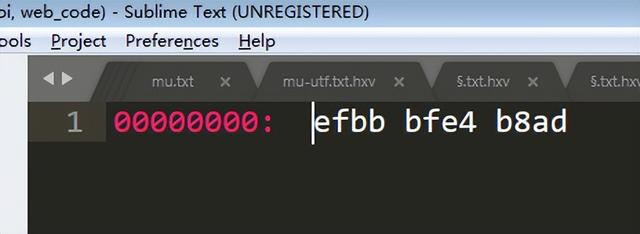
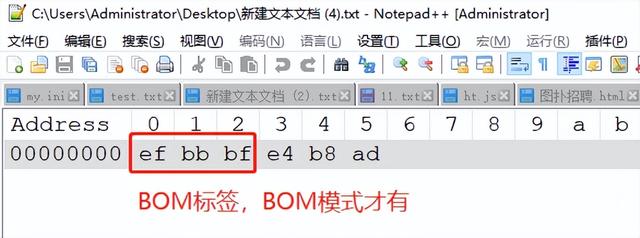
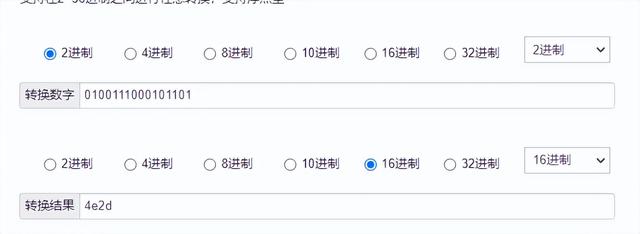
可见“中”由三个字节e4b8ad组成(移除efbbbf BOM标签),转成二进制位:11100100 10111000 10101101 按照utf-8编码规则转成二进制代码点:01001110 00101101,再转成16进制
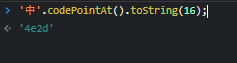
③用js代码获取
奇怪现象的解释
js脚本语言真的是太方便了,所见即所得,下面我用js来说明,其他语言类似【注:用MySQL进行操作时,可能会有意外的惊喜,欢迎小伙伴踊跃留言讨论,评论区会有彩蛋】
针对'‐'=='-',其实这两个看似长的一样的字符,其实是不同字符,见如下:
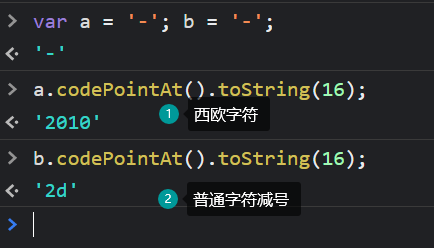

'abc'=='abc',这个其实有一个字符串中包含了一个不可见的字符(用上面的方法也可以找到对应的unicode编码点,有兴趣的小伙伴试试在此就不再说明),如下所示:
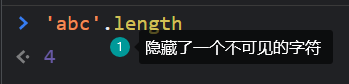
那为什么“”在这里能收到,但是丢到微信、QQ里又搜不到呢?大概因为是在其他地方穿越了吧(有兴趣的评论区讨论)!

编辑可以看见也可以查询,但是预览发布又穿越了!
本章素材来源:
1. Windows 记事本的 ANSI、Unicode、UTF-8 这三种编码模式有什么区别?https://www.zhihu.com/question/20650946
2. 字符编码笔记:ASCII,Unicode 和 UTF-8 http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
3. UTF-8编码透析–神奇的“联通”乱码现象 https://blog.csdn.net/qfguan/article/details/121145568





















评论