端侧智能存算一体芯片的需求、现状与挑战


作者 | 郭昕婕、王绍迪
来源 | 《微纳电子与智能制造》期刊
摘 要:现代电子设备朝着智能化、轻量化 、便携化快速发展 ,但是智能大数据处理挑战与冯 · 诺依曼计算架构瓶颈成为 当前电子信息领域的关键矛盾之一;同时,器件尺寸微缩(摩尔定律失效)带来的功耗与可靠性问题进一步加剧了该矛盾 的快速恶化。近年来以数据为中心的新型计算架构 ,例如存算一体芯片技术 ,受到人们的广泛关注 ,尤其在端侧智能场景。但是 ,基于端侧设备在资源 、时延、成本、功耗等诸多因素的考虑 ,业界对存算一体芯片提出了苛刻的要求。因此, 存算一体介质与计算范式尤为重要。同时,器件—芯片—算法—应用跨层协同对存算一体芯片的产业化应用与生态构建非常关键。概述了端侧智能存算一体芯片的需求 、现状 、主流方向 、应用前景与挑战等。
引言
自第四次信息革命以来 ,现代电子设备朝着智 能化 、轻量化 、便携化快速发展。尤其近年来 ,随着 以深度学习神经网络为代表的人工智能算法的深入 研究与普及 ,智能电子设备与相关应用场景已随处 可见 ,例如人脸识别 、语音识别 、智能家居 、安防监 控 、无人驾驶等。同时 ,随着 5G 通信与物联网 (internet of things,IoT)技术的成熟,可以预见,智能 万物互联(artificial intelligent internet of things,AIoT) 时代即将来临。
如图 1 所示 ,在未来 AIoT 场景中 ,设备 将 主 要 分 为 3 类 :云 端 、边 缘 端 与 终 端 [ 1 ] ,其 中 边 缘 终端设备将呈现爆发式增长。众所周知 ,人工智能 的 3 大要素是算力 、数据与算法。互联网与 5G 通信 的应用普及解决了大数据问题 ,深度学习神经网络 的快速发展解决了算法问题 ,英伟达 GPU/谷歌 TPU 等高性能硬件的大规模产业化解决了云端算力问 题。但是 ,资源受限的边缘终端设备的算力问题目 前仍然是缺失的一环 ,且因其对时延 、功耗 、成本 、安 全 性 等 特 殊 要 求( 尤 其 考 虑 细 分 场 景 的 特 殊 需 求 ),将 成为 AIoT 大规模产业化应用的核心关键。因此 ,在 通往 AIoT 的道路上 ,需要解决的核心挑战是高能效、低成本和长待机的端侧智能芯片 。


冯·诺依曼计算架构瓶颈与大数据智能处理挑战
随着大数据、物联网、人工智能等应用的快速兴 起 ,数据以爆发式的速度快速增长。相关研究报告 指出 ,全世界每天产生的数据量约为 2.5 × 1018 字节,且该体量仍然以每 40 个月翻倍的速度在持续增 长[2]。海量数据的高效存储、迁移与处理成为当前电 子信息领域的重大挑战之一。但是 ,受限于经典的 冯 · 诺依曼计算架构[3-4] ,数据存储与处理是分离的 , 存储器与处理器之间通过数据总线进行数据传输, 如图 2(a)所示。在面向大数据分析等应用场景中 , 这种计算架构已成为高性能低功耗计算系统的主要瓶颈之一。一方面 ,数据总线的有限带宽严重制约 了处理器的性能与效率 ,同时 ,存储器与处理器之间 存在严重性能不匹配问题 ,如图 2(b)所示。

不管处理器运行的多快 、性能多好 ,数据依然存储在存储器 里 ,每次执行运算时 ,需要把数据从存储器经过数据 总线搬移到处理器当中 ,数据处理完之后再搬回到 存储器当中。这就好比一个沙漏 ,沙漏两端分别代 表存储器和处理器 ,沙子代表数据 ,连接沙漏两端的 狭窄通道代表数据总线。因此 ,存储器的带宽在很 大程度上限制了处理器的性能发挥 ,这称为存储墙 挑战。
与此同时 ,摩尔定律正逐渐失效 ,依靠器件尺 寸微缩来继续提高芯片性能的技术路径在功耗与可 靠性方面都面临巨大挑战。因此 ,传统冯 · 诺依曼计算架构难以满足智能大数据应用场景快 、准 、智的响 应需求。另一方面 ,数据在存储器与处理器之间的 频繁迁移带来严重的传输功耗问题 ,称为功耗墙挑 战。英伟达的研究报告指出 ,数据迁移所需的功耗 甚至远大于实际数据处理的功耗。例如 ,相关研究 报告指出 ,在 22 nm 工艺节点下 ,1 bit 浮点运算所需 要的数据传输功耗是数据处理功耗的约 200 倍[5] 。在电子信息领域 ,存储墙与功耗墙问题并称为冯 · 诺 依曼计算架构瓶颈。
因此 ,智能大数据处理的挑战 实质是由硬件设施的处理能力与所处理问题的数据 规模之间的矛盾引起的。构建高效的硬件设施与计 算架构 ,尤其是在资源受限的 AIoT 边缘终端设备 , 来应对智能大数据应用背景下的冯 · 诺依曼计算架 构瓶颈具有重要的科学意义与应用前景 。
为了打破冯 · 诺依曼计算架构瓶颈 ,降低数据搬 移带来的开销 ,一种最直接的做法是增加数据总线 带宽或者时钟频率 ,但必将带来更大的功耗与硬件 成本开销,且其扩展性也严重受限。目前业界采用 的主流方案是通过高速接口 、光互联 、3D 堆叠 、增加片上缓存等方式来实现高速高带宽数据通信 ,同时使存储器尽量靠近处理器,减小数据传输的距离。光互联技术还处于研发中试阶段,而3D堆叠技术与增加片上缓存等方法已经广泛用于实际产品当中。
国内外很多高校与企业都在研发与应用这种技术,如谷歌、英特尔、AMD、英伟达、寒武纪科技等。例如,利用3D堆叠技术,在处理器芯片上集成大容量内存 ,可以把数据带宽从几十 GB/s 提升到几百 GB/s;基 于 3D 堆叠 DRAM 技术 ,IBM 于 2015 年发布了一款面 向百亿亿次超级计算系统[6] ;英国 Graphcore 公司在芯 片产品上集成了 200~400MB 的片上缓存 ,来提高性能。
值得注意的是,上述方案不可避免地会带来功耗 与成本开销 ,难以应用于边缘终端能耗与成本均受限 的 AIoT 设备 ,且其并没有改变数据存储与数据处理分离的问题,因此只能在一定程度上缓解,但是并不能从根本上解决冯·诺依曼计算架构瓶颈。

存算一体基本原理与国内外发展现状
存算一体芯片技术,旨在把传统以计算为中心的架构转变为以数据为中心的架构,其直接利用存储器进行数据处理 ,从而把数据存储与计算融合在 同一个芯片当中 ,可以彻底消除冯 · 诺依曼计算架构 瓶颈,特别适用于深度学习神经网络这种大数据量 大规模并行的应用场景。需要说明的是 ,目前在学 术界和产业界有不少类似的英文概念,例如 Computing-in-Memory、In-Memory-Computing、Logic- in- Memory 、In- Memory- Processing 、Processing- in- Memory等,而且不同研究领域(器件、电路、体系架 构、数据库软件等)的称呼也不统一,相应的中文翻 译也不尽相同 ,例如内存处理 、存内处理 、内存计算 、 存算融合 、存内计算 、存算一体等。此外 ,在广义上 , 近存计算也被归纳为存算一体的技术路径之一 。
存算一体的基本概念最早可以追溯到 20 世纪 70 年代,斯坦福研究所的Kautz等[7-8]最早于1969年就 提出了存算一体计算机的概念。后续相当多的研究 工作在芯片电路 、计算架构 、操作系统 、系统应用等 层面展开。例如 ,加州大学伯克利分校的 Patterson 等[9]成功把处理器集成在DRAM内存芯片当中,实现 一种智能存算一体计算架构。但是受限于芯片设计 复杂度与制造成本问题,以及缺少杀手级大数据应 用进行驱动 ,早期的存算一体仅仅停留在研究阶段, 并未得到实际应用。
近年来 ,随着数据量不断增大 以及内存芯片技术的提高,存算一体的概念重新得 到人们的关注 ,并开始应用于商业级 DRAM 主存当 中。尤其在 2015 年左右 ,随着物联网 、人工智能等大 数据应用的兴起 ,存算一体技术得到国内外学术界 与产业界的广泛研究与应用。在 2017 年微处理器顶 级年会(Micro 2017)上 ,包括英伟达 、英特尔 、微软 、 三星、苏黎世联邦理工学院与加州大学圣塔芭芭拉 分校等都推出了存算一体系统原型[10-12]。
尤其是 ,近年来非易失性存储器技术 ,例如闪存 (Flash)、忆阻器(阻变存储器 RRAM)、相变存储器 (PCM)与自旋磁存储器(MRAM)等[13-17] ,为存算一体芯片的高效实施带来了新的曙光。这些非易失性存 储器的电阻式存储原理可以提供固有的计算能力, 因此可以在同一个物理单元地址同时集成数据存储 与数据处理功能。此外 ,非易失性可以让数据直接 存储在片上系统中 ,实现即时开机/关机 ,而不需要 额外的片外存储器。惠普实验室的 Williams 教授团队[18]在 2010 年就提出并验证利用忆阻器实现简单布 尔逻辑功能。
随后 ,一大批相关研究工作不断涌 现。2016年,美国加州大学圣塔芭芭拉分校(UCSB) 的谢源教授团队提出利用 RRAM 构建基于存算一体 架构的深度学习神经网络(PRIME[19] ),受到业界的 广泛关注。测试结果表明,相比基于冯·诺依曼计算 架构的传统方案 ,PRIME 可以实现功耗降低约 20 倍、速度提高约50倍[20]。这种方案可以高效地实现 向量-矩阵乘法运算,在深度学习神经网络加速器领 域具有巨大的应用前景。国际上杜克大学 、普渡大 学 、斯坦福大学 、马萨诸塞大学 、新加坡南洋理工大 学 、惠普 、英特尔 、镁光等都开展了相关研究工作 ,并 发布了相关测试芯片原型[21-24]。
我国在这方面的研 究也取得了一系列创新成果,如北京大学黄如教授 与康晋锋教授团队 、中国科学院微电子研究所刘明 教授团队 、清华大学杨华中教授与吴华强教授团队、 中国科学院上海微系统与信息技术研究所宋志棠教 授团队、华中科技大学缪向水教授团队等,都发布了 相关器件/芯片原型 ,并通过图像/语音识别等应用进 行了测试验证[25-27]。PCM 具有与 RRAM 类似的多比 特特性 ,可以基于类似的原理实现向量-矩阵乘法运 算。对于 MRAM 而言 ,由于其二值存储物理特性 , 难以实现基于交叉点阵列的向量-矩阵乘法运算 ,因 此基于 MRAM 的存算一体通常采用布尔逻辑的计算 范式[28-30]。但由于技术/工艺的成熟度等问题 ,迄今基于相变存储器 、阻变存储器与自旋存储器的存算一体 芯片尚未实现产业化。
与此同时 ,基于 Nor Flash 的存 算一体芯片技术近期受到产业界的格外关注 ,自 2016 年UCSB发布第一个样片以来,多家初创企业在进行 研发,例如美国的Mythic、Syntiant,国内的知存科技 等 ,并受到国内外主流半导体企业与资本的产业投 资 ,包 括 Lam Research 、Applied Materials 、Intel 、 Micron 、ARM 、Bosch 、Amazon 、Microsoft 、Softbank 、 Walden 、中芯国际等。相比较而言 ,Nor Flash 在技术/ 工艺成熟度与成本方面在端侧AIoT领域具有优势,3 大公司均宣布在 2019 年末实现量产。

端侧智能应用特征与存算一体芯片需求
随着 AIoT 的快速发展 ,用户对时延 、带宽 、功耗、隐私/安全性等特殊应用需求,如图3(a)所示,驱 动边缘端侧智能应用场景的爆发。首先 ,时延是用 户体验最直观的感受 ,而且是某些应用场景的必需 要求 ,例如自动驾驶 、实时交互游戏 、增强现实/虚拟 现实技术(AR/VR)等。考虑到实时产生的数据量、 实际传输带宽以及端侧设备的能耗 ,不可能所有运 算都依赖云端来完成。例如 ,根据英特尔的估计 ,每辆自动驾驶汽车每天产生的数据量高达400GB[1];再如 ,每个高清安防监控摄像头每天产生的数据量高 达 40~200GB。如果所有车辆甚至所有摄像头产生 的数据都发送到云端进行处理 ,那不仅仅是用户体 验 ,即使对传输网络与云端设备都将是一个灾难 。而且,通常边缘数据的半衰期都比较低,如此巨大的 数据量 ,实际上真正有意义的数据可能非常少 ,所以 并没有意义把全部数据发送到云端去处理。
此外,同类设备产生的大部分数据通常具有极高的相同模 式化特征 ,借助边缘端/终端有限的处理能力 ,即可 以过滤掉大部分无用数据 ,从而大幅度提高用户体 验与开销。增强用户体验的另一个参数是待机时 间 ,这对便携式可穿戴设备尤为关键。例如智能眼镜与耳机,至少要保证满负荷待机时间在1天以上。因此终端设备的功耗/能效是一个极大的挑战。
其 次 ,用户对隐私/安全性要求越来越高 ,并不愿意把 数据送到云端处理 ,促使本地处理成为终端设备的 必备能力。例如,随着语音识别、人脸识别应用的普 及 ,越来越多的人开始关心隐私泄露的问题 ,即使智 能家居已经普及 ,但很多用户选择关闭语音处理功 能。最后,在无网环境场景下,边缘终端处理将成为 必需。相应地,不同于云端芯片,对于端侧智能芯 片 ,其对成本 、功耗的要求最高,而对通用性、算力 、 速度的要求次之,如图(3 b)所示。
因此,依靠器件尺 寸微缩来继续提高芯片性能的传统技术路径在功耗 与成本方面都面临巨大挑战;而依赖器件与架构创 新的技术路径越来越受重视。2018 年 ,美国 DARPA “电子复兴计划”明确提出不再依赖摩尔定律的等比 例微缩道路 ,旨在寻求超越传统冯 · 诺依曼计算架构 的创新 ,利用新材料 、新器件特性和集成技术 ,减少 数据处理电路中移动数据的需求 ,研究新的计算拓 扑架构用于数据存储与处理 ,带来计算性能的显著 提高。业界普遍认为 ,存算一体芯片技术将为实现此目标提供可行的技术路径 。


存算一体芯片主流研究方向
根据存储器介质的不同 ,目前存算一体芯片的 主流研发集中在传统易失性存储器 ,如 SRAM、DRAM,以及非易失性存储器 ,如 RRAM、PCM、 MRAM 与闪存等 ,其中比较成熟的是以 SRAM 和 MRAM 为代表的通用近存计算架构。值得注意的 是 ,本章将主要讨论基于存算一体芯片的深度学习 神经网络加速器实现。在此类应用中 ,95%以上的运算为向量矩阵乘法( MAC ),因此存算一体主要用来加速这部分运算。
4.1 通用近存计算架构
如图 4 所示 ,这种方案通常采用同构众核的架 构 ,每个存储计算核(MPU)包含计算引擎(processing engine,PE)、缓存(cache)、控制(CTRL) 与输入输出(inout/output,I/O)等,这里缓存可以是SRAM、MRAM 或类似的高速随机存储器。各个 MPU 之间通过片上网络(network-on-chip ,NoC)进行 连接。每个 MPU 访问各自的缓存 ,可以实现高性能 并行运算。典型案例包括英国 Graphcore 公司 ,其测 试芯片集成了 200~400MB 的 SRAM 缓存以及美国 Gyrfalcon Technology 公司 ,其测试芯片集成了 40MB嵌入式MRAM缓存。

4.2 SRAM 存算一体
由于 SRAM 是二值存储器 ,二值 MAC 运算等效于 XNOR 累加运算 ,可以用于二值神经网 络运算。图 5(a)和图 5(b)为两种典型设计方 案 ,其核心思想是把网络权重存储于 SRAM 单元中 ,激励信号从额外字线给入 ,最终利用外围 电路实现 XNOR 累加运算 ,计算结果通过计数 器或模拟电流输出 ,具体实现可以参考[31-32] 。这 种方案的主要难点是实现大阵列运算的同时保 证运算精度。

4.3 DRAM存算一体
基于 DRAM 的存算一体设计主要利用 DRAM 单元之间的电荷共享机制[33-34]。如图 6 所示为一种典型 实现方案[33] ,当多行单元同时被选通时 ,不同单元之 间因为存储数据的不同会产生电荷交换共享 ,从而实现逻辑运算。这种方案的问题之一是计算操作对 数据是破坏性的 ,即每次执行运算时 ,DRAM 存储单元存储的数据会破坏 ,需要每次运算后进行刷新 ,带 来较大的功耗问题;另一个难点是实现大阵列运算的同时保证运算精度 。

4.4 RRAM/PCM/Flash 多值存算一体
基于 RRAM/PCM/Flash 的多值存算一体方案的基本原理是利用存储单元的多值特性 ,通过器件本 征的物理电气行为(例如基尔霍夫定律与欧姆定律)来实现多值 MAC 运算[13,21-25] ,如图 7 所示。每个存储 单元可以看作一个可变电导/电阻 ,用来存储网络权 重,当在每一行施加电流/电压(激励)时,每一列即 可得到 MAC 运算的电压/电流值。实际芯片中 ,根 据不同存储介质的物理原理和操作方法的不同 ,具 体实现方式会有差异 。
由于 RRAM/PCM/Flash 本身是非易失性存储器 , 可以直接存储网络权重 ,因此不需要片外存储器 ,减 小芯片成本;同时,非易失性可以保证数据掉电不丢 失 ,从而实现即时开机/关机操作 ,减小静态功耗 ,延 长待机时间,非常适用于功耗受限的边缘终端设 备。目前 ,基于 RRAM/PCM 的存算一体技术在学术 界是非常热的一个研究方向 ,遗憾的是 ,因为RRAM/PCM 成熟度等问题 ,目前尚未实现产业化 , 但未来具有非常大的潜力;基于 Flash 的存算一体技 术相对较成熟 ,受到产业界广泛关注 ,预计于 2019 年末量产。
4.5 RRAM/PCM/MRAM 二值存算一体
基于 RRAM/PCM/MRAM 的二值存算一体主要有两种方案。第一种方案是利用辅助外围电路,跟上述SRAM 存算一体类似 ,如图 8(a)所示为一种典 型的可重构存算一体实现方案[35] ,其可以在存储应 用与存算一体应用之间进行切换。由于 RRAM/ PCM/MRAM 非易失性电阻式存储原理 ,其具有不同 的电路实现方式 ,具体参考[35-37]。第二种方案是直接 利用存储单元实现布尔逻辑计算[28,38-41] ,如图 8(b)所 示 ,这种方案直接利用存储单元的输入输出操作进 行逻辑运算,根据不同存储器存储单元的结构与操作方法不同 ,可以有不同的实现方式 ,具体可以参 考[28,38-41] 。



应用前景与挑战
存算一体芯片技术,尤其是非易失性存算一体 芯片技术 ,因其高算力 、低功耗 、低成本等优势 ,未来 在 AIoT 领域具有非常大的应用前景。存算一体芯 片 大 规 模 产 业 化 的 挑 战 主 要 来 自 两 方 面 :
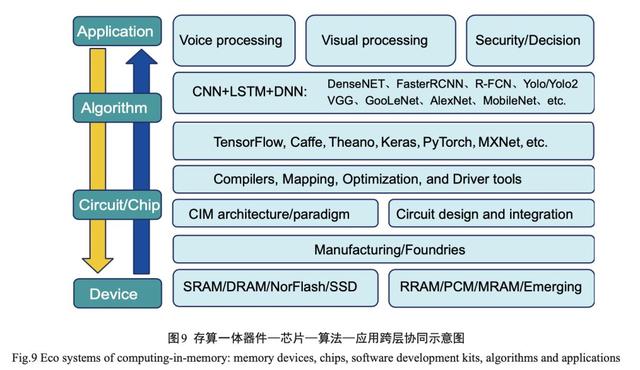
(1 )技 术 层 面:存算一体芯片涉及器件—芯片—算法—应用等多 层次的跨层协同 ,如图 9 所示。例如 ,细分应用场景的不同性能需求决定了神经网络算法与芯片的设 计 ,算法依赖神经网络框架 、编译 、驱动 、映射等工具 与芯片架构的协同,芯片架构又依赖器件、电路与代 工厂工艺。这些对存算一体芯片的研发与制备都是 相当大的一个挑战 ,尤其需要代工厂的支持。特别 是基于新型存储介质的存算一体技术 ,器件物理原 理 、行为特性 、集成工艺都不尽相同 ,需要跨层协同 来 实 现 性 能( 精 度 、功 耗 、时 延 等 )与 成 本 的 最 优 。
(2 ) 产业生态层面:作为一种新兴技术,想要得到大规模 普及 ,离不开产业生态的建设 ,需要得到芯片厂商 、 软件工具厂商 、应用集成厂商等的大力协同 、研发 、 推广与应用 ,实现性能与场景结合与落地 ,尤其在面 对传统芯片已经占据目前大部分已有应用场景的前 提下 ,如何突破新市场 、吸引新用户是快速产业化落地的关键。英伟达GPU的成功给出了很好的启示与 借鉴。一方面需要优化工具与服务 ,方便用户使用; 另一方面需要尽量避免竞争 ,基于存算一体芯片的 优势 ,开拓新应用 、新场景 、新市场 ,创造传统芯片无 法覆盖的新型应用市场。
郭昕婕, 王绍迪. 端侧智能存算一体芯片概述[J]. 微纳电子与智能制造, 2019, 1(2): 72-82.
GUO Xinjie, WANG Shaodi. Continuous perception integrated circuits and systems for edge-computing smart devices[J]. Micro/nano Electronics and Intelligent Manufacturing, 2019, 1 (2): 72-82.
《微纳电子与智能制造》刊号:CN10-1594/TN
主管单位:北京电子控股有限责任公司
主办单位:北京市电子科技科技情报研究所
北京方略信息科技有限公司
【end】
《原力计划【第二季】- 学习力挑战》正式开始!
即日起至 3月21日,千万流量支持原创作者更有专属【勋章】等你来挑战

机器学习新闻综述:2019年AI领域不得不看的6篇文章
超30亿人脸数据被泄露,美国AI公司遭科技巨头联合“封杀”
4600万英镑的“比特币鱼竿”!爱尔兰毒贩遗失藏有巨额比特币密钥的渔具
Rust 编译模型之殇
狂赚 1200 亿,差点收购苹果,影响千万程序员,那个叫做太阳的公司却陨落了!
两成开发者月薪超 1.7 万、算法工程师最紧缺! | 中国开发者年度报告



















