NLP两强争霸:OpenAI与GPT-2 的“倔强”进击

图片来源@unsplash
文|脑极体
自然语言处理(NLP)技术正在生活的方方面面改变着我们的生活。
客厅的智能音箱在跟你每天的对话中飞速进步,甚至开始跟你“插科打诨”来适应你的爱好习惯。
电商客服总是能在第一时间回复,可能处理完你的问题,你也并未发觉TA可能只是一个智能客服。现实版的“图灵测试”每天都在发生。
经常查阅外文资料的你也许早已习惯网页或几家搜索引擎的一键翻译,译文的质量好到让你觉得学外语的时间纯属浪费。
闲来无聊当你刷信息流或者短视频,总是事后发现沉迷其中的时间越来越多,其实背后正是自然语言算法平台在根据你的浏览习惯、注意力时长来进行的优化推荐。
由果溯因,我们希望简单回顾近几年NLP的跃迁升级,沿着这条技术洪流一直溯源。回到水源充沛、水系林立的技术源头,来理解NLP演进的脉络。
NLP两强争霸: OpenAI与GPT-2 的“倔强”进击
关注NLP的人们一定知道,2018年是NLP领域发展的大年。
2018年6月,OpenAI发表了题为《Improving Language Understanding by Generative Pre-Training》的论文,提出基于“预训练语言模型”的GPT,它首先利用了Transformer网络代替了LSTM作为语言模型,并在12个NLP任务中的9个任务获得了SOTA的表现。但种种原因GPT并未获得更大关注。
GPT的基本处理方式是在大规模语料上进行无监督预训练,再在小得多的有监督数据集上为具体任务进行精细调节(fine-tune)的方式,不依赖针对单独任务的模型设计技巧,可以一次性在多个任务中取得很好的表现。
直到10月,谷歌的BERT(Bidirectional Encoder Representation from Transformers)问世,一经发布便得到各界广泛关注。BERT模型在11项NLP任务中夺得SOTA的表现,更是令谷歌技术人员宣告“BERT开启了NLP新时代”的宣言。而BERT其实采用了和GPT完全相同的两阶段模型,首先是无监督的语言模型预训练;其次是使用Fine-Tuning模式解决下游任务。其不同之处在于BERT在预训练阶段采用了类似ELMO的双向语言模型,且使用了更大数据规模用于预训练。
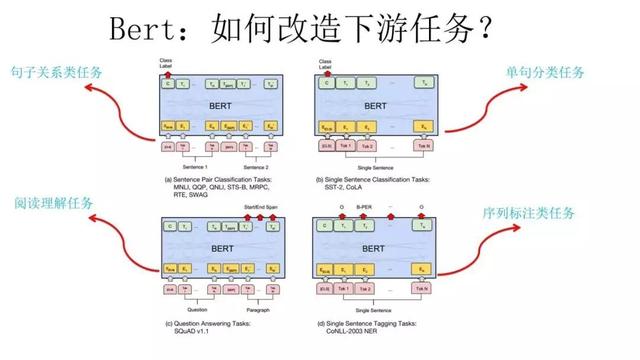
BERT在改造NLP下游任务(包括序列标注,比如中文分词、词性标注、命名实体识别、语义角色标注等;第二类是分类任务,比如文本分类、情感计算等;句子关系判断,比如Entailment,QA,语义改写,自然语言推理等;生成式任务,比如机器翻译、文本摘要、写诗造句、看图说话等)上面,强大的普适性和亮眼的任务表现,成为它爆红NLP的底气。
仅仅四个月后,OpenAI发布GPT-2。这一大规模无监督NLP模型,可以生成连贯的文本段落,刷新了7大数据集SOTA表现,并且能在未经预训练的情况下,完成阅读理解、问答、机器翻译等多项不同的语言建模任务。
首先,CPT-2、BERT与GPT一样,延续Transformer的Self-Attention(自注意)作为底层结构。
OpenAI研究人员对无监督数据训练的坚持也许来自于这样一个思路:监督学习会造成语言模型仅能处理特定任务表现很好,而在泛化能力表现很差;而单纯依靠训练样本的增加,很难有效实现任务扩展。因此,他们选择在更通用的数据集基础上使用自注意力模块迁移学习,构建在 zero-shot 情况下能够执行多项不同NLP任务的模型。
与BERT的不同在于,CPT-2模型结构仍然延续了GPT1.0的“单向语言模型”。GPT-2似乎只有一个目标:给定一个文本中前面的所有单词,预测下一个单词。这一点倔强坚持,可以看出OpenAI的解决思路。
它选择把Transformer模型参数扩容到48层,包含15亿参数的Transformer模型,找到一个800 万网页(WebText)数据集作为无监督训练数据。简单说,GPT-2 就是对 GPT 模型的直接扩展,在超出 10 倍的数据量上进行训练,参数量也多出了 10 倍。这让GPT-2采用更加直接“暴力”的方式,单靠提升模型参数容量和增加训练数据的数量来超过BERT。
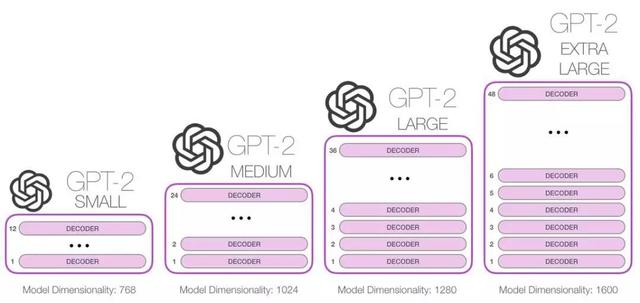
GPT-2作为一个文本生成器,只要在开始输入只言片语,这个程序会根据自己的判断,决定接下来应该如何写作。简言之,GPT-2作为通用语言模型,可以用于创建AI 写作助手、更强大的对话机器人、无监督语言翻译以及更好的语音识别系统。
OpenAI 设想,人们可能出于恶意目的利用GPT-2来生成误导性新闻、网上假扮他人欺诈、在社交媒体自动生产恶意或伪造内容、自动生产垃圾或钓鱼邮件等内容。所以,OpenAI在发布GPT2的同时就宣称“这种强力的模型有遭到恶意滥用的风险”,选择不对训练模型做完整开源,这一举动引来机器学习&自然语言处理界研究人员的激烈讨论。
无论是被外界嘲讽为对自家产品的“过分自负”,还是OpenAI出于PR目的的“故意炒作”,GPT-2 “刻意制造假新闻”的实力确实惊艳到了业内众人。各位吃瓜群众一边实力吐槽,一边又迫不及待想探究GPT-2的强大生成能力。
经过将近一年时间, GPT-2在谨慎开源和开发者的“尝鲜”参与中,进行着眼花缭乱的更新演进。
GPT-2阶段开源:带给开发者的土味狂欢
伴随争议和开发者高涨的呼声,OpenAI仍然出于谨慎考虑,选择了分阶段开源。8月以后,它分阶段发布了“小型的”1.24 亿参数模型(有 500MB 在磁盘上),“中型的”3.55 亿参数模型(有 1.5GB 在磁盘上 ),以及 7.74 亿参数模型(有 3GB 在磁盘上 )。直到11月6日,它正式放出GPT-2最后一个部分的包含15亿参数的最大版本的完整代码。
一直到完整版本公布,OpenAI并未发现任何明确的代码、文档或者其他滥用实证,也就是说一直担心的“GPT-2遭到滥用”的结果并没有发生,但OpenAI仍然认为,全面版本发布同时也会让恶意人士有机会进一步提高检测逃避能力。

所以,伴随着GPT-2不同版本的陆续公布,OpenAI自身与多家复现GPT-2模型的团队进行交流,验证GPT-2的使用效果,同时也在避免滥用语言模型的风险,完善检测文本生成的检测器。同时,OpenAI也还在与多家研究机构合作,比如对人类对语言模型产生的数字信息的敏感性的研究,对恶意利用GPT-2的可能性的研究,对GPT-2生成文本的统计可检测性的研究。
无论OpenAI出于怎样的谨慎,随着不同容量参数模型的发布,外界开发人员已经迫不及待进行各种方向的探索了。
2019年4月,Buzzfeed 数据科学家 Max Woolf使用Python封装了具有 1.17 亿超参数的“较小”版本的 OpenAI GPT-2 文本生成模型进行微调和生成脚本,开源了一个“GPT-2 精简版”,从而更好地帮助人们生成一段文本,里面可以给出很多出人意料的内容。
在OpenAI逐步开源的过程里,来自布朗大学的两位研究生就率先自己动手复制出一个 15 亿参数量的 GPT-2,并将其命名为 OpenGPT-2。过程中,他们使用自己的代码从零开始训练 GPT-2 模型大约只花费了 5 万美元。所用的数据集也尽可能参照OpenAI论文里公开的方法。有很多热心网友的测试后表示,OpenGPT-2 的输出文本效果优于 OpenAI 的 GPT-2 7.74 亿参数版本。当然,也有人认为,并没有比GPT-2模型生成的文本效果更好。
同时在国内,一个位于南京名叫“Zeyao Du”的开发者,在GitHub上开源了的GPT-2 Chinese,可以用来写诗、新闻、小说和剧本,或是训练通用语言模型。这一能够实现逆天效果GPT-2模型,用到了15亿个参数。目前他开源了预训练结果与 Colab Demo 演示,只需要单击三次,人们就可以生成定制的中文故事。
GPT-2模型还有更多尝试。一个新加坡高中生Rishabh Anand开源了一个轻量级GPT-2“客户端”——gpt2-client,它是一个GPT-2 原始仓库的包装器,只需5行代码就可以实现文本生成。
来自中国的几个研究者正在用GPT模型生成高质量的中国古典诗歌。比如论文里提到的一首《七律·一路平安》:“一声天际雁横秋,忽梦青城旧友游。路入青林无去马,手携黄牒有归舟。平生志业商山老,何日公卿汉署留。安得相从话畴昔,一樽同醉万山头”。一场平平淡淡的送别,写得就饱含沧桑、充满离愁。不难让人怀疑:这个语言模型是否真的有了感情?
GPT-2模型还可以用在音乐创作上。OpenAI推出一种用于生成音乐作品的深层神经网络——MuseNet,正是GPT-2语言模型Sparse Transformer相同的通用无监督技术,允许MuseNet根据给定的音符组预测下一个音符。该模型能够用10种不同的乐器制作4分钟的音乐作品,并且能够从巴赫,莫扎特,披头士乐队等作曲家那里了解不同的音乐风格。它还可以令人信服地融合不同的音乐风格,以创造一个全新的音乐作品。
最让笔者感兴趣的是一位开发者通过GPT-2做出的一款AI文字冒险游戏——“AI地牢”。通过多轮文本对话, AI就可以帮你展开一段意想不到的“骑士屠龙”征途或者“都市侦探”之旅。在未来的游戏产业中,AI创造的故事脚本,也许可能更具想象力?
GPT-2发布的一年里,以上开源带来的应用足以称之为眼花缭乱。喧闹与繁荣背后,除了在在开源风险上的小心谨慎,OpenAI还面临着哪些难题?
NLP的土豪赛:OpenAI联姻微软后的 GPT-2商业化
其实,我们从BERT和GPT-2的演进趋势,可以看出人类利用更大容量的模型、无监督的无限训练,可以去创造更多更好的合乎人类语言知识的内容。但这也同样意味着要依靠超级昂贵的GPU计算时间、超大规模GPU机器学习集群、超长的模型训练过程。这意味着这种“烧钱”模式,使得NLP的玩家最终会更加向头部公司聚集,成为少数土豪玩家的赛场。
可以预见,如果今年OpenAI再推出GPT-3.0,大概率还是会选择单向语言模型,但会采取更大规模的训练数据和扩充模型,来与BERT硬刚。NLP应用领域的成绩也会再次刷新。
但从另一个侧面看到,如此“烧钱”的语言训练模型的研发,尚无清晰的商业化应用前景。OpenAI也不得不面临着“遵循技术情怀的初衷”还是“为五斗米折腰”的商业化的艰难选择。
答案应该已然明了。就在2019年7月,OpenAI接受了微软的10亿美元投资。根据官方说法,OpenAI将与微软合作,共同为微软Azure云平台开发新的人工智能技术,并将与微软达成一项排他性协议,进一步扩展大规模人工智能能力,“兑现通用人工智能(AGI)的承诺”。
其实质正是OpenAI在人工智能研究上的“烧钱”与其商业化的尴尬,使得它更需要这样一笔来自微软的“赞助”。就以拥有15亿参数的GPT-2模型为例,它使用256块TPU v3训练,每小时都要花费2048美元。可以预见,如果我们还想期待GPT-3.0的发布,其费用将主要就花在云端的计算资源上面。
微软将成为OpenAI独家云计算供应商。OpenAI的人工智能技术也要通过Azure云输出。未来,OpenAI将把部分技术授权给微软,然后由微软把这些技术商业化,并将其出售给合作伙伴。
这笔巨额费用的支持,让OpenAI有了更充足的底气。如上面所总结的,GPT-2在8月份后继续开始分步骤发布不同量级的参数模型,并在11月全部开源。显然GPT-2未来在商业化方向上,可以更多的借助微软Azure的加持。比如可以未来更好的与Office365协作,参与到办公协助的自动化文本写作当中,参与语法错误修复,也可以建立更自然真实的问答系统。
曾经年少爱追梦,一心只想往前飞。AGI的理想也需要在商业实践中照进现实。可以预见,2020年,谷歌面对微软&OpenAI的组合,将给NLP商业化带来更多波澜。


















评论