90秒训练AlexNet!商汤刷新纪录
随着技术和硬件的发展,在 ImageNet 上训练 AlexNet、ResNet-50 的速度被不断刷新。2018 年 7 月,腾讯机智机器学习平台团队在 ImageNet 数据集上仅用 4 分钟训练好 AlexNet、6.6 分钟训练好 ResNet-50;11 月,索尼刷新在 ImageNet 数据集上训练 ResNet-50 的时间:224 秒;之后不久,谷歌再次刷新 ImageNet/ResNet-50 训练时间的记录:2.2 分钟。昨日,商汤和新加坡南洋理工大学的研究者发布最新研究,他们在 ImageNet 数据集上使用 512 个 GPU 仅用一分半钟完成了 AlexNet 的训练(此前,腾讯机智团队用了 1024 个 GPU、4 分钟时间);在 512 个 GPU 上用 7.3 分钟完成了 ResNet-50 的训练。
扩展深度神经网络(DNN)训练对于减少模型训练时间非常重要。高通信消耗是在多个 GPU 上进行分布式 DNN 训练的主要性能瓶颈。商汤的这项研究表明流行的开源 DNN 系统在以 56 Gbps 网络连接的 64 个 GPU 上仅能实现 2.5 倍的加速比。为解决该问题,这项研究提出了通信后端 GradientFlow 用于分布式 DNN 训练,并使用了一系列网络优化技术。
- 将 ring-based allreduce、混合精度训练和计算/通信重叠(computation/communication overlap)集成到 GradientFlow 中。
- 提出 lazy allreduce,将多个通信操作融合为一个操作来提高网络吞吐量。
- 设计了粗粒度稀疏通信(coarse-grained sparse communication,CSC),仅传输重要的梯度 chunk 以降低网络流量。
研究者使用该方法在 512 个 GPU 上训练 ImageNet/AlexNet,获得了 410.2 的加速比,在 1.5 分钟内完成了 95-epoch 的训练,超过已有方法。
分布式 DNN 训练
关于 DNN
深度神经网络(DNN)从训练数据中学习模型,然后利用学得模型在新数据上执行预测。通常,DNN 包含多个层,从 5 个到 1000 多都有。下图展示了一个有 7 个层的 DNN。图中数据层负责读取和预处理输入数据,第一层与后续一系列中间层相连,包括两个卷积层、两个池化层、一个内积(innerproduct)层、一个损失层,这些层都使用特定函数和大量参数,以将输入转换为输出。最终,该 DNN 将原始输入数据转换为期望输出或者说预测结果。

图 2:有 7 个层的深度神经网络示例。
为了给出准确的预测结果,大部分 DNN 都需要接受训练。研究者最常使用 iterative-convergent 算法和反向传播来训练 DNN。
数据并行分布式 DNN 训练
在单个节点上用大型训练数据进行模型训练需要耗费大量时间。因此出现了很多分布式 DNN 系统(如 TensorFlow 和 PyTorch)可以通过数据并行策略在集群上进行并行化 DNN 训练,即一个模型在所有 GPU 上同时运行,但它们处理的是不同部分的训练数据。
如下图所示,实现数据并行 DNN 训练有两个设计选择:使用 master-slave 架构的参数服务器(PS)方法、使用 P2P 架构的 allreduce 方法。在 PS 方法中,设置一或多个服务器节点来主要管理模型参数。在每次迭代中,每个 worker 将其计算出的梯度传向服务器节点以聚合梯度、更新模型,然后再从服务器节点处获取最新的参数信息。而在 allreduce 方法中,所有 worker 直接互相通信,通过 allreduce 操作交换局部梯度。在 allreduce 操作之后,每个 GPU 聚合梯度,并使用它们对复制参数进行局部更新。
本研究使用基于 allreduce 的 DNN 训练方法。

图 3:分布式 DNN 的系统架构。
基准系统设计&集群设置
下图展示了基于 allreduce 的分布式 DNN 训练的基准系统设计。
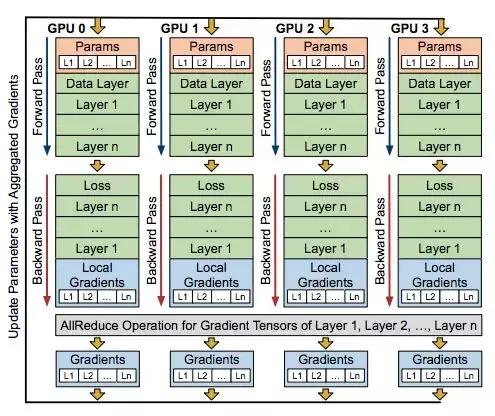
图 4:分布式 DNN 训练的基准系统。
为评估系统性能,研究者在 ImageNet-1K 数据集上对两个经典 DNN(AlexNet 和 ResNet-50)的训练时间进行评估。该数据集包含超过 120 万张标注图像和 1000 个类别。

图 5:AlexNet 和 ResNet-50 架构信息。AlexNet 有 27 个层,26 个张量管理 60.9M 个可学习参数。ResNet-50 有 188 个层,152 个张量管理 25.5M 可学习参数。
集群硬件 & 软件设置
该研究使用两个集群进行性能评估:Cluster-P 和 Cluster-V。
- Cluster-P 包含 16 台物理机器和 128 个英伟达 Pascal GPU。
- Cluster-V 包含 64 台物理机器和 512 个英伟达 Volta GPU。与 Pascal GPU 相比,Volta GPU 可使用 Tensor Core 通过混合精度矩阵乘法加速矩阵运算,并在单个任务中进行累加。
在两种集群中,每台物理机器都配备 8 个 GPU,同一台机器中的所有 GPU 通过 PCIe 连接,集群中的所有机器通过 56Gbps InfiniBand 连接,这些机器共享分布式文件系统,用于训练数据集管理。
Ring-Based AllReduce
高效的 allreduce 算法和实现对于分布式 DNN 来说非常重要。ring-based allreduce [24] 是一种以固定通信成本执行 allreduce 的算法,通信成本按每个 GPU 迁出/入的数据量来衡量。

图 7:ring-based allreduce 和层级 allreduce。该示例中有 4 台机器,每台机器有 4 个 GPU。在(a)中,全部 16 个 GPU 按逻辑环路(logical ring)排列。在(b)中,16 个 GPU 被分为 4 组,每一组的 master GPU 构成 allreduce 的逻辑环路。
混合精度训练
该研究将混合精度训练扩展到分布式设置中。下图展示了混合精度训练的分布式设计。

图 10:混合精度训练使用半精度梯度张量作为 allreduce 操作的输入。

图 11:以 NCCL 为通信后端,使用单精度训练和混合精度在 Cluster-P 和 Cluster-V 上进行 System-I 性能评估。在 Cluster-P 上,每个 GPU 的批量大小是 128,AlexNet 和 ResNet-50 各 64。在 Cluster-V 上,每个 GPU 的批量大小是 128,AlexNet 和 ResNet-50 均 128。
计算/通信重叠

图 12:基于层的计算/通信重叠。该方法中,上层的通信操作可与下层的计算操作重叠,从而降低迭代的专用通信时间。

图 13:AlexNet 和 ResNet-50 在单个 Volta GPU 上的单 GPU 单层 backward 计算时间。
GradientFlow 系统设计
本研究提出 GradientFlow 来解决分布式 DNN 训练的高通信成本问题。GradientFlow 是 System-I 的通信后端,支持大量网络优化技术,包括 ring-based allreduce、混合精度训练、计算/通信重叠。为了进一步降低网络成本,GradientFlow 使用 lazy allreduce,将多个 allreduce 操作融合为一个操作来提高网络吞吐量。它还使用粗粒度的稀疏通信,仅传输重要的梯度 chunk 以降低网络流量。下面将介绍 lazy allreduce 和粗粒度稀疏通信,并衡量其有效性。
Lazy AllReduce

图 15:lazy allreduce 不会在生成单个梯度张量时直接对其执行 allreduce。它试图将多个 allreduce 操作融合为一,以提高网络吞吐量。上例中,lazy allreduce 的上层通信与下层的 backward 计算重叠。
粗细度稀疏通信
下图展示了粗粒度稀疏通信的设计。
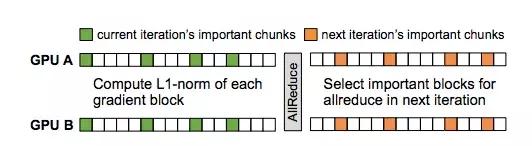
粗粒度稀疏通信(CSC)使用 momentum SGD correction 和 warm-up dense training,避免损失模型准确率。
Momentum SGD Correction 算法如下所示:

研究者在 System-I 中实现了 CSC,并评估了其在 Alexnet 和 ResNet-50 训练中的性能。下图展示了平均吞吐量。
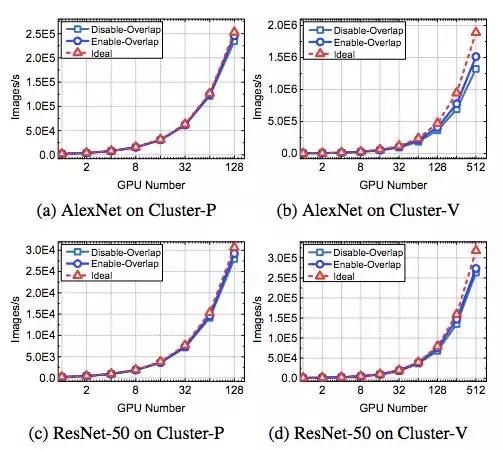
图 19:使用 NCCL、混合精度训练和粗粒度稀疏通信时的 System-I 性能评估。单 GPU 批量大小为 128。在 disable-overlap 方法中,System-I 对所有选中梯度 chunk 执行一个 allreduce 操作。在 enable-overlap 方法中,System-I 执行多个 allreduce 操作,通信和计算出现部分重叠。
整体性能评估
网络优化技术的有效性
表 1 和表 2 展示了单个集成网络优化技术及其结合体的有效性。

表 1:使用 System-I 在 Cluster-P (128 Pascal GPUs) 和 Cluster-V (512 Volta GPUs) 上对比不同网络优化技术的 AlexNet 训练吞吐量 (image/s) 和加速比。MP:混合精度训练;LA:Lazy AllReduce;CSC:粗粒度稀疏通信;Overlap:计算/通信重叠。

表 2:使用 System-I 在 Cluster-P (128 Pascal GPUs) 和 Cluster-V (512 Volta GPUs) 上对比不同网络优化技术的 ResNet-50 训练吞吐量 (image/s) 和加速比。
端到端训练时间

表 3:不同方法的 AlexNet 训练对比。

表 4:不同方法的 ResNet-50 训练对比。




















