Interspeech 2019 | 从顶会看语音技术的发展趋势
本文来自公众号滴滴科技合作,AI科技评论获授权转载,如需转载请联系原公众号。
语音领域顶级学术会议 Interspeech 2019 于 9 月 15-19 日在奥地利格拉茨Graz举行。
本文分为三部分,阅读时长约 18 分钟。
01
这部分带来的是:9月16日主会议第一天上的会议亮点,开幕式介绍,以及在语音识别,语音合成,自然语言理解和说话人识别四个方面的深入技术解读。
会议亮点
今年的Interspeech在一些Oral Session里设置了一个Survey Talk的环节,来针对性介绍相关领域的技术。
Interspeech的Oral Session一般是那些相对关注度高的Session,一般被安排在整个会场最大展厅(Main Hall)里。
9月16日上午的End-to-end Speech Recognition的Session的第一个环节是一个40分钟的Survey Talk,内容是“Modeling in Automatic Speech Recognition: Beyond Hidden Markov Models”。同样在下午的Attention Mechanism for Speaker State Recognition的Session中有一个关于 When Attention Meets Speech Applications: Speech & Speaker Recognition Perspective的Survey Talk。
这两个Survey Talk讨论的主题虽然侧重有所不同,但都和Attention有着非常强的连接。
一个是从ASR建模的角度展开,从HMM出发,引出了CTC以及Attention等模型,并做了对比讨论。另一个是从Attention算法的提出以及在语音当中的应用展开,对比讨论了多种不同的Attention模型及其变种在语音识别和说话人识别的应用情况。
值得注意的是,Attention相关算法几乎出现在了今年Interspeech的所有语音识别或者说话人识别研究的文章中。从最开始Attention,到Listen-Attend-Spell,再到Self-Attention(或者Transformer),在不同的文章(无论Oral或者Poster)被大家多次介绍和分析,频繁出现在了相关文章Introduction环节中。
如第一个Survey Talk里面讨论的内容一样,语音识别经历了从2012年最开始的DNN的引入时的Hybrid HMM结构,再到2015年开始吸引大家研究兴趣的CTC算法,而后到近两年的Attention相关结构的研究热点。
当然Attention结构下,依然还有很多内容需要研究者们进一步地深耕:例如今天的Survey Talk里面提到的在一些情况下Hybrid 结构依然能够得到State-of-the-art的结果,以及语音数据库规模和Attention模型性能之间的关系。
开幕式
9月16日的上午Interspeech的开幕式上,主委会总结了今年的论文和赞助情况。


语音技术深度解读
语音识别
在此次会议上,端到端语音识别仍然是ASR研究的一大热点,正如上文提到的,基于Attention机制的识别系统已经成为了语音技术研究主流。
CMU和KIT的研究者在"Very Deep Self-Attention Networks for End-to-End Speech Recognition"文章中创新性地提出了一种非常深的自注意力机制的网络,采用这种Deep Self-Attention的网络,可以大幅提升端到端语音识别系统识别精度。


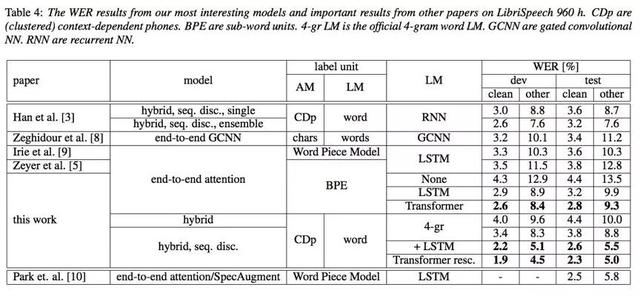
同时,随着端到端语音识别框架日益完善,研究者们对端到端模型的训练和设计更加的关注。RWTH的研究者在“RWTH ASR Systems for LibriSpeech: Hybrid vs Attention”一文中,详细的研究了基于端到端语音识别框架,我们可以从建模单元、声学模型建模模型、语言模型等各个方面来提升端到端识别系统的整体性能。

语音合成
高音质语音生成算法及Voice conversion是今年Interspeech研究者关注的两大热点。
IBM research的Zvi Kons等人在“High quality, lightweight and adaptable TTS using LPCNet”文章中,提出了一种基于LPCNet的TTS系统,此系统具有高音质、轻量化、适应能力强等优点。
而今年的Voice Conversion方向的研究重点主要集中在基于GAN的方法上。NTT的Takuhiro Kaneko在文章“StarGAN-VC2:Rethinking Conditional Methods for StarGAN-Based Voice Conversion”中,提出了第二代的StarGAN,该方法提出了一种新的源-目标条件对抗损失函数,这样可以把所有源域数据转换为目标域数据。同时文章提出一种新的基于调制方法的模型框架。从实验结果看,该方法可以大幅提升Voice Conversion的性能。


自然语言理解
在今年的会议中,在端到端的口语的语言理解(Spoken Language Understanding)的方法上,会大量侧重在基于预训练(Pretraining)的方法,也有一些使用新的建模单元(如基于帧),以及用GAN,对抗训练(Adversarial Training)来获取更加有效的口语文本的表示。
基于预训练(Pretraning)的方法可以缓解纯端到端的方法标注数据少以及很难训练的问题。这个方法主要是用其他相关任务中同领域/跨领域的有/无标注数据预训练一个模型。训练完模型,再利用该模型初始化或者知识蒸馏(Knowledge Distill)来指导当前的语言理解模型的训练,进而用该模型进行目标语言理解任务的学习。
基于预训练(Pretraining)的方法主要分为基于语音和文本。基于语音的方法主要有预训练ASR、Speaker模型;基于文本的方法主要有预训练Intent Detection、Slot Filling、Bert等方法。
在端到端的口语的语言理解(Spoken Language Understanding)中,对话生成的方法的主要是利用更多有用的信息来学习得到更加有效的对话的特征表示,从而生成更加丰富准确的对话回复,包括利用主题信息,考虑多轮层次结构信息,以及ASR的置信度。
说话人识别
在16日的会议中,有两个session与说话人技术相关。作为语音信号中的重要信息,说话人信息,特别是说话人识别及切分,正被越来越多的研究者所重视。
16日上午的Speaker Recognition and Diarization着重于说话人切分。
“Bayesian HMM Based x-Vector Clustering for Speaker Diarization”来自说话人技术大牛Lukáš Burget等人。论文介绍了在x-vector系统基础上引入贝叶斯隐马尔可夫模型结合变分贝叶斯推理来解决说话人切分问题的方法。相比传统的AHC聚类方法,论文提出的算法既快又好还鲁棒,带来的显著的性能提升。
“LSTM Based Similarity Measurement with Spectral Clustering for Speaker Diarization”作者为昆山杜克大学的Qingjian Lin与Ming Li等,着重解决说话人聚类中打分性能不好的问题。论文提出了直接使用LSTM替代PLDA作为说话人后端,来提升相似性打分性能。论文方法对DER有明显提升。
“Speaker-Corrupted Embeddings for Online Speaker Diarization”提出了相当有意思的方法。在训练说话人向量提取器时,直接使用UBM超向量作为网络输入,加入其他说话人的信息来增强提取器的训练数据及泛化能力。然而仅使用了64 UBM使得该工作在大数据上的有效性存疑。
16日下午的Attention Mechanism for Speaker State Recognition探讨了Attention机制在ASR之外的应用方向。
综述由ASAPP的Kyu J. Han带来,详述了Attention机制在ASR领域的发展历程,以及在说话人识别上的应用。目前Attention在说话人方面更类似一种Time Pooling,比Average Pooling及Stats Pooling更能捕捉对说话人信息更重要的信息,从而带来性能提升。
随后的几篇论文大多探讨Attention机制在Emotion识别上的应用。
“Attention-Enhanced Connectionist Temporal Classification for Discrete Speech Emotion Recognition”主要结合CTC与Attention机制识别语音中的Emotion。在提问环节,有人问到为何结合两者,因为CTC与Attention机制都可以做序列分类,并且Emotion也不是序列转写问题。作者认为CTC可以通过加入静音Label的方式,将分类问题转为转写问题。
“Attentive to Individual: A Multimodal Emotion Recognition Network with Personalized Attention Profile”结合了多模输入,使用Attention机制优化不同属性说话人(例如老人、儿童等情感表现方式不同的人群)的Emotion识别效果。
02
这部分带来的是:9月17日主会议第二天上的说话人识别,语音识别,语音合成,语音翻译这四个方面的解读。
说话人识别
说话人方向的Session相当集中,并且领域涉及广泛。
从当日上午的“Speaker Recognition 1”,到下午的“Speaker and Language Recognition 1 ”、“ Speaker Recognition Evaluation”,以及Special Session“ASVspoof 2019 Challenge”、“DIHARD II Challenge”,涵盖说话人验证/识别、切分及反作弊等方向。Survey Talk由昆山杜克大学的李明教授带来,详细介绍了说话人技术从GMM时代一路走来的演进历程。
(PPT可登陆 http://sites.duke.edu/dkusmiip 查看)
说话人技术经历深度学习带来的性能飞跃后,在模型结构、损失函数等方面的探讨已经较为成熟,以TDNN、ResNet加上LMCL、ArcFace的主流模型开始不断刷新各数据集的性能上限。
此时,模型以外的因素逐渐成为制约说话人系统的瓶颈。
本届Interspeech中,研究者们尝试进一步探讨提升训练效率的方式,如“Multi-Task Learning with High-Order Statistics for x-Vector Based Text-Independent Speaker Verification”尝试使用MTL有效利用无监督数据;“Data Augmentation Using Variational Autoencoder for Embedding Based Speaker Verification”使用VAE替代GAN生成说话人嵌入以增强PLDA性能。
模型方向的研究,除了对现有模型结构的继续探索和不断完善,“RawNet: Advanced End-to-End Deep Neural Network Using Raw Waveforms for Text-Independent Speaker Verification”这篇颇有意思,探索直接从Raw Waveform进行说话人识别。在论文中作者并没有对比SincNet,而在QA环节中提到RawNet比SincNet性能更好。
当然,说话人技术目前也逐渐暴露出与人脸识别同样的易受攻击的问题。因此,ASVspoof这样的Challenge从2015年起就开始关注声纹反作弊问题。相信随着此类研究的不断深入,结合声纹系统的性能提升,声纹将有望变成我们的“声音身份证”。
语音识别
针对语音识别方向,9月17日有好几个相关的session,涵盖了非常丰富的语音识别的各个方向,例如远场语音识别(far-field ASR),模型结构(ASR network architecture),模型训练(model training for ASR),跨语种或者多语种语音识别(cross-lingual and multi-lingual ASR)以及一些端到端语音识别(end-to-end ASR)等。
在这里只是简单选取了几篇文章与大家分享。
首先Cambridge和RWTH的研究者在论文Multi-Span Acoustic Modelling using Raw Waveform Signals展现了其在基于原始waveform数据上直接进行ASR声学建模的探索。目前主流的语音识别系统的输入特征一般都是基于FBANK实现的,研究者们也一直在探索如何能够基于最原始的输入以达到更好的结果。在该论文中,Multi-Span结构的CNN作为了抽取特征的基本方案,其中可以认为是采用了不同时间尺度分辨率的CNN结构来捕捉waveform中的相关信息,某种程度上与基于多个频率子带的FBANK有相通之处。

该论文在CHiME4和AMI 两个数据库上做了实验,取得了相对FBANK较好的结果。回过头来看,从最初Deep Learning引入到语音识别后,研究者们就都一直在探索着End-to-end的主题:在靠近输出端,从HMM结构,到CTC结构,再到Sequence-to-Sequence结构;在靠近输入端,从MFCC特征,到FBANK特征。虽然FBANK是一个handcrafted的特征,但依然是目前大部分系统的主流,因而近几年一直都会有相关论文在探索如何使得waveform直接作为输入特征。
微软的研究者们在论文Acoustic-to-Phrase Models for Speech Recognition中探讨了将短语作为ASR声学建模的相关实验结果。随着端对端建模方法的普及,更大尺度的建模单元在一些情况下也逐步呈现出了更好的识别性能。回顾来看,从最初的CD-Phone,到后来sub-words,再后来word,乃至于这篇论文中所探讨的phrase。

从论文结果中可以看到一个非常有意思的点,在采用Phrase作为建模单元时,CTC算法并没有能够学习到较好的性能,而Sequence-to-Sequence结构却能够学习到一个比较稳定的性能。
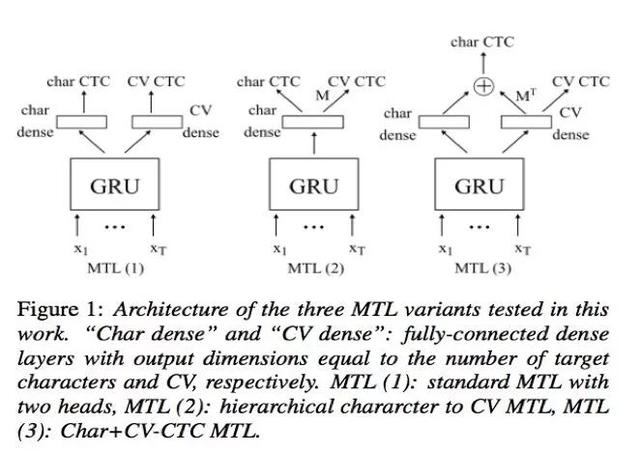
来自IRIT的Abdelwahab Heba等人在文章“Char+CV-CTC: combining graphemes and consonant/vowel units for CTC-based ASR using Multitask Learning”中,使用多任务学习的方法,同时使用字位和CV来作为CTC模型的建模单元。并在论文中采用了3种方法来使用这两种建模单元进行多任务学习。实验结果表明,这种ASR训练方法能有效地提升识别精度。

在多语种ASR任务上,Google的Anjuli Kannan等人在文章“Large-Scale Multilingual Speech Recognition with a Streaming End-to-End Model”中提出了一种流式的多语种识别系统。
该系统基于RNN-T模型,探索了加入语言相关向量、数据采样、转换等各种方法。最终在各语种的语音识别率上都取得了极大的提升。

语音合成
今年的Interspeech上,端到端TTS继续是语音合成方向研究的主流和热点。
中科院的Yibin Zheng等人在“Forward-Backward Decoding for Regularizing End-to-End TTS”中,创新性的提出了一种在Decoder部分使用前向-后向解码的方法。
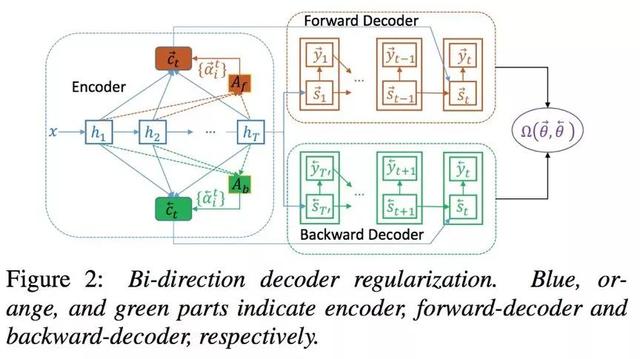
此方法在训练过程中,Encoder的信息同时输入前向和后向两个Decoder,同时联合前后向两个Decoder的输出来控制训练。而在推理阶段,只需要使用其中一个Decoder的输出信息。实验结果表明,此方法能较好的提升合成语音质量。

BME的Sevinj Yolchuyeva等人的工作“Transformer based Grapheme-to-Phoneme Conversion”,使用Transformer来构建语音合成文本分析模块G2P(Grapheme-to-Phoneme)。

该端到端Transformer G2P模型不仅能取得更好的精度,并且具有模型小、效率高等特点。

语音翻译
语音翻译也是今年Interspeech重点关注的方向之一。语音翻译(Speech Translation)包括语音到文本的翻译,语音到语音的翻译两个子任务。在此次会议上,端到端的语音翻译的方法成为了新的研究热点,其性能已经接近基于Cascade的方法。
Maastricht University的Jan Niehues带来了语音到文本翻译的综述,首先介绍了语音翻译的应用场景和技术难点,然后介绍了常见的基于Cascade(语音到文本的识别,文本到文本的翻译)的语音翻译的方法,以及端到端的语音翻译的方法。
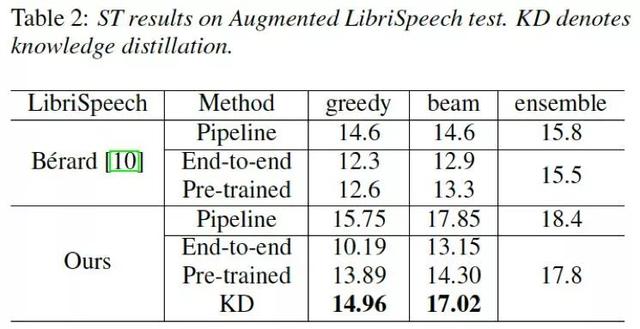
百度和中科院自动化所的研究者在“End-to-End Speech Translation with Knowledge Distillation”提出通过知识蒸馏(Knowledge distillation)来迁移预训练的文本翻译模型,从而提高端到端语音翻译的方法。该方法在LibriSpeech数据集上相比其他算法提升了3.7的BLEU值。
来自Google的Ye Jia等人在“Direct speech-to-speech translation with a sequence-to-sequence model”中,提出了基于sequence-to-sequence框架的语音到语音的翻译模型。通过实验发现,该方法在Fishers数据集上取得了接近基于Cascade的方法(语音到文本的翻译,文本到语音的合成)的性能。

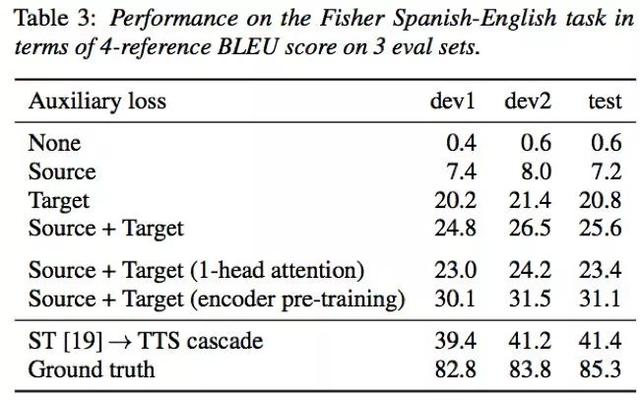

03
这部分带来的是:9月18日上的语音识别,说话人识别,语音模型这三个方面的解读
语音识别
9月18日的语音识别相关Session涵盖了模型训练(Training),结构(NN Architecture),特征(Feature Extraction)以及系统(Rich Transcription and Systems)等。
在NN Architecture中,Google的研究者们在论文Two-pass End-to-End Speech Recognition中提出了一个Two-pass的语音识别结构。
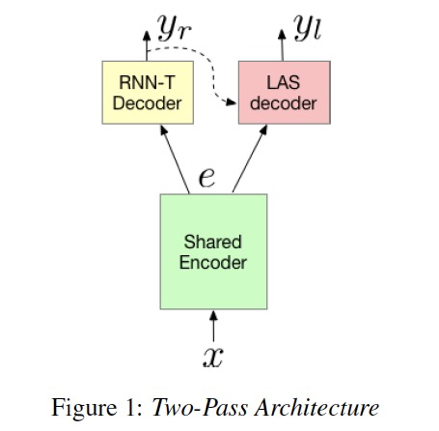
在该结构中,有一个RNN-T结构完成第一遍的解码,而外又加入了LAS作为第二遍解码(Rescoring)。在论文的实验结果中,对比了Finetune对模型的性能影响,对比了Rescoring的带来的收益,对比了二遍解码时N-best Rescoring和Lattice Rescoring所带来的解码延时的差异,对比了二遍解码时Beam Size对性能的影响,此外也验证了MWER的区分度训练对系统的性能提升。
该论文中的工作关注的是如何搭建一个性能较好的端对端流式的且低延时的语音识别系统,所以在论文中还专门与Google的另外一个LFR的系统性能做了Side-by-side的人工标注对比。从整篇论文中,可以看到,通过引入的这个LAS,论文中的结果也展现出了基于RNN-T系统显著的性能提升,但依然还有很多细节值得进一步探索。
此外,在主会第二天的论文中有一篇工作和Two-pass end-to-end speech recognition工作有一些相似点,也就是来自Alibaba的研究者们的论文Investigation of Transformer based Spelling Correction Model for CTC-based End-to-End Mandarin Speech Recognition。在该论文中,在CTC一遍解码之后,加入了一个Transformer网络实现rescoring。

该工作中,两遍解码的神经网络模型相对独立。第二遍解码(Speller)时,直接以一遍解码的Nbest作为输入,标注文本作为输出。这个Speller更像是一个基于Nbest结果的纠错系统,而不是rescoring。
在9月18日语音识别特征研究的Session中,来自Facebook的研究者们发表了论文wav2vec: Unsupervised Pre-training for Speech Recognition。该论文和很多其他论文一样,很早以前就已经放到了arxiv平台上,现场在作者展示该论文工作时也得到很多的关注。
论文中的idea比较直接,也期望像在NLP领域一样,无监督地学习到一个embedding,作为在特定任务中的模型训练时的Pretraining。在该论文中,引入了一个相对简单的模型结构来实现pretraining,并在在WSJ和TIMIT两个任务中,都展示出基于Librispeech数据库做的Pretraining能带来一定程度的性能提升。
Google的Daniel S. Park等人的文章“SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition”提出了一种可广泛应用于语音识别任务的简单有效的数据增强方法。

论文中提出了时间弯折、频域掩蔽、时间维度上掩蔽、频率维度上掩蔽等方法。

该方法在LibriSpeech和Switchboard等识别任务上大幅提升了语音识别率。

LEAP的Purvi Agrawal等人的文章“Unsupervised Raw Waveform Representation Learning for ASR”提出了一种无监督的语音表示学习方法。

该系统基于原始波形使用CVAE来学习声学滤波器组,同时通过调制滤波层调制滤波器。此系统采用数据驱动的方法,学习到数据和任务相关的特征表示,得到的特征更能体现数据的特性。在干净及带噪等各种场景下识别性能都有大幅度的提升。
说话人识别
深度学习为说话人技术带来了前所未有的机遇,而研究者们在不断拓展新算法的边界的同时,也在回顾传统方法仍然具备的价值。
在18日的说话人session中,涌现出了许多诸如“Large Margin Softmax Loss for Speaker Verification”、“Deep Speaker Embedding Extraction with Channel-Wise Feature Responses and Additive Supervision Softmax Loss Function”等研究说话人模型与损失函数的工作,大多基于最近比较火的各种Margin Loss。
其中“Large Margin Softmax Loss”这篇研究使用AMSoftmax,在一个公式中统一了多种margin项:

其中不同的margin定义为:
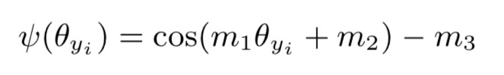
并引入两种辅助损失:Ring Loss来约束embedding模值;MHE使weight尽可能在超球面中均匀分布,从而提升类间可分性。研究在Kaldi VoxCeleb Recipe的基础上得到了EER 2.00的显著性能提升:

“Tied Mixture of Factor Analyzers Layer to Combine Frame Level Representations in Neural Speaker Embeddings”这篇也值得一看:在Statistical Pooling与Attention大行其道的当下,使用看起来很复古的因子分解Pooling层实在有趣。论文解决的关键问题是如何让该层可导。
诚然,经典的i-vector算法在性能上已然锋芒不再,但其在训练UBM、TVM时可以使用无标注数据的优势依然是相比深度模型的一大优势。“Self-supervised speaker embeddings”试图为深度模型带来处理无标注数据的能力。通过加入一个辅助模型,借助ASR系统输出的音子串来重构输入特征,使模型能够在少量甚至完全没有说话人标注的情况下依然具备区分性。模型结构如下:

这篇研究与9月17日(昨日)的“Multi-Task Learning with High-Order Statistics for x-Vector Based Text-Independent Speaker Verification”思路相似,虽然后者用MTL重构特征统计量而非原始特征,但仍可谓异曲同工。此外,音子信息一直是说话人技术中的重要特征之一,从DNN-ivector到昨日的“On the Usage of Phonetic Information for Text-independent Speaker Embedding Extraction”,以及这篇研究,研究者们也在探索更充分利用音子信息的方法。
在算法研究之余值得注意的是,随着欧盟GDPR对互联网产业影响的不断加深,以及人们对个人隐私保护意识的逐步强化,本届Interspeech也探讨了在说话人识别技术中如何保护个人隐私。
第二部分的综述“Survey Talk: Preserving Privacy in Speaker and Speech Characterisation”,及本部分的“Privacy-Preserving Speaker Recognition with Cohort Score Normalisation”,无不在强调这一点。
语言模型
在此次会议上,语言模型(Language Model)的研究热点主要包括NLP模型的迁移,低频单词的表示,以及深层Transformer等。
ESAT – PSI和苹果的研究者在“Reverse Transfer Learning: Can Word Embeddings Trained for Different NLP Tasks Improve Neural Language Models?”分析迁移不同的NLP模型对于语言模型的性能的影响,实验结果表明迁移任务相似的NLP模型(word2vec,双向语言模型)性能最好。

南洋理工大学的研究者在“Enriching Rare Word Representations in Neural Language Models by Embedding Matrix Augmentation”提出用语义和语法相似的单词的词向量来表示低频单词。该方法在在ASR数据集(新加坡-英语)取得了最好的结果。

亚琛工业大学的研究者在“Language Modeling with Deep Transformers”分析基于深层自回归的Transformer的语言模型性能,实验结果表明其性能(PPL,WER)是优于基于LSTM的语言模型。

编辑 | 唐里
滴滴科技合作 | 龚诚
技术鸣谢 | 滴滴AI Labs - 李先刚,邹伟,彭一平,徐海洋
![]()

2019深度学习语音合成指南