业界首个!大规模多相机通用物品场景数据集MessyTable

作者 | 商汤、南洋理工大学
编辑 | 陈大鑫
众所周知巧妇难为无米之炊,在如今深度学习大行其道的时代,一个数量大、质量好的数据集犹如一块璞玉,就等着算法去雕刻。
今天介绍的就是来自商汤与新加坡南洋理工大学联合制作的大规模多相机通用物品场景数据集MessyTable,MessyTable包括5500+ 手工设计的场景,共计5万多张图片和120万个密集标注的检测框,其对应论文已被ECCV 2020接收。
针对现实生活中多相机系统应用的难点,如相似相同的物品、密集遮挡、大角度差等问题,我们设计了大量真实、有趣又极富挑战的场景:围绕着混乱的餐桌(Messy Table)部署了多个视角的相机,其任务是关联不同相机视角中的实例。看似简单任务却要求算法能够分辨细微的外观差别、从邻近的区域获取线索以及巧妙地使用几何约束等。我们同时提出了利用多相机场景下周围信息的新算法。我们希望MessyTable不仅可以作为极富挑战的基线为后续研究指明方向,也可以作为高度真实的预训练源为算法落地开辟道路。
论文链接:https://arxiv.org/pdf/2007.14878.pdf
代码链接:https://github.com/caizhongang/MessyTable
项目主页:caizhongang.com/projects/MessyTable
MessyTable
图1:MessyTable中的一个场景示例(只可视化了4个视角中的5个物体)
本文我们以7次问答的方式总结了我们的工作:
问题1:MessyTable与现有的ReID和跟踪有什么关系?
问题2:MessyTable有哪些挑战?
问题3:MessyTable的规模有多大?
问题4:MessyTable有哪些设计上的考量?
问题5:各种算法在MessyTable上的表现如何?
问题6:多相机关联还没有解决的问题和下一步的研究方向有什么?
问题7:我可以怎么使用 MessyTable?
1
MessyTable与现有的ReID和跟踪有什么关系?
答:
ReID和跟踪本质上都可以理解为实例的关联,往往需要利用外观信息等。MessyTable虽然主要是为了多相机场景中实例的关联的研究,但是它包含的分辨细微的外观差别、密集遮挡、大角度差等挑战都是和其它实例关联共通的。我们希望MessyTable在服务多相机这个特定场景之外,成为一个实例关联任务通用的数据集,成为新算法的测试场。
2 MessyTable有哪些挑战?
答:
主要的挑战有:
1、相机之间有大角度差,实例的外观在不同视角中差别很大(如图1的Instance ID为5的罐头);
2、部分(图2a)甚至完全(图2b)遮挡,为依靠外观信息的关联算法增加了困难;
3、相似(图2c)或相同(图2d)的物体,因此仅仅使用类似传统ReID的基于外观的算法是不足够的;
4、物体的堆叠(图2e/f)贴近现实生活中的混乱程度,使用传统的单应性矩阵投影等方法无法解决。
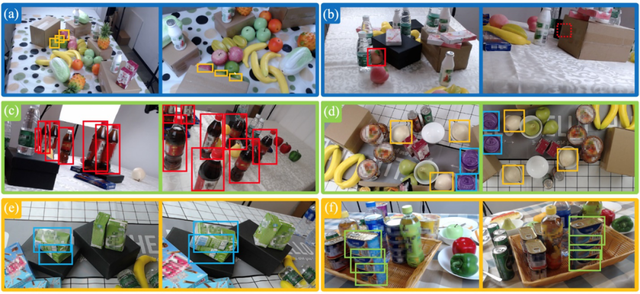
图2:MessyTable中的各种挑战:a)部分遮挡;b)完全遮挡;c)相似物体;d)相同物体;e)和f)复杂的堆叠
3 MessyTable的规模有多大?
答:
我们在表1中与其它类似的多相机数据集的规模的对比。MessyTable包括5500+ 手工设计的场景,共计5万多张图片和120万个密集标注的检测框,每个检测框都有一个Instance ID(同一个物体在不同视角下的Instance ID相同)。

表1:MessyTable与类似多相机数据集的规模对比
4 MessyTable有哪些设计上的考量?
答:
我们主要有三个设计:场景难度等级、多相机的设置以及通用物品的选择。
场景难度等级:我们将MessyTable的场景设计为三个难度等级。越困难的场景中有更多的遮挡、相似相同的物体以及更多物体处于共享视野之外。详见图3。
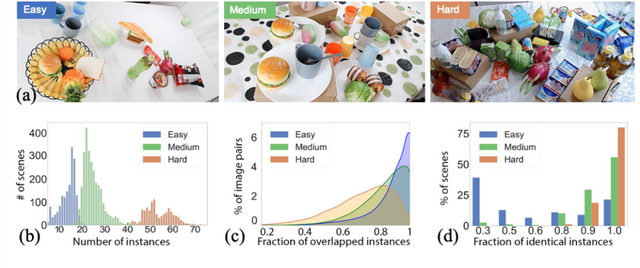
图3:a)三个难度等级的场景示例;b)更难场景有更多的实例;c)更难场景有更少的实例出现在共享视野;d)更难场景有更多相同物体的实例
多相机的设置:为了研究相机相对角度对关联表现的影响,我们设置了9个相机以及567个不同的相机部署方案,产生了2万多对相对相机位置。详见图4。
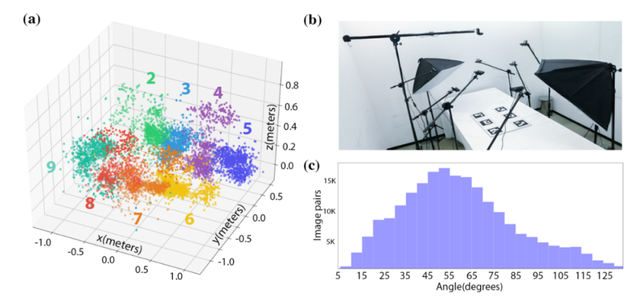
图4:a)相机在空间中的均匀分布(投影至1号相机);b)采集中的相机布置;c)相对相机角度的分布有极大的多样性
通用物品的选择:我们挑选了120种餐桌上常见的物体:60种超市商品、23种果蔬、13种面点以及24种餐具,包括多种大小、颜色、纹理和材料。在图5中我们统计了这些物体的出现频率,在图6中我们罗列了完整的物体清单。
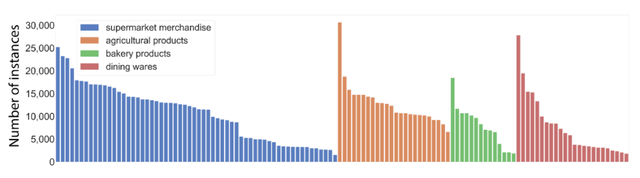
图5:120种物体的出现频率

图6:全物体清单
5 各种算法在MessyTable上的表现如何?
答:
我们测试了多种算法基线(见表2)。单应性投影(Homographic projection)并不意外地表现很差,因为其关键的物体都在同一平面的假设在复杂场景中不成立;基于SIFT关键点提取的传统方法效果也不好,因为无纹理的物体上关键点极少;基于深度学习的Patch-Matching的方法如MatchNet、 Deep-Compare及DeepDesc效果一般,而基于Triplet结构的基线表现有较大幅度的提升,但也受限于无法区分相似相同的物体;
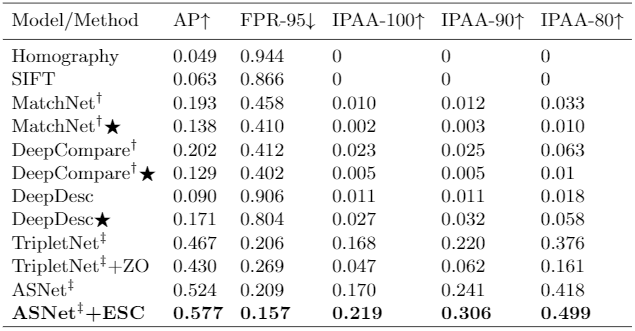
表2:各算法基线在MessyTable上的表现显示结合外观信息、周围信息、几何信息的算法取得最好的效果
我们发现除了外观信息,周围信息非常重要。因此我们提出将检测框之外的信息包括进来。我们将这个操作称之为Zoom-out。但是我们发现直接在Triplet网络上加上Zoom-out效果不好,于是我们观察人类的行为:一个人只有当物体本身的特征信息不足时,才会从周边寻求线索。因此,我们提出ASNet(图7),它有外观特征分支和周围特征分支,并使用一个lambda系数来平衡两个分支(公式1)。当物体的外观信息相似时,Lambda的设计(公式2)使网络分配更大的权重给周围信息分支。
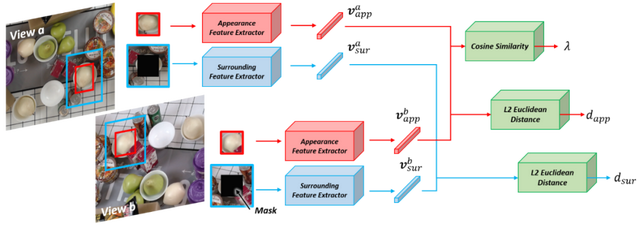
图7:Appearance-Surrounding Network (ASNet)
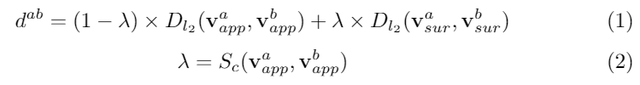
ASNet显著地提升了关联的表现。图8的特征图的可视化显示了ASNet学会了从实例周围获取线索,而直接使用Zoom-out仍然专注于实例本身。
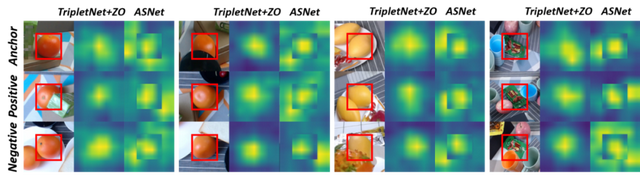
图8:直接使用Zoom-out仍然专注于实例本身(只在中心存在一个高响应区域),但ASNet学会了从实例周围获取线索(在实例周围仍有多个高响应区域)
我们同时还发现在ASNet的基础上增加一个基于对极几何的软约束可以继续提升表现,证明几何信息是和外观信息、周围信息相得益彰的。
6
多相机关联还没有解决的问题和下一步的研究方向有什么?
答:
需要指出的是,尽管同时使用了外观信息、周围信息和特征信息,目前的算法在复杂场景和大相机角度差的情况下表现仍不尽人意。
在图9中,我们比较了四个较强算法在不同相机角度差的情况的表现,发现三个衡量指标都在相机角度差变大的情况下迅速变差。
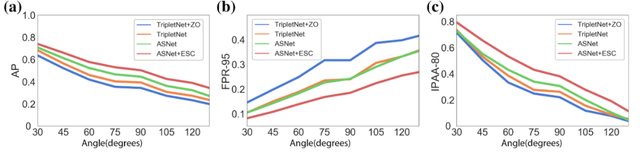
图9:相机角度差越大,关联的表现越差;衡量指标:a)AP;b)FPR-95;c)IPAA-80
在表3中,我们测试了模型在三个难度的子数据集上的表现。越难的子集有的遮挡、相同的物体、更少的出现在共享视野的物体,因此模型的表现也更差。
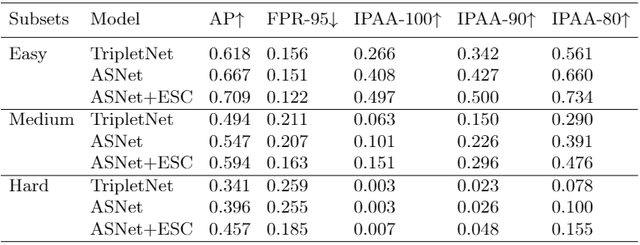
表3:场景越困难,关联的表现较差
更多的失败例子(图10)包括当相同的物体被摆放在一起或者堆叠起来,造成相似的周围信息以及几何软约束的惩罚。

图10:更多的失败例子
以上的这些目前算法的不足给我们提出了三个重要的研究方向:
1) 如何提取更强的外观、周围以及几何信息?
2) 如果更好地融合这些信息?
3) 有没有其它信息我们可以利用?
7 我可以怎么使用 MessyTable?
答:
MessyTable有两个主要的作用:作为一个高指向性的基线和作为一个实例关联的预训练源。对于前者,在MessyTable上表现更好的算法,在其它多相机数据集上也有更好的表现;对于后者,在MessyTable上预训练的模型在其它数据集上的表现比在ImageNet上预训练的表现更好。值得注意的是,我们测试的其它三个数据集甚至包括车辆、行人等与MessyTable中的通用物品差别较大的类别。详见表4。
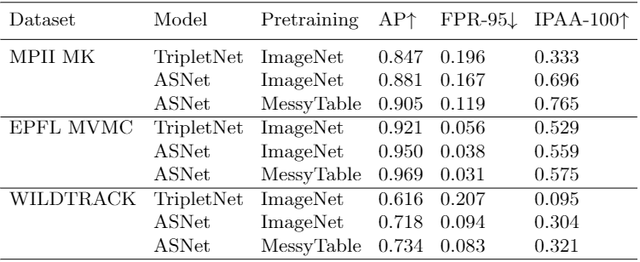
表4:MessyTable可以作为一个高指向性的基线和作为一个实例关联的预训练源
结语:
我们希望MessyTable在实例关联这个领域中促进新颖算法的研究以及发掘新的问题。更多的细节请见我们的项目主页。



















