可能是目前最全面的知识库复杂问答综述解读
本文沿用短文的叙述角度,将复杂知识图谱问答方法总结为基于语义解析 (Semantic Parsing-based; SP-based) 的方法和基于信息检索 (Information Retrival-based; IR-based) 的方法。从挑战和解决策略的角度讨论现有的复杂知识图谱问答工作。和原短文相比,该长文将内容从扩展到20页。该长文归纳了更多的论文,主要板块加入了更深入讨论和更多实例细节以及图示表达,另增加了背景知识介绍和技术总结板块。本文是原作者团队基于已发表在IJCAI’2021的短文综述的扩展。
原短文综述可参考地址:
https://www.ijcai.org/proceedings/2021/0611.pdf
扩展版长文地址:
https://arxiv.org/pdf/2108.06688.pdf
作者单位:
华东师范大学,人民大学,新加坡管理大学,北京大数据管理分析中心重点实验室
![]() 一、论文引入
一、论文引入
相比仅包含单个关系事实的简单问题,复杂问题通常有以下几个特征。我们以文中的例子 “谁是杰夫·普罗斯特秀提名的电视制片人的第一任妻子?” 为例:
· 需要在知识图谱中做多跳推理 (multi-hop reasoning):该问题主干需要两跳的推理,即“杰夫·普罗斯特秀提名的人”和“他的妻子”。
· 需要考虑题目中给的限制词 (constrained relations):该问题中出现的限制词“电视制片人”需要在回答问题的时候被考虑到。
· 需要考虑数字运算的情况 (numerical operations):该问题询问涉及序数“第一任”,因此需要对召回的实体进行排序操作。
直接将传统知识图谱问答模型运用到复杂问题上,不管是基于语义解析的方法还是信息检索的方法都将遇到新的挑战:
· 传统方法无法支撑问题的复杂逻辑:基于语义解析的方法需要定义极具表达能力的解析式语法,基于信息检索的方法需要发展出追踪推理的能力。
· 复杂问题包含了更多的实体,导致在知识图谱中搜索空间变大:这使得基于语义解析和信息检索方法的开销过大,难以用于解决实际问题。
· 两种方法都将问题理解作为首要步骤:当问题的语义和句法变得复杂时,模型应具有更强的自然语言理解和泛化能力。
· 通常 Complex KBQA 数据集缺少对正确路径的标注:在没有正确解析式和推理路径的监督下,训练这两种方法将变得非常困难。
二、背景知识介绍
传统的知识图谱问答系统通常有图1的结构。第一步是实体连接 (entity linking),即识别问题 中的主题并且映射到知识图谱 中的主题实体 。接下来的步骤是预测答案 。预测答案传统的方法主要分为两类。
· 基于语义解析 (SP-based) 的方法会将 解析并生成一个中间解析式 ,执行该解析式以获得问题的答案。
· 基于信息检索 (IR-based) 的方法将会从整个知识图谱中抽取一个子图 ,随后基于子图进行问题的推理,并选取子图中排序较高的实体作为答案。
预测答案将被作为系统输出返回给用户。
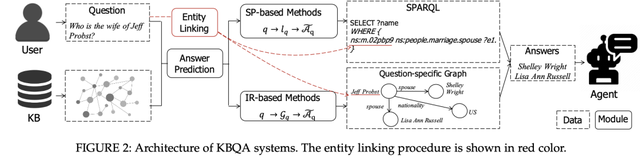
图1. 知识图谱问答系统架构示意图
通常评估知识图谱系统的方法是考核预测的准确度,如:,, 等。但更多方面的考核,如:鲁棒性,系统用户交互的能力等,也是需要被注意到的。我们针对这三个方面的评估方法进行了较为详细的总结。
三、两类主流方法
为了方便读者对两类方法的理解,我们公式化地总结了两类主流方法的各个模块。
基于语义解析(SP-based)的方法
(1)问题理解 (question understanding) 模块将自然语言的问题编译成分布式表达,结构化表达或者他们的结合。
通常情况下,神经网络(如:LSTM, GRU等)可被直接用于问题解析。与此同时,语义解析工具可被用来获取问题的结构特征。
(2)解析 (logical parsing) 模块将编译好的问题转化成解析式。
这一步的实现可以是运用Seq2seq的模型生成一系列字符 (token) 组合成解析式。也可以是基于规则生成一系列候选解析式再将他们排序。
(3)知识图谱实例化 (KB grounding) 模块将生成的解析式实例化得到可执行语句。
通常情况下,包含了主题实体 。在有些工作中,(2)和(3)可以同步进行。
(4)知识执行 (KB execution) 模块执行得到的可执行语句,召回答案。
基于语义解析 (SP-based) 的方法的训练目标是产生符合问题语义的解析式并且能够执行得到正确答案。
基于信息检索(IR-based)的方法
(1)子图构建 (retrieval source construction) 模块将从主题实体 出发,在知识图谱全图中抽取与问题相关的子图。
抽取的子图大小会随着抽取信息距离主题实体的距离增大呈指数增加。已有方法如 GraftNet 等通过 Personalized pagerank 保留重要实体控制子图大小。
(2)问题表达 (question representation) 模块将自然语言的问题 编译成分布式表达 ,再结合其他方法生成指令。
这里,是第 步推理得到的向量,该向量蕴含了问题在该步的指令。(3)基于图结构的推理 (graph based reasoning) 模块将在指令的指导下在抽取的子图中做传送和增强。推理过程将会产生推理状态向量 。该向量在具体方法中定义有所不同,如:预测实体的分布,关系的表达等。
一些最新的工作重复(2)和(3)来实现显性的多步推理。
(4)答案排序 (answer ranking) 模块将第 步推理状态向量用于最终的答案预测,排序高的实体被作为预测实体。
已有的工作通常会通过超参数阈值来选取预测答案实体。基于信息检索的方法训练目标是让正确的答案实体排序高于其他实体。
四、挑战和解决策略
当处理复杂问题时,基于语义解析 (SP-based) 和信息检索 (IR-based) 的方法不同模块会遇到相应的挑战。相关的工作也针对这些挑战提出了解决策略。对于这个问题,我们努力尝试在论文中给了一个尽可能清晰的梳理,大家可以参考论文中的表格(表1)去理解。
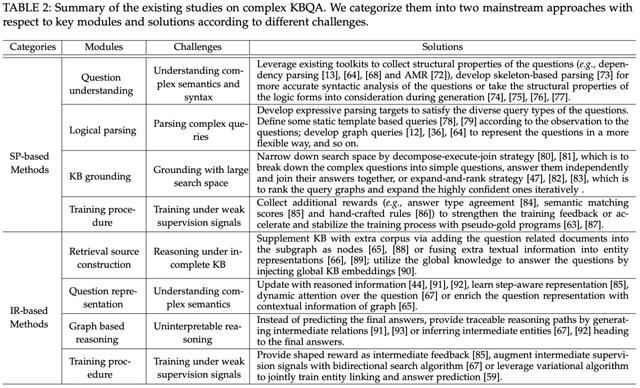
表1. 已有工作的挑战和解决策略总结
五、技术总结
除了讨论挑战和解决策略之外,我们列举了 Complex KBQA 方法用到的具体特征和技术。
基于语义解析 (SP-based) 的方法:
· 问题理解模块利用神经网络,结构化技术产生输入特征 (Input Features)
· 逻辑解析模块主要包含序列到序列生成,基于排序解析两类解析方法 (Parsing Methods)
· 不同解析方法采用不同训练目标 (Training Algorithms)
· 总结了上述步骤中的重要技术 (Featured Techniques)
详细信息可参考下表:
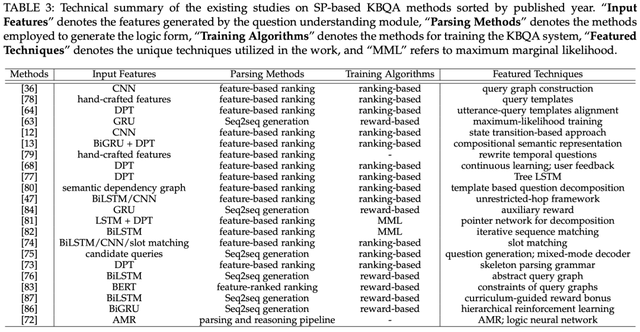
表2. 基于语义解析方法的技术总结
基于信息检索 (IR-based) 的方法:
· 问题理解模块采用多种技术将问题语义转化成一系列指令 (Instruction Generation)
· 指令向量根据不同推理方法进行状态更新 (Reasoning Methods)
· 训练采用不同的目标函数 (Training Algorithms)
· 总结了上述步骤中的重要技术 (Featured Techniques)
详细信息可参考下表:

表3. 基于信息检索方法的技术总结
六、研究展望
不断进化的知识图谱问答系统
目前的知识图谱问答系统通常是在线下进行训练然后部署到线上。然而,大部分已有的知识图谱问答系统都会忽略线上部署后对新实例的学习。与此同时,外部知识在不断进化,一个知识图谱问答系统应该能够在线上部署之后不断进化的。目前有少量的工作关注到这一块。比如引入连续学习 (continuous learning) 的框架。当知识图谱问答系统遇到没见过的问题时,他们可以先将其和系统中已有的训练问题进行比对,召回最相似问题的解析式,让用户从中选出有效的解析式加入到训练数据中。再如让用户直接参与到系统中,当用户提出没见过的问题或者包含歧义的问题时,系统给出一些候选的消歧后的问题供用户选择。
鲁棒的知识图谱问答系统
已有的知识图谱问答研究大部分是在一种理想情况下展开的,然而真实场景下,数据可能会严重缺失或者不足。现有少量工作聚焦数据不足时,用元学习 (meta learning) 训练知识图谱问答系统,以及用无监督的双语词典归纳 (bilingual lexicon induction) 技术对低资源 (low-resource) 数据进行增强。与此同时,有一部分工作对分布外异常 (out-of-distribution) 的问题开展了研究。他们提出了 CFQ 和 GrailQA 数据集促进这方面的未来研究。
更加一般定义的知识图谱
有一些任务,如:视觉问答 (VQA), 常识知识推理 (Commonsense Knowledge Reasoning) 可以被看作是在一种特殊的知识图谱上做推理。比如有部分工作将阅读理解的任务中的文本看做虚拟的知识图谱,然后在上面做推理。除了显性地在任务中构建知识图谱,有部分工作将其他任务看作隐性的知识图谱。近年来较为突出的是,部分研究者将预训练语言模型作为特殊的知识库,认为其具有储存知识和推理的能力。
对话型知识图谱问答
对话型的知识图谱问答是新兴的任务。在单轮的问答之后,用户会围绕该主题提出一系列问题。目前对于对话型知识图谱问答的研究主要是针对如何判断后续问题的主题展开的。用户提出的问题间将具有某一些联系,而不是独立存在。对历史问题进行记忆和理解有助于回答当前问题。同时,为了减少对话问答带来的搜索空间增大的困难,也有部分工作在这个方向进行了简单的探索。
写在最后。与Complex KBQA很多相关的方向和任务都非常值得探索。希望我们的综述能为大家提供一个全面的梳理,抛砖引玉,方便大家做出更多的贡献。
Illustrastionby Elizaveta Guba from Icons8
-The End-
“AI技术流”原创投稿计划
TechBeat是由将门创投建立的AI学习社区(www.techbeat.net)。社区上线330+期talk视频,900+篇技术干货文章,方向覆盖CV/NLP/ML/Robotis等;每月定期举办顶会及其他线上交流活动,不定期举办技术人线下聚会交流活动。我们正在努力成为AI人才喜爱的高质量、知识型交流平台,希望为AI人才打造更专业的服务和体验,加速并陪伴其成长。
投稿内容
// 最新技术解读/系统性知识分享 //
// 前沿资讯解说/心得经历讲述 //
投稿须知
稿件需要为原创文章,并标明作者信息。
我们会选择部分在深度技术解析及科研心得方向,
对用户启发更大的文章,做原创性内容奖励。
投稿方式
发送邮件到
或添加工作人员微信(chemn493)投稿,沟通投稿详情;还可以关注“将门创投”公众号,后台回复“投稿”二字,获得投稿说明。
>> 投稿请添加工作人员微信!
本周上新!

扫码观看!
关于我“门”
▼
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门技术社群以及。
将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”: 
点击“阅读原文”按钮,查看社区原文⤵一键送你进入TechBeat快乐星球




















评论