Amazon Redshift数据迁移阿里云MaxCompute技术方案
1 方案概述
本文将介绍如何通过公网环境迁移Amazon Redshift数据到阿里云MaxCompute服务当中。
本方案的总体迁移流程如下:

第一, 将Amazon Redshift 中的数据导出到Amazon S3存储上;
第二, 借助阿里云在线迁移服务(Data Online Migration)从AWS S3将数据迁移到阿里云OSS上;
第三, 将数据从阿里云OSS加载到同Region的MaxCompute项目中,并进行校验数据完整性。
2 前提条件
· 准备Redshift的集群环境及数据环境;
使用已有的Redshift集群或创建新的Redshift集群:
**
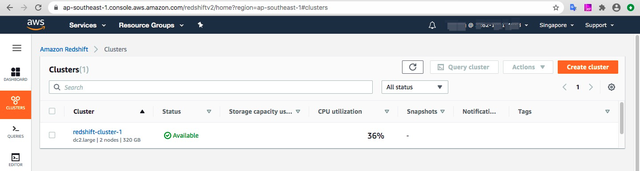
**
在Redshift集群中准备好需要迁移的数据,本方案中在public schema中准备了TPC-H数据集进行方案介绍:
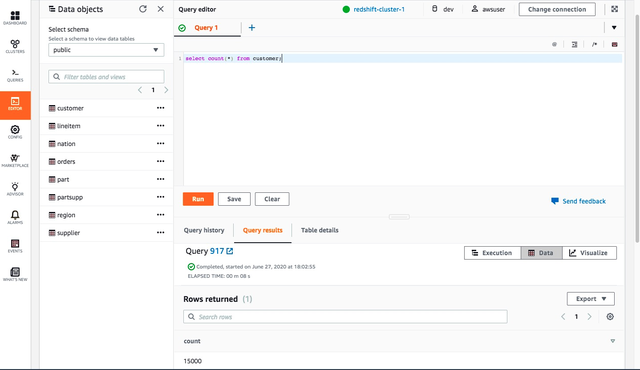
· 准备MaxCompute的项目环境;
在阿里云Region创建MaxCompute项目,这里以新加坡Region为例,创建了作为迁移目标的MaxCompute项目:
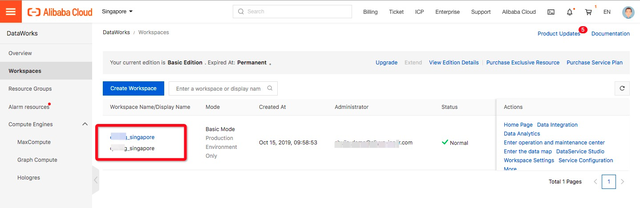
3 Redshift导出数据到S33.1 Unload简介3.1.1 命令介绍
AWS Redshift支持Role-based access control和Key-based access control两种认证方式实现Redshift UNLOAD命令写入数据到S3。
基于IAM Role的UNLOAD命令:
unload ('select * from venue') to 's3://mybucket/tickit/unload/venue_' iam_role 'arn:aws:iam::0123456789012:role/MyRedshiftRole';
基于access_key的UNLOAD命令:
unload ('select * from venue') to 's3://mybucket/tickit/venue_' access_key_id ''secret_access_key ''session_token '';
相关语法及说明可参考Redshift官方文档关于UNLOAD到S3的介绍。
本方案选择使用IAM Role方式进行数据导出。
3.1.2 默认格式导出unload默认导出数据的格式为 | 符合分隔的文本文件,命令如下:unload ('select * from customer')to 's3://xxx-bucket/unload_from_redshift/customer/customer_'iam_role 'arn:aws:iam::xxx:role/redshift_s3_role';
执行成功后,在S3对应的bucket目录下可以查到文件文件:
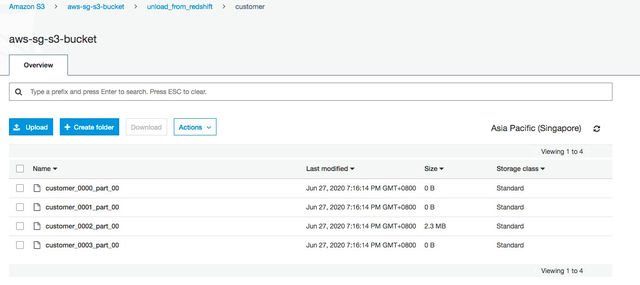
文件样例如下:

3.1.3 Parquet格式导出
Unload同时支持以Parquet格式导出到S3,便于其他分析引擎直接进行读取消费:
unload ('select * from customer')to 's3://xxx-bucket/unload_from_redshift/customer_parquet/customer_'FORMAT AS PARQUETiam_role 'arn:aws:iam::xxxx:role/redshift_s3_role';
执行成功后,s3对应bucket目录下生成了parquet格式的文件。
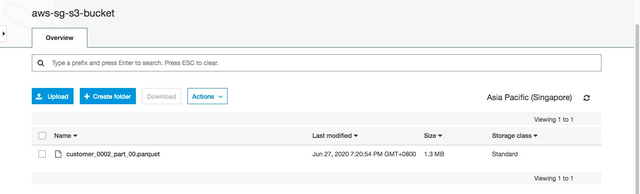
得益于Parquet文件的数据压缩特性,可以看到Parquet文件比文本文件大小更小,本方案选择Parquet格式作为数据导出和跨云迁移的数据格式。
3.2 创建可以读写S3的IAM 角色3.2.1 新建Redshift use case的IAM角色
进入https://console.aws.amazon.com/iam/home?region=ap-southeast-1#/roles(以新加坡Region为例)创建角色。
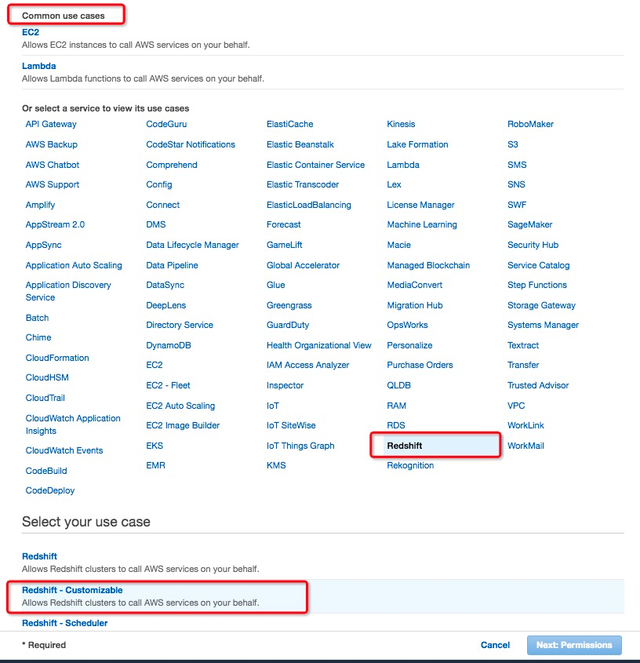
创建角色时,” Choose a use case”选择Redshift服务,并选择Redshift-Customizable的”use case”
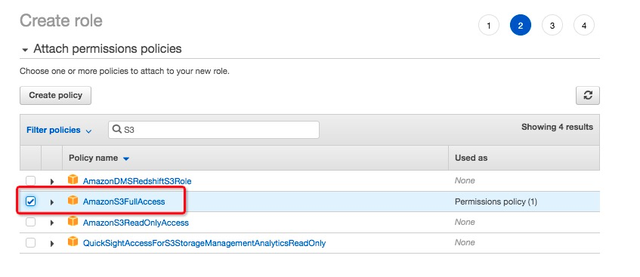
3.2.2 添加读写S3的权限策略
” Attach permissions policies”时,添加具备写S3的Policy,本方案选择使用” AmazonS3FullAccess”。
3.2.3为IAM Role命名并完成IAM 角色创建
本方案中命名为redshift_s3_role
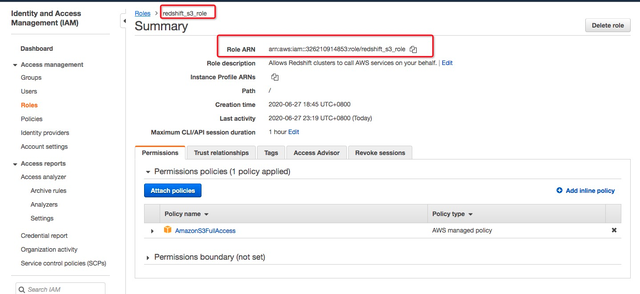
打开刚定义的role并复制角色ARN,unload命令将会使用该Role ARN访问S3.
3.2.4Redshift集群添加IAM Role以获取访问S3权限
进入Redshift集群列表,选择需要迁移的集群,在”Action”列表中选择”Manage IAM Role”菜单,进行IAM角色的关联。
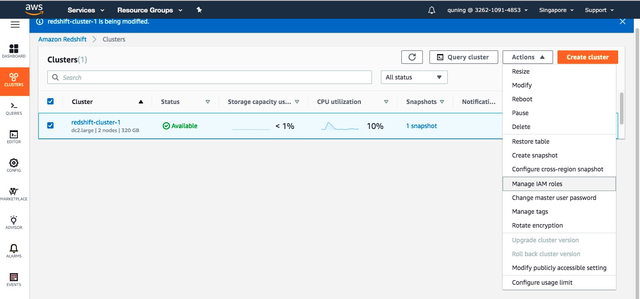
将已经成功创建的具备访问S3权限的IAM Role角色添加到集群可用IAM roles列表以获取Redshift对S3读写的权限并保存生效:
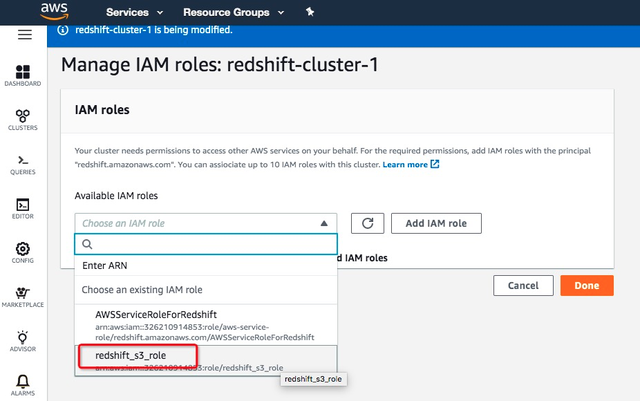
查看添加的IAM roles,确认集群已经添加了前文创建的redshift_s3_role角色。
3.3 卸载数据到Amazon S3
使用unload命令将Redshift数据库中需要迁移的表以Parquet格式导出到S3对应的目录下。
命令如下(需要替换目录及iam role信息):
`unload ('select * from customer') to 's3://xxx-bucket/unload_from_redshift/customer_parquet/customer_' FORMAT AS PARQUET iam_role 'arn:aws:iam::xxx:role/redshift_s3_role';``unload ('select * from orders') to 's3://xxx-bucket/unload_from_redshift/orders_parquet/orders_' FORMAT AS PARQUET iam_role 'arn:aws:iam::xxx:role/redshift_s3_role';``unload ('select * from lineitem') to 's3://xxx-bucket/unload_from_redshift/lineitem_parquet/lineitem_' FORMAT AS PARQUET iam_role 'arn:aws:iam::xxx:role/redshift_s3_role';``unload ('select * from nation') to 's3://xxx-bucket/unload_from_redshift/nation_parquet/nation_' FORMAT AS PARQUET iam_role 'arn:aws:iam::xxx:role/redshift_s3_role';``unload ('select * from part') to 's3://xxx-bucket/unload_from_redshift/part_parquet/part_' FORMAT AS PARQUET iam_role 'arn:aws:iam::xxx:role/redshift_s3_role';``unload ('select * from partsupp') to 's3://xxx-bucket/unload_from_redshift/partsupp_parquet/partsupp_' FORMAT AS PARQUET iam_role 'arn:aws:iam::xxx:role/redshift_s3_role';``unload ('select * from region') to 's3://xxx-bucket/unload_from_redshift/region_parquet/region_' FORMAT AS PARQUET iam_role 'arn:aws:iam::xxx:role/redshift_s3_role';``unload ('select * from supplier') to 's3://xxx-bucket/unload_from_redshift/supplier_parquet/supplier_' FORMAT AS PARQUET iam_role 'arn:aws:iam::xxx:role/redshift_s3_role';`
通过Redshift的Editor(客户端工具同样可以提交,客户端工具支持一次提交多行unload命令)提交导出数据到S3命令:
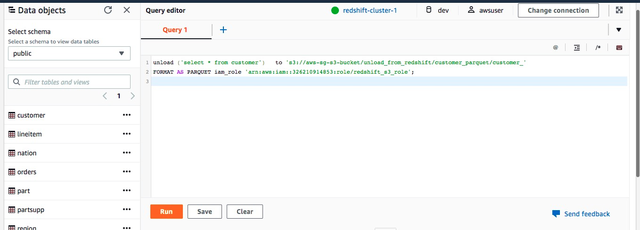
在S3对应的bucke目录下检查导出的数据:
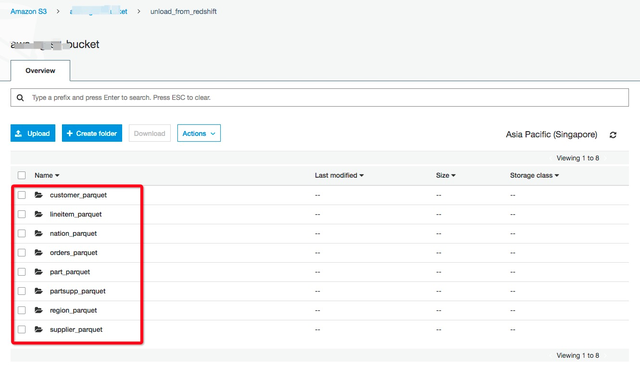
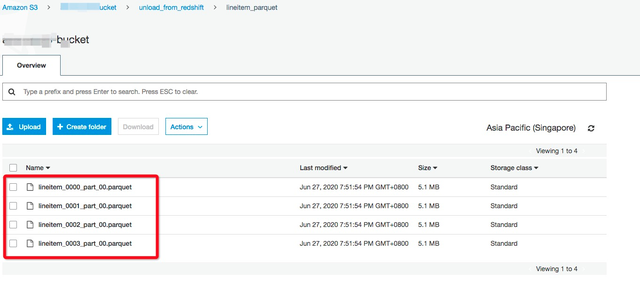
保存的格式为符合预期的Parquet格式:
4 迁移AWS S3数据到阿里云OSS4.1 在线迁移服务实现S3到OSS迁移
阿里云在线迁移服务支持迁移其他云厂商对象存储数据到阿里云OSS,其中对于在线迁移服务介绍以及S3到OSS的迁移介绍可以参考阿里云官方文档。
目前在线迁移服务处于公测状态,需要工单申请、开放后才可使用。
4.1.1 阿里云对象存储OSS准备
1.在阿里云侧,需要在目标region准备好需要保存迁移数据的OSS目录:
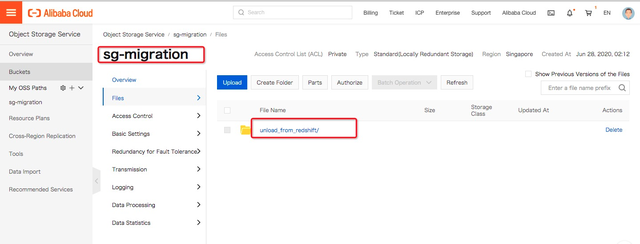
- 创建RAM子账号并授予OSS bucket的读写权限和在线迁移管理权限。
· 登录RAM 控制台。
· 在左侧导航栏,单击人员管理 > 用户 > 创建用户。
· 选中控制台密码登录和编程访问,之后填写用户账号信息。
· 保存生成的账号、密码、AccessKeyID 和 AccessKeySecret。
· 选中用户登录名称,单击添加权限,授予子账号存储空间读写权限(AliyunOSSFullAccess)和在线迁移管理权限(AliyunMGWFullAccess)。
· 授权完成后,在左侧导航栏,单击概览 > 用户登录地址链接,使用刚创建的 RAM 子账号的用户名和密码进行登录。
4.1.2 AWS侧准备可编程访问S3的IAM账号
· 预估迁移数据,进入管控台中确认S3中有的存储量与文件数量。
· 创建编程访问S3的IAM账号
1.进入IAM,选择创建用户。
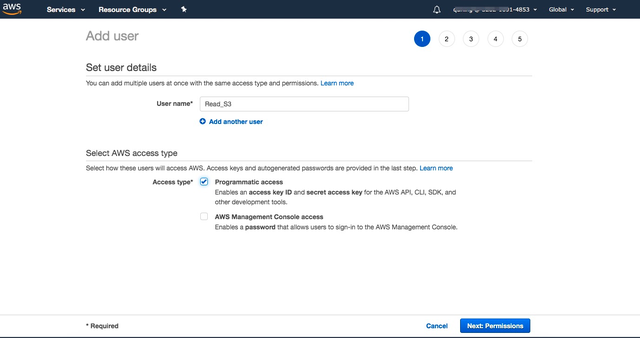
2.为新建用户添加读取S3的权限
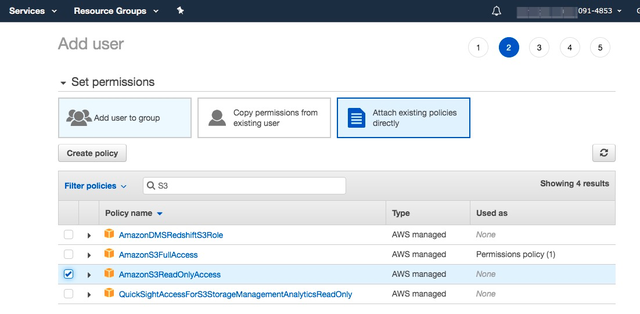
赋予AmazonS3ReadOnlyAccess权限。
3.记录AK信息,在数据迁移中会用到。
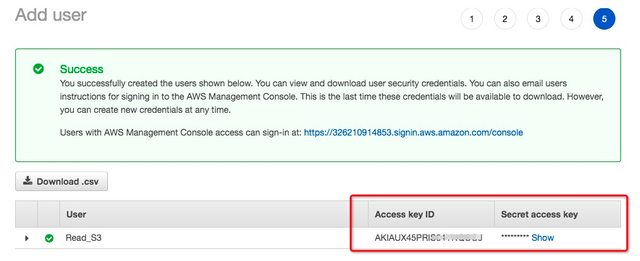
4.1.3 创建在线迁移任务4.2 使用在线迁移服务迁移数据
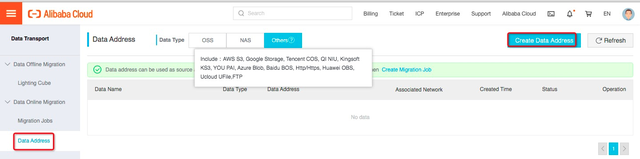
进入OSS web-console页面,进入对象存储的”数据导入”功能菜单:
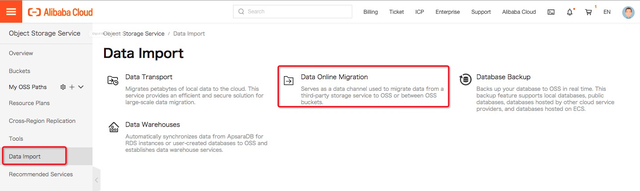
点击”Data Online Migration”菜单,进入在线数据迁移工具页面:
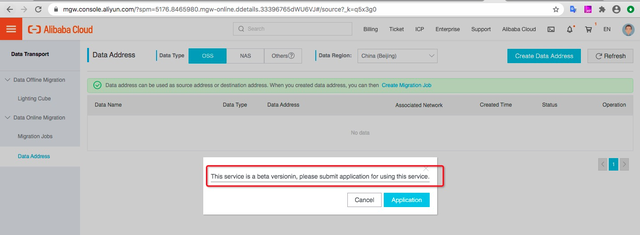
公测期间如未开通,需要填写申请表单进行申请,开通后可使用在线迁移服务。
开通后,按以下步骤创建在线数据迁移任务。
4.2.1定义源数据地址和目标数据地址
进入数据地址(“Data Access”)页面,点击”创建数据地址(Create Data Access)”按钮,开始创建源和目标数据源。
【创建源地址:】
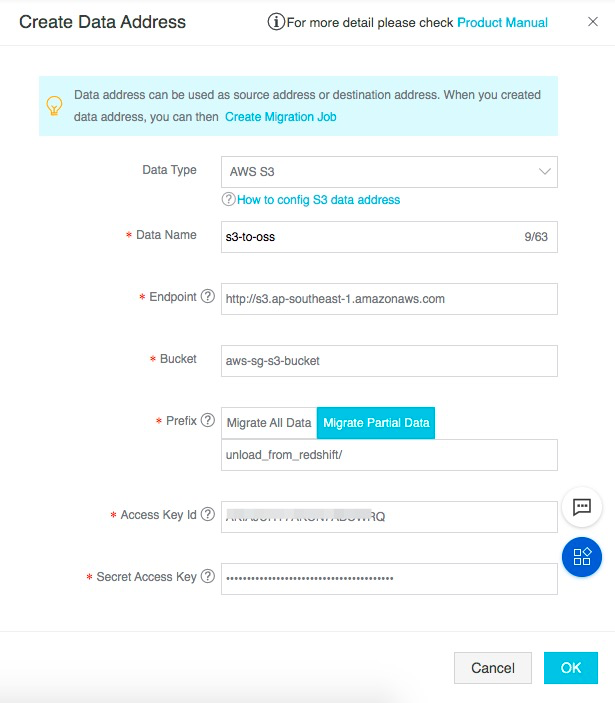
其中:
· 数据类型选择:AWS-S3
· Data Name:填写数据源的别名
· Endpoint:填写S3的Endpoint(Endpoint选择参考)
· Bucket:填写从Redshift unload到S3所在的bucket名称
· Prefix:本方案中将所有Redshift数据导出到同一个目录unload_from_redshift下,填写该目录,迁移该目录下所有数据
· Access Key Id:填写具备访问AWS S3该Bucket目录权限的账号的Access Key Id(使用前文提到的AWS侧可编程访问的IAM账号身份)
· Secret Access Key: 填写具备访问AWS S3该Bucket目录权限的账号的Secret Access Key(使用前文提到的AWS侧可编程访问的IAM账号身份)
保存数据源定义:
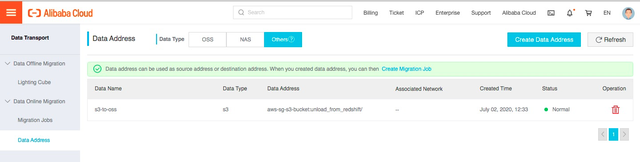
【创建目标地址:】
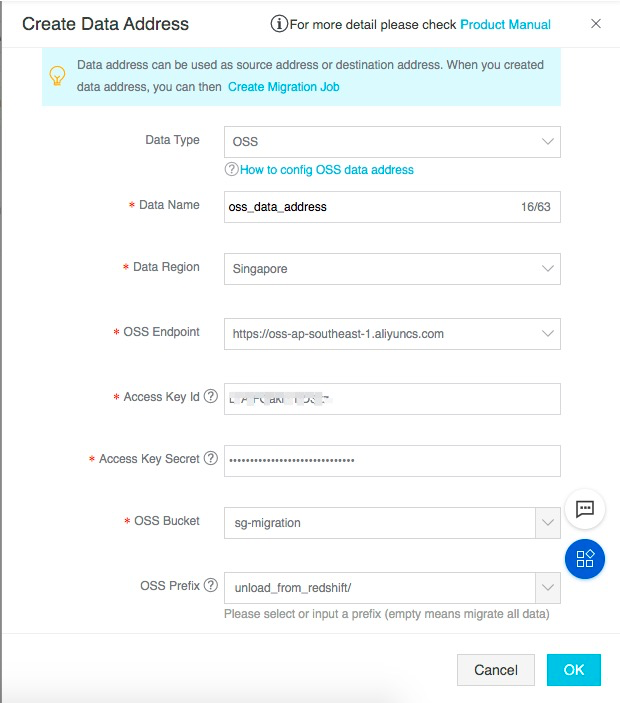
其中:
• 数据类型选择:OSS
• Data Name:填写数据源的别名
• Endpoint:填写oss的Endpoint
• Bucket:填写迁移目标的OSS的bucket名称
• Prefix:填写迁移目标bucket,本方案将迁移数据写入unload_from_redshift下
• Access Key Id:填写具备访问OSS该Bucket目录权限的账号的Access Key Id(使用前文提到的阿里云对象存储OSS准备章节中的账号身份)
• Secret Access Key: 填写具备访问OSS该Bucket目录权限的账号的Secret Access Key(使用前文提到的阿里云对象存储OSS准备章节中的账号身份)
保存数据源定义:
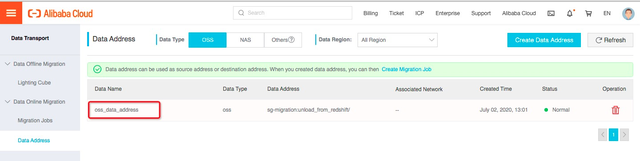
4.2.2创建迁移任务
从左侧tab页面中找到迁移任务,并进入页面,点击创建迁移任务。
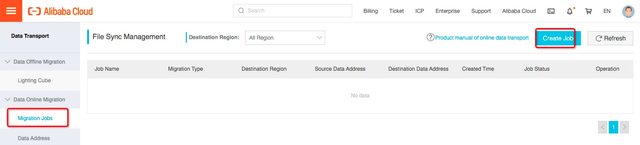
定义迁移任务的任务信息:
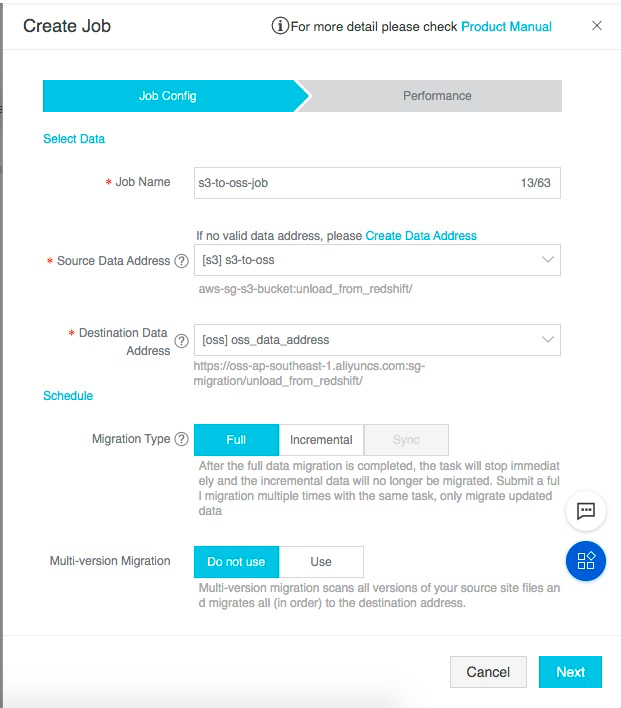
· 源数据地址填写已经定义的s3数据源;
· 目标地址填写已经定义的oss数据源;
· 本次选择全量迁移的迁移类型;
点击Next,定义作业传输性能相关参数:
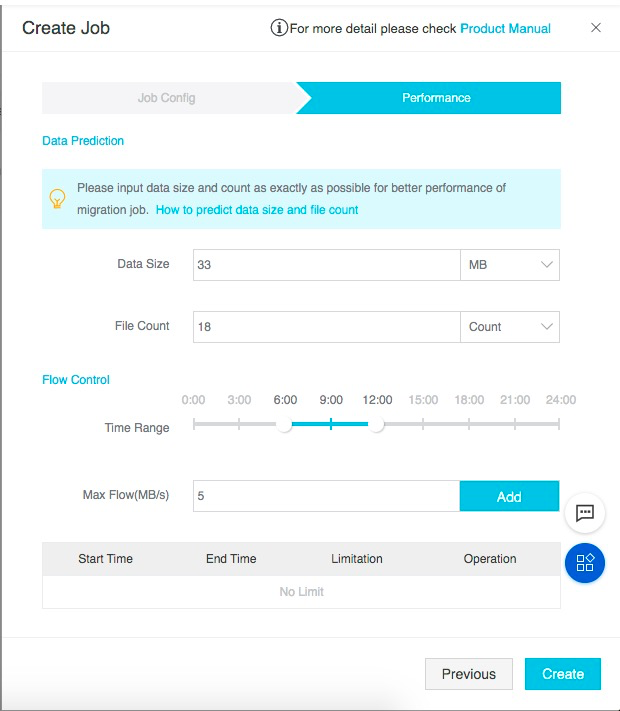
这里需要填写迁移的数据大小和文件个数。可通过S3的控制台,右键查看目录的属性,获取迁移目录的数据大小和文件个数并填写到作业参数当中。
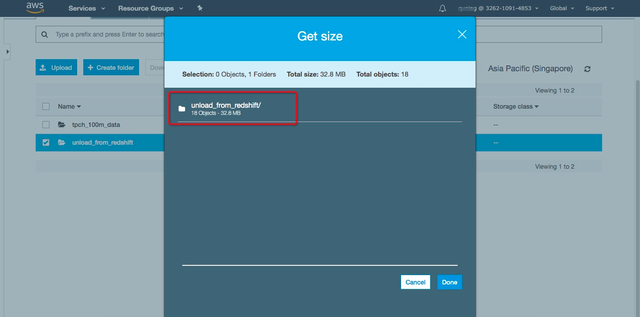
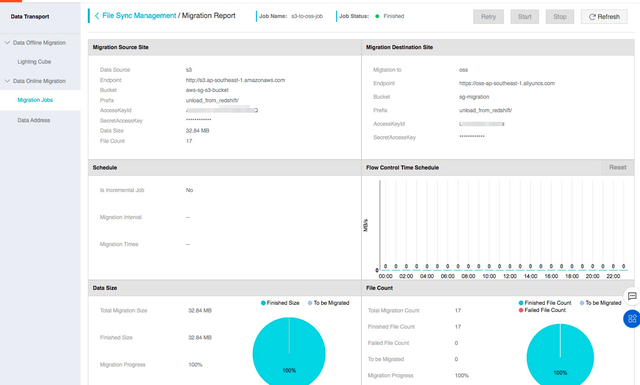
完成迁移任务创建后,可在迁移任务列表中查看已经创建好的迁移作业:
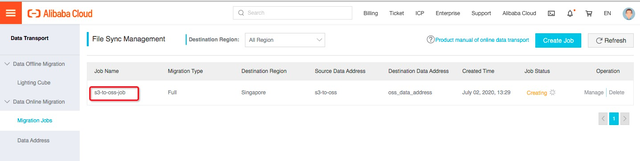
作业提交后会在自动运行,通过查看Jobe Status查看作业状态,Finished代表迁移任务成功结束。
点击作业的”Manage”按钮可以查看作业运行情况。
进入到目标OSS的目录,查看数据迁移的结果。
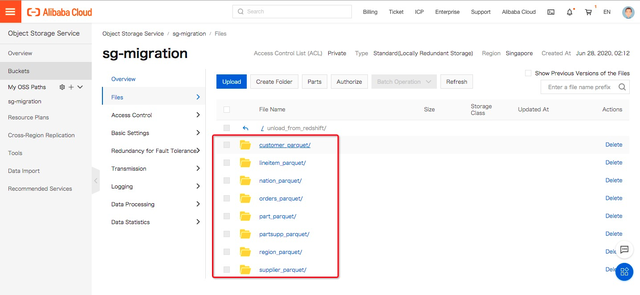
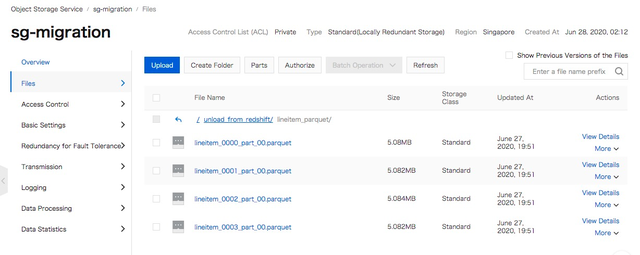
目录及文件全部已从S3迁移到OSS。
5 MaxCompute直接加载OSS数据
通过在线迁移服务,我们将AWS Redshift的导出的数据从S3迁移到了阿里云OSS,下面将利用MaxCompute LOAD命令将OSS数据加载到MaxCompute项目中。
5.1 创建MaxCompute Table
在DataWorks临时查询界面或MaxCompute命令行工具odpscmd中,使用Redshift集群数据的DDL在MaxCompute中创建对应的内表。
示例如下:
--MaxCompute DDLCREATE TABLE customer(C_CustKey int ,C_Name varchar(64) ,C_Address varchar(64) ,C_NationKey int ,C_Phone varchar(64) ,C_AcctBal decimal(13, 2) ,C_MktSegment varchar(64) ,C_Comment varchar(120) ,skip varchar(64)); CREATE TABLE lineitem(L_OrderKey int ,L_PartKey int ,L_SuppKey int ,L_LineNumber int ,L_Quantity int ,L_ExtendedPrice decimal(13, 2) ,L_Discount decimal(13, 2) ,L_Tax decimal(13, 2) ,L_ReturnFlag varchar(64) ,L_LineStatus varchar(64) ,L_ShipDate timestamp ,L_CommitDate timestamp ,L_ReceiptDate timestamp ,L_ShipInstruct varchar(64) ,L_ShipMode varchar(64) ,L_Comment varchar(64) ,skip varchar(64));CREATE TABLE nation(N_NationKey int ,N_Name varchar(64) ,N_RegionKey int ,N_Comment varchar(160) ,skip varchar(64));CREATE TABLE orders(O_OrderKey int ,O_CustKey int ,O_OrderStatus varchar(64) ,O_TotalPrice decimal(13, 2) ,O_OrderDate timestamp ,O_OrderPriority varchar(15) ,O_Clerk varchar(64) ,O_ShipPriority int ,O_Comment varchar(80) ,skip varchar(64)); CREATE TABLE part(P_PartKey int ,P_Name varchar(64) ,P_Mfgr varchar(64) ,P_Brand varchar(64) ,P_Type varchar(64) ,P_Size int ,P_Container varchar(64) ,P_RetailPrice decimal(13, 2) ,P_Comment varchar(64) ,skip varchar(64));CREATE TABLE partsupp(PS_PartKey int ,PS_SuppKey int ,PS_AvailQty int ,PS_SupplyCost decimal(13, 2) ,PS_Comment varchar(200) ,skip varchar(64));CREATE TABLE region(R_RegionKey int ,R_Name varchar(64) ,R_Comment varchar(160) ,skip varchar(64));CREATE TABLE supplier(S_SuppKey int ,S_Name varchar(64) ,S_Address varchar(64) ,S_NationKey int ,S_Phone varchar(18) ,S_AcctBal decimal(13, 2) ,S_Comment varchar(105) ,skip varchar(64));
本文的TPC-H数据集需要使用MaxCompute2.0数据类型和Decimal2.0数据类型,在创建数据表前需要检查并设置使用2.0数据类型:
setproject odps.sql.type.system.odps2=true;
setproject odps.sql.decimal.odps2=true;
5.2 LOAD命令加载OSS数据到MaxCompute表5.2.1 创建具备访问OSS权限的Ram Role
LOAD命令支持STS认证和AccessKey认证两种方式,AccessKey方式需要使用明文AccessKey/ AccessKey Secret,例如:
LOAD overwrite table ordersfrom LOCATION 'oss:// :@oss-ap-southeast-1-internal.aliyuncs.com/sg-migration/unload_from_redshift/orders_parquet/'ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'STORED AS PARQUET;
STS授权认证不暴露AccessKey信息,使用更安全,本方案将使用STS方式满足MaxCompute加载OSS数据的跨服务授权需要。
使用STS认证方式加载OSS数据前,您需要:
1.创建可以读取OSS的阿里云RAM Role
在查询OSS上数据之前,需要对将OSS的数据相关权限赋给MaxCompute的访问账号,授权详见授权文档。
本方案中创建了具备” AliyunOSSFullAccess”权限policy的ram角色。
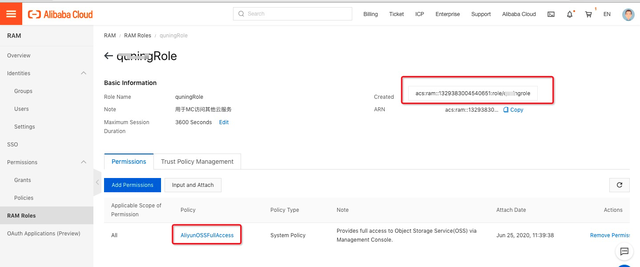
编辑配置该ram角色的信任策略,允许MaxCompute服务(Service:odps.aliyuncs.com)可以扮演使用该角色。
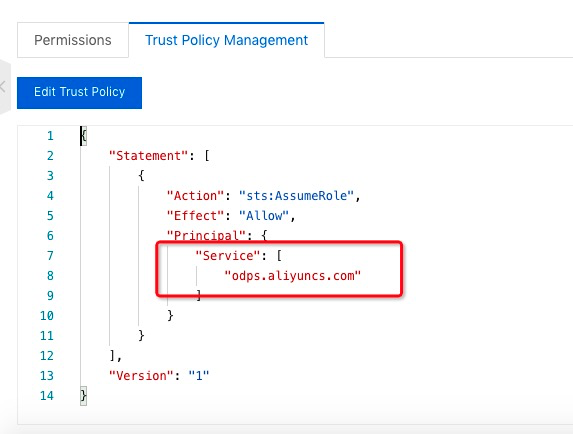
5.2.2 通过LOAD命令加载数据
MaxCompute提供了LOAD命令,通过LOAD命令可实现OSS数据加载到MaxCompute内表的功能。
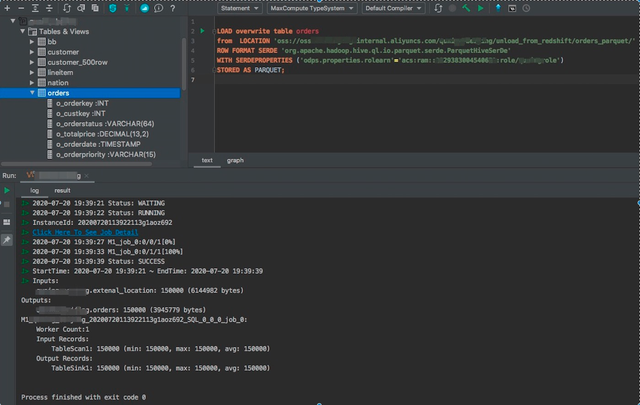
LOAD overwrite table orders`from LOCATION 'oss://endpoint/bucket/unload_from_redshift/orders_parquet/'ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'WITH SERDEPROPERTIES ('odps.properties.rolearn'='acs:ram::xxx:role/xxx_role')STORED AS PARQUET;
其中:
· 'odps.properties.rolearn'使用前文创建的ram角色的arn
· STORED AS PARQUET:OSS的文件为Parquet格式,使用STORED AS PARQUET申明导入格式为Parquet。
导入成功后,可以通过SQL命令查看和校验数据导入结果:
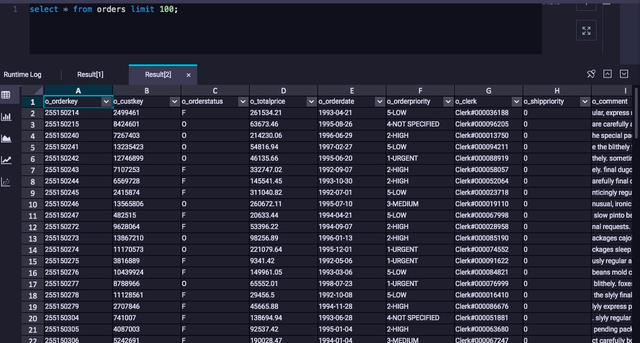
通过执行多个LOAD脚本方式将OSS的全部数据迁移到MaxCompute项目中。
6 数据核完整性与正确性核对
您可以通过表的数量、记录的数量、典型作业的查询结果来校验迁移到MaxCompute的数据是否和Redshift集群的数据一致。以典型作业举例如下。
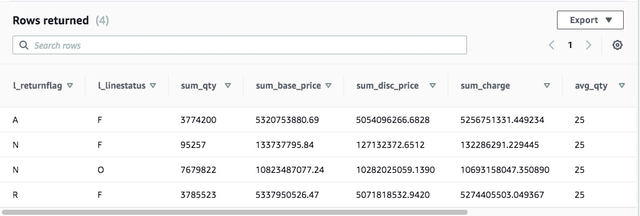
6.1 在Redshift集群中运行查询作业select l_returnflag, l_linestatus, sum(l_quantity) as sum_qty,sum(l_extendedprice) as sum_base_price, sum(l_extendedprice*(1-l_discount)) as sum_disc_price,sum(l_extendedprice*(1-l_discount)*(1+l_tax)) as sum_charge, avg(l_quantity) as avg_qty,avg(l_extendedprice) as avg_price, avg(l_discount) as avg_disc, count(*) as count_orderfrom lineitemgroup by l_returnflag, l_linestatusorder by l_returnflag,l_linestatus;
查看结果
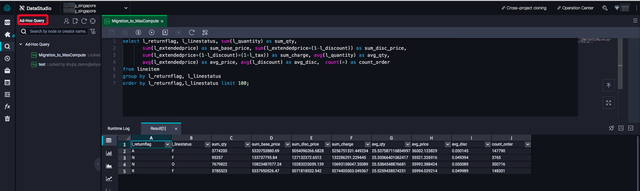
6.2 在MaxCompute中运行相同的查询结果
在Dataworks或者MaxCompte命令行执行与Redshift相同的Query验证数据一致性:
本文为阿里云原创内容,未经允许不得转载。

















