自动驾驶数据集被迫开放“营业”
“现在自动驾驶很火,火到什么程度?简单来说就是烧钱。”
根据The Information发布最新研究称,投入自动驾驶战场的各家公司已经累计花掉了约160亿美元。需要注意的是,这160亿美元还没算上为了自动驾驶布局而发生的并购。举例来说,英特尔买下Mobileye花掉的153亿美元就不算在其中。
众所周知,自动驾驶技术相当复杂,想要实现商用,花费的时间和成本对于任何一家车企或者科技公司来说都是巨大的,这些投资想要得到回报则需要更长的时间。而且自动驾驶所谓的商业化,还在探索当中。无论是推出RoboTaxi服务的Waymo One,或者是Nuro与Kroger合作的生鲜配送,又或者是安波福和Lyft推出的乘车服务等等。

那么,为了打破各家企业各自为战的局面,一些企业彼此开始尝试开放有价值的自动驾驶数据集,以加快自动驾驶技术的提升,从而推动自动驾驶行业的发展。去年,谷歌母公司Alphabet旗下自动驾驶公司Waymo公开了一部分开放数据集Waymo Open Dataset;近期福特也悄悄发布了其自动驾驶汽车数据集。
这两家自动驾驶公司,是目前公认的在全球自动驾驶研究排名前列的企业。对于自动驾驶行业其他从业者而言,有了公开的数据集,他们能在一定程度上免去重复的资源投入。研发人员可以利用这些数据集来帮助开发自动驾驶汽车的感知算法,有助于推动其研发进程。实际上,这也是一场自动驾驶行业领导者地位的争夺。
什么样的数据有价值?
自动驾驶汽车每天可以收集4TB或更多的原始传感器数据,直到现在,自动驾驶公司收集的数据还是公司的高度机密。但是近几年,自动驾驶领域的各路参与者,在开源数据集共享这件事上颇为“大方”。
在福特的自动驾驶数据集发布之前,Lyft 此前也开源了自己的数据集用于自动驾驶汽车开发。其他开放此类的数据还包括nuScenes、Mapillary Vistas的街道图像集、加拿大不利驾驶条件(CADC)、KITTI用于自动驾驶的研究;以及戴姆勒、马克斯·普朗克(Max Planck)信息学研究所和达姆施塔特工业大学(TU Darmstadt)视觉推断小组开发和维护的Cityscapes数据集。
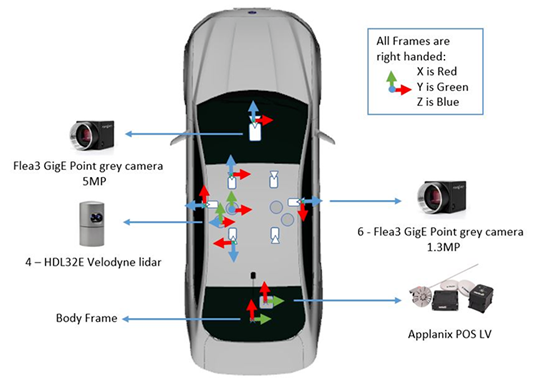
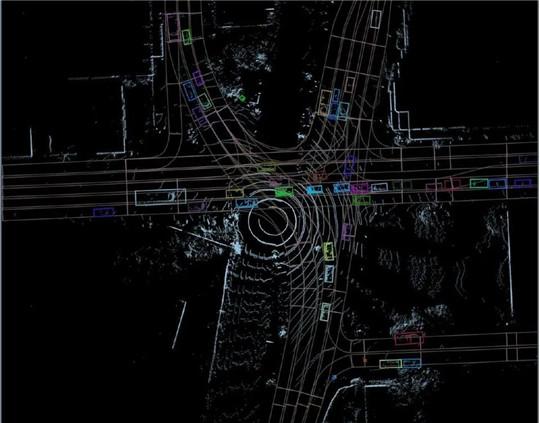
不过问题在于,过去相关研究人员创建和发布的数据集相对较小,通常仅限于摄像头数据。虽然,安波福发布的NuScenes数据集除图像外还包括激光雷达的雷达数据,Waymo和Argo发布的版本会更进一步。Waymo声称拥有3,000个场景,是NuScenes提供的场景的三倍,并且摄像头和激光雷达信息之间的同步更好。
虽然由自动驾驶测试生成的所有数据对于车辆感知其周围环境,并在整个过程中都是有用的,但实际上只有其中的特定部分对开发和改进系统有用。比如在典型城市街道上一天的测试中,车辆中的工程师和技术人员会选择性的记录发生细微变化或具有挑战性的场景。也就是说自动驾驶数据集需要更加多样和精细化,对从业人员来说才有利用价值。
福特此次公开的自动驾驶数据集,是工程师驾驶配备了四个四核英特尔i7处理器和16GB RAM的汽车,往返底特律大都会机场、密歇根大学迪尔伯恩分校、高速公路、市中心和郊区等地区共行驶了约66公里。其数据主要由4个激光雷达传感器、6个130万像素摄像头、1个500万像素摄像头和1个惯性测量单元,通过路况的细微变化来捕获多样化的数据。

一般而言,在测试结束时,所有数据都将从车辆中提取到数据中心,并对有益的数据进行分析和标记。原始数据本身对于处理器系统核心的学习系统没有多大价值,数据中感兴趣的对象包括行人、骑自行车的人、动物、交通信号灯等变量。在将传感器数据用于训练或测试AI系统之前,所有这些目标都需要进行手工标记和注释,以便系统可以理解其“所见”。
研究人员根据传感器的读数生成地图和行人姿态数据,包括3D地面反射率地图、3D点云地图、六自由度地面真实姿态和局部姿态传感器信息。这些反映了季节差异(数据是在晴天、下雪和多云的情况下以及在秋季期间捕获),并且涵盖了多种驾驶环境,包括高速公路、立交桥、桥梁、隧道、建筑区域和植被覆盖区。
如今,大多数感知系统都严重依赖机器学习或深度核心算法,感知系统处理传感器信号并尝试对车辆周围的物体进行分类。为了能够完成此任务,必须使用经过彻底标记和注释标识所有道路的相关数据,才能更好的发挥出数据的价值。值得注意的是,标记过程可能比原始数据收集还要耗时。

福特指出,福特自动驾驶汽车数据集中的每个日志均带有时间水印,并包含来自传感器的原始数据、校准值、姿态轨迹、地面真实姿态和3D地图。它具有ROS bag文件格式,可使用开源机器人操作系统(ROS)对其进行可视化、修改和应用。
实际上是话语权的争夺
在自动驾驶汽车上投入了大量资金,福特仍然向研究人员免费提供它的自动驾驶汽车数据集,但实际上也有所保留。此次福特公开的包括Argo正在使用的所有九台摄像头的视图,以及两个带有10,000多个带注释目标的数据,但它仅涵盖迈阿密和匹兹堡记录的113个场景。
在自动驾驶技术发展的初期,企业对数据的所有权非常谨慎,各家收集的数据代表着它们的用户、资源和技术。技术垄断虽然能够最大限度地强化自己的优势,但同时也阻碍了技术的进步。虽然自动驾驶车辆数据共享的重要性得到了整个行业的认可,但出于行业竞争、产权保护等等方面的考虑,企业之间大概不会无私贡献所有数据。

事实上,开放数据集确实是在帮助别人,但企业自身也能获益。自动驾驶数据采集是一个周期长,地域广的长时间项目,如果各家都将自己的采集数据共享的话,就可以共同减少数据采集时间,从而促进行业的整体发展,促进商业化。
但实际情况是,在技术层面,对于一般研究而言,得到新的分类和预测算法可能具有巨大的价值。但由于具体数据取决于传感器规格及其在车辆上的位置,还有很多实际原因导致诸多数据无法获得。除非有人使用与捕获数据的原始车辆完全相同的配置,否则如果不对视差进行调整,它对于训练特定的自动驾驶系统可能没有用。
毫无疑问,公开数据集,可以吸引更多企业和开发者利用并补充数据集。如果某一家的数据或者代码被竞争对手采用,相当于这家公司为自动驾驶汽车制定了一个非正式的标准,有助于该企业的发展和地位的加强。这一开放数据的企业也可以将其他公司收购,或者收取利益许可其他企业使用该平台。
当前全球所有车企都将智能化转型作为战略来抢占技术的制高点,中国也不例外。2月份出台的《智能汽车创新发展战略》,对中国的自动驾驶来说具有重大利好。但是在回过头来看国外公司开放的自动驾驶数据集,主要针对底特律、波士顿、新加坡等地的环境解析。对于道路、交通、环境差别迥异的国内驾驶环境来说,是否有用还有待商榷。
不过国内的百度“Apollo”自动驾驶平台,也是通过开源代码,联合诸多车企达成合作。此外,小马智行和华为等中国公司,也在快速抢占自动驾驶市场的份额。2019年自动驾驶汽车脱离数据报告中,排名前十的企业中有四家来自于中国。由此可见,中外企业均在抢占自动驾驶各层面技术的标准制定和话语权。
随着“新四化”的不断深入,未来,可能还会有更多的玩家加入到自动驾驶的战场。历史也表明,未来也将是一个开放、合作、同时又相互竞争的局面。无论是传统车厂还是科技企业,无论是国内企业还是国外公司,这场承载着人类未来出行的伟大梦想,正在一步步走近。
文/杨晶
---------------------------------------------------------------------------
【微信搜索“汽车公社”、“一句话点评”关注微信公众号,或登录《每日汽车》新闻网了解更多行业资讯。】