CVPR 2019 | 腾讯AI Lab解读六大前沿方向及33篇入选论文
本文转载至公众号:腾讯技术工程
已获得授权

计算机视觉顶级会议 CVPR 2019 将于 6 月 15 日– 6 月 21 日在加利福尼亚州长滩举办,今年腾讯公司共有 58 篇论文入选,其中腾讯 AI Lab 33 篇(含 8 篇oral),腾讯优图实验室 25 篇。腾讯 AI Lab 入选论文涉及视频理解、人脸识别、对抗攻击、视觉-语言描述、模型压缩和多任务学习等几大重点研究方向,下面将分组介绍论文。往年参会入选论文可见公众号历史文章。
注:本文分组方式并不严格,部分论文同时分属多个主题。
对抗攻击
Against Attack
深度神经网络在很多应用领域都取得了惊人的效果,比如图像分类和人脸识别。但与此同时,深度神经网络也是十分脆弱的。最典型的例子就是对抗攻击,具体而言,在输入样本(比如图像)上加入人类难以察觉的微小噪声,可以让深度神经网络的预测出现严重偏差。对抗攻击的研究,对于加强深度神经网络的安全性以及可解释性,具有很重要的意义。以往大多数研究工作集中在白盒对抗攻击和非结构化输出模型的攻击,而我们CVPR 2019的入选论文重点研究了更具挑战的黑盒对抗攻击,和对结构化输出模型的攻击。
1.针对人脸识别的基于决策的高效黑盒对抗攻击方法
Efficient Decision-based Black-box Adversarial Attacks on Face Recognition
本文由腾讯AI Lab主导,与清华大学合作完成,是在黑盒对抗攻击领域的一项重要探索。近年来,基于深度卷积神经网络的人脸识别取得了显著的成就。但是,深度卷积神经网络很容易受到对抗样本的攻击。因此,人脸识别系统的安全性也可能受到很大的威胁。
为了验证当前最先进人脸识别模型的安全性能,我们研究了基于决策的黑盒攻击,即无法获知人脸识别模型的参数或结构,只能通过询问来获取模型的结果。这种设定完全符合现实情况下的攻击情形。我们提出了一种基于进化算法的高效攻击方法,其充分利用了搜索空间的局部几何特性,并通过对搜索空间进行降维来提高攻击效率。实验表明我们的攻击方法比已有的黑盒攻击方法更高效。同时,我们还对第三方人脸识别系统进行了攻击验证,也充分展示了我们方法的优越性能。

2.基于带有隐变量的结构化输出学习的图像描述精准对抗攻击
Exact Adversarial Attack to Image Captioning via Structured Output Learning with Latent Variables
本文由腾讯AI Lab 主导,与电子科技大学合作完成,探索了对图像描述模型实现精准对抗攻击的方法。对抗攻击对深度学习模型存在严重威胁,揭示了深度神经网络的脆弱性。研究对抗攻击有助于理解深度学习模型的内部机制,也能帮助提升模型的安全性,具有非常高的研究和实用价值。已有对抗攻击方法主要以带有独立输出的模型为攻击对象,但很多问题的输出结果往往是结构化的,比如在基于 CNN+RNN 的图像描述问题中,输出是一个序列。
我们以基于 CNN+RNN 的图像描述模型为具体对象,在业内第一次定义了“精准结构化攻击”,即通过优化对抗样本,迫使模型在特定位置输出特定的词。由于输出序列内部的关联性,现有的针对独立输出的攻击方法无法在序列输出问题中实现精准攻击。
我们的具体做法是将精准结构化攻击问题建模成带有隐变量的结构化输出学习模型;此外我们还展示了两种优化算法。我们对当前最流行的图像描述模型进行了精准攻击实验,结果展现了非常高的攻击成功率和非常低的对抗噪声。
另外,我们还将精准结构化攻击算法作为探测结构化输出空间的工具,揭示出当前图像描述模型还没有很好地掌握人类的语法规则,比如被动语态和定语从句。这为进一步缩小图像描述模型与人类描述的差距指明了方向。同时,本文所提出的模型和算法与具体图像描述模型无关,可轻松地用于攻击其它结构化模型。

视频深度理解
Deep Understanding of Videos
机器要理解世界,就必需要处理和分析周围动态环境能力。视频的分析与处理在移动机器人、自动驾驶、监控视频分析等许多应用中都是至关重要的技术,甚至关乎使用者的生命安全。同时,近些年基于卷积神经网络(CNN)的方法已经在静态图像分析方面取得了重大的进展和突破,所以计算机视觉领域的研究重心也正向动态的视频领域倾斜。
与静态的图像处理相比,视频分析面临着一些特有的难题,比如识别、跟踪与重新判定视频中目标的身份,预测目标的运动轨迹,多目标跟踪,分析视频内容并提取相关片段等。
腾讯 AI Lab 入选的 33 篇论文中有 9 篇与视频直接相关,涉及到光流学习、视频对象分割、目标跟踪和视频定位等多个研究方向
1.一种自监督的光流学习方法
SelfFLow: Self-Supervised Learning of Optical Flow
本文由腾讯AI Lab 主导,与香港中文大学合作完成,是CVPR oral 展示论文之一。光流是计算机视觉的一个基本任务,它描述了运动的信息,也有很多应用场景,比如物体跟踪、视频分析、三维重建、自动驾驶等。我们探索了使用卷积神经网络估计光流的一个关键挑战:预测被遮挡像素的光流。
首先,我们提出了一种从没有标注的数据中学习光流的自监督框架。这个方法会人为创造一些遮挡,然后利用已经学习到的比较准确的没有被遮挡像素的光流去指导神经网络学习被遮挡像素的光流。
其次,为了更好地学习光流,我们设计了一个可以利用多帧图像时序连续性的网络结构。基于这两个原则,我们的方法在MPI Sintel、KITTI 2012和KITTI 2015等数据集上取得了最好的无监督效果。更重要的是,我们的无监督方法得到的模型能为有监督的微调提供一个很好的初始化。经过有监督微调,我们的模型在以上三个数据集上取得了目前最优的性能。在写这篇文章的时候,我们的模型在Sintel数据集上取得EPE=4.26 的成绩,超过所有已经提交的方法。
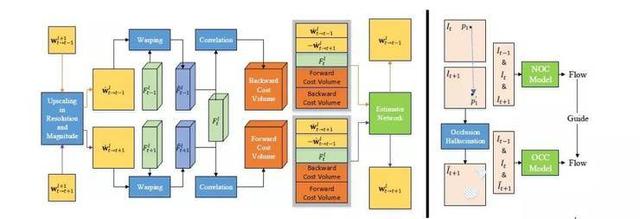
框架概况:左侧是每一层级的网络架构,右侧是我们的自监督训练策略
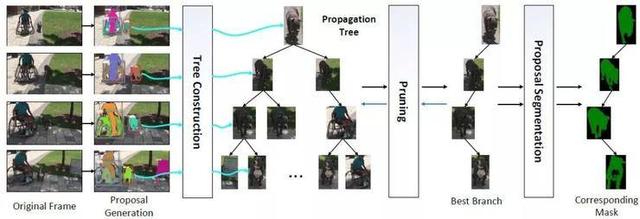
2.MHP-VOS: 基于多假设传播的视频对象分割
MHP-VOS: Multiple Hypotheses Propagation for Video Object Segmentation
本文由腾讯AI Lab与华中科技大学合作完成,是CVPR oral 展示论文之一。本文首先阐述了半监督视频对象分割(VOS)问题,其中感兴趣的对象的掩码在输入视频的第一帧中给出。要处理对象被遮挡或丢失的高难度案例,以前的工作依赖于贪婪的数据关联策略为每帧单独制定决策。在本文中,我们提出了一种对于每个帧中的目标对象推迟决策的新方法,直到全局地考虑了整个视频后才进行决策。
我们的方法与多假设跟踪(MHT)方法一脉相承,但也进行了几项关键的修改以适用于VOS问题。我们使用的是掩模假设而不是方框假设,这能让我们设计出更专门定制的VOS算法。具体来说,从第一帧中的初始对象掩码开始,通过将前一帧的掩模传播到后一帧门控区域里检测到的方框建议来生成多个假设。该门控区域是通过一种门控方案来确定的,该方案考虑了更全面的运动模型,而不是传统MHT中的简单卡尔曼滤波模型。我们设计了一个全新的掩模传播分数,而不是MTH中的外观相似度分数,因为外观相似度分数在物体变形较大时不够鲁棒。该掩模传播分数与运动分数一起,共同确定了多个假设之间的亲近关系,这个亲近关系可以用于后续的假设树的剪枝算法。
此外,我们还提出了一种新颖的掩模合并策略,用以处理多个被跟踪物体之间的掩模冲突。实验表明,该方法能有效处理具有挑战性的数据集,特别是在对象丢失的情况下。
3.PA3D:基于3D 姿态-动作的视频识别
PA3D: Pose-Action 3D Machine for Video Recognition
本文由腾讯AI Lab与中国科学院深圳先进技术研究院合作完成。目前大多数动作识别方法都采用3D CNN提取特征,但这些方法都是基于RGB和光流,并未完全利用动作的动态变化规律。本文提出的精确Pose-Action 3D Machine方法能够在统一的 3D 框架下有效地编码多种姿态以及学习时空域姿态表征,进而实现更好的动作识别。我们在三个公开数据集上进行了测试,结果表明本文提出的方法优于已有的基于姿态的动作识别方法。
4.具有目标感知能力的追踪框架
Target-Aware Deep Tracking
本文由哈尔滨工业大学、腾讯AI Lab、上海交通大学与加州大学默塞德分校合作完成,提出了一种具有目标感知能力的追踪框架。当前基于深度学习的追踪方法常使用的深度特征提取都是在分类任务上预训练好的。尽管这样的做法在多个视频领域取得了很大的成功,但是在追踪领域中,其有效性还未得到深入挖掘。
关键原因是在追踪任务中,目标物体类别和形式是未知的和不确定的,只有在追踪开始时才确定。直接使用在类别固定的分类任务上训练的深度特征,难以对追踪中的目标进行有效地建模。为此,我们提出了一个基于梯度值的机制去学习能够感知目标的特征。鉴于此,我们构建了一个回归损失和一个排序损失来分别指导模型,生成能够有效表征目标的特征和对于目标大小变化敏感的特征。
具体来讲,我们首先利用反向传播算法计算每个损失对于各个滤波器的梯度,然后根据梯度值的大小来确定每个滤波器的重要性,以此来生成适用于追踪的特征。我们将具有目标感知性的特征用于孪生网络框架来实现追踪。大量的实验结果表明,相较于当前的主流方法,我们提出的方法不论是在准确率方面还是在运行速度方面都能取得不错的效果。
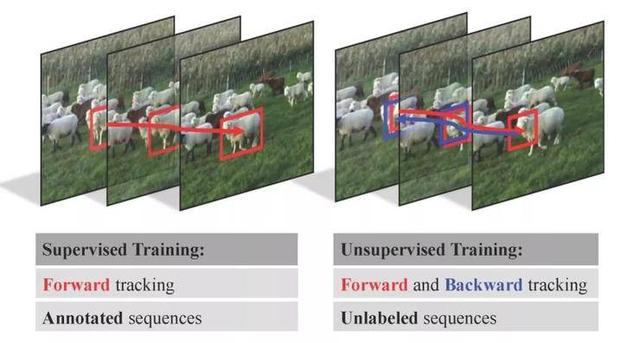
5.深度无监督式目标跟踪
Unsupervised Deep Tracking
本文由腾讯AI Lab主导,与中科大和上海交通大学合作完成,提出了一种基于无监督学习的目标跟踪方法。不同于之前的利用大量标注数据的监督学习方法,我们是利用未标注的视频数据来训练深度卷积网络。我们的启示是一个鲁棒的跟踪 器应当在前向和后向的跟踪过程中均有效,即跟踪 器能够前向跟踪目标物体并逐帧回溯到第一帧的初始状态。我们利用孪生网络实现了新提出的方法,该网络完全由没有标注的视频数据训练而成。
与此同时,我们提出了一个利用多轨迹优化和损失敏感的衡量函数来进一步提升跟踪性能。单纯利用无监督学习方法,我们的跟踪 器就能达到需要精确和完整训练数据的全监督学习的基本水平。更值得关注的是,我们提出的无监督学习框架能够更深入地利用未标注或者部分标注的数据来进一步提升跟踪性能。
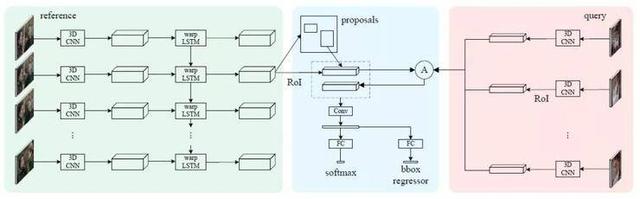
6.基于WarpLSTM的时空视频再定位
Spatio-Temporal Video Re-localization by Warp LSTM
本文由腾讯AI Lab主导,与罗切斯特大学合作完成。随着网络上视频井喷式的增长,高效地找到用户想要的视频的需求也随之增长。现有的基于关键词的检索方法只能获知某些视频内容存在与否,并不能获知视频内容出现的时间和位置。本文提出了定位视频内容出现的时间和位置的时空视频再定位任务。给出一个查询视频和一个备选视频,时空视频再定位任务的目标是在备选视频当中找到一个和查询视频相关的时空片段。
为了准确地定位,我们提出了一个新的WarpLSTM网络,这种网络的优势是它可以提取视频当中的长时间的时空信息。为了解决时空视频再定位问题遇到的另外一个困难,即缺少标注数据,我们重新组织了AVA数据集当中的视频,得到了一个用于时空再定位研究的新数据集。实验表明我们提出的模型能取得优于基线方法的定位结果。
7.不是所有帧都相同:基于上下文相似度和视觉聚类损失的弱监督视频定位
Not All Frames Are Equal: Weakly Supervised Video Grounding with Contextual Similarity and Visual Clustering Losses
本文由腾讯AI Lab与罗彻斯特大学合作完成。我们研究的问题是仅提供视频层面的句子描述的弱监督视频定位,即在没有物体位置标注的情形下将语言的关键词定位到视频中的空间中。这是一个有挑战性的任务;首先,视频中有许多帧,会出现帧和语言描述不一定匹配的不一致问题;其次,尽管网络中有大量的视频,但是标注物体位置具有高昂的成本。并且。之前的基于多示例学习(MIL)的图像定位方法难以有效用于视频定位。最近的工作试图将视频层级的MIL分解为帧级别的MIL,通过将句子与帧之间的相似度作为权重作用到每一帧上,但是这样做并不鲁棒并且无法利用丰富的时序信息。
在本文中,我们利用假阳性帧包(frame-bag)限制来扩展帧级别的MIL,并且建模了视频时序特征一致性。特别地,我们设计了形义和视觉特征的上下文相似度,从而克服物体在帧与帧之间的稀疏问题。更进一步,我们通过强化视觉空间中相似的特征来利用时序上的连贯性。我们在YouCookII和RoboWatch数据集上全面评估了这个模型,结果表明我们的方法较之间方法能够大幅度提升性能。
8.基于多粒度分析的时序动作提名生成器
Multi-granularity Generator for Temporal Action Proposal
本文由腾讯AI Lab主导,与东南大学、哥伦比亚大学合作完成。时序动作提名是一项重要任务,其目的在于定位未修剪视频中含有人类动作的视频片段。我们提出了使用多粒度生成器来完成时序动作提名,其能从不同的粒度分析视频并嵌入位置信息。
首先,我们使用双线性匹配模块来探索视频序列中丰富的局部信息,随后我们提出的片段动作生产器和帧动作生成器两个模块能从不同的粒度分析视频。片段动作生产器以粗粒度的方式,通过特征金字塔的形式感知整个视频并产生长度各异的动作提名;帧动作生成器则对每一个视频帧采取细粒度的分析。虽然多粒度生成器涉及多个模块,在训练过程中却能以端到端的形式进行。基于帧动作生成器细粒度的分析,片段动作生产器产生的动作提名可以被进一步位置微调,从而实现更精准的定位。
因此,相比于目前最优的模型,多粒度生成器在两个公开的数据集ActivityNet1.3和Thumos14上都获得了更好的效果。另一方面,在多粒度生成器产生的动作提名基础上采用现有的分类器进行分类,相比于目前性能较优的视频检测方法,多粒度生成器都获得了明显的提升。
9.基于预测运动和外观统计量的自监督视频时空表征学习
Self-supervised Spatio-temporal Representation Learning for Videos by Predicting Motion and Appearance Statistics
本文由腾讯AI Lab与香港中文大学、华南理工大学合作完成。本文首先阐述了在无人工标注标签时的视频表征学习问题。虽然之前也有工作通过设计新颖的自监督任务来进行视频的表征学习,但学习的表征一般都基于单帧图像,而无法用于需要多帧时空特征的主流视频理解任务。我们在本文中提出了一种新颖的自监督方法,可学习视频的多帧时空表征。
受到视频分类任务中的two-stream类方法的启发,我们提出通过回归时空两个维度的运动和外观的统计量来进行视觉特征学习。
具体来说,我们在多个视频帧的时空两个维度上提取一些统计概念(例如快速运动区域及其相应的主要运动方向、时空上的色彩多样性、主导颜色等)。不同于之前的一些预测稠密像素值的方法,我们提出的方法与人类固有的视觉习惯一致,并且易于学习。我们用C3D作为基干网络进行了大量实验,结果表明该方法可以显着提高C3D用于视频分类等任务时的性能。
人脸
Human Face
人脸分析与识别已经在一些娱乐、安检和身份校验等应用中得到了实际应用,但该领域仍存在一些有待解决的问题,比如如何适应视角变化、如何在不同的环境(比如弱光环境)中有效工作、如何鉴别被识别的脸是否真实、如何判别相似的人脸(比如脸部一样的双胞胎)、如何识别特殊的人脸(比如受伤或有伪装的人脸)以及分析人脸随时间的变化。另外,人脸的重建也是很重要的研究方向,在游戏和虚拟助手等方面有很有价值的应用前景。
腾讯 AI Lab 今年有多篇与人脸相关的研究论文入选 CVPR,涉及到跨年龄人脸识别、人脸活体检测和、多视角 3D 人脸重建、人脸面部动作单位强度估计、人脸识别系统的对抗攻击研究等方向。其中,在人脸活体检测方面的研究与我们支持的云智慧眼业务密切相关,这是我们在公司内首推而且在 H5 场景下属于业界首创的静默活体检测技术(静默活体检测指的是不需要用户交互配合即可完成人脸活体检测,非常易用。
1.人脸活体检测:模型很重要,数据也是
Face Anti-Spoofing: Model Matters, So Does Data
本文由腾讯AI Lab主导,与上海交通大学合作完成,为人脸活体检测提出了一种新模型和新的数据收集方法。活体检测在全栈的人脸应用中扮演着重要的必不可少的角色,它的目的是为了检测摄像头前的人脸是真人样本还是伪造的攻击样本(比如翻拍的人脸照片或者预先录制的人脸视频等)。
以往方法的模型通常基于一些不能很好模拟真实场景的数据库,这会影响到模型的泛化性能。本文提出了一种数据收集的解决方案,可以很好地模拟真实的活体攻击,从而能以很低的成本快速获取大量训练数据。
我们还开发了一个利用时空信息的活体检测模型,将当前公开数据库上面的性能推进了一大步。我们的模型可以自动关注有助于区分活体和非活体的局部区域,这也能帮助我们分析网络的行为。实验结果也表明我们的模型可以关注到摩尔纹、屏幕边缘等一些区域,进而实现更好的活体检测。
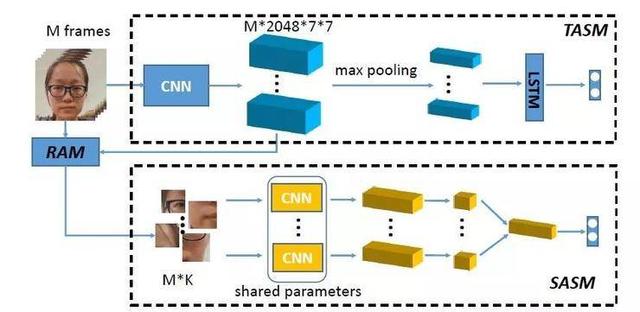
2.针对跨年龄人脸识别的去相关对抗学习
Decorrelated Adversarial Learning for Age-Invariant Face Recognition
本文由腾讯AI Lab独立完成。跨年龄人脸识别问题受到了非常广泛的研究关注。然而,识别年龄间隔较大的人脸图像仍然非常具有挑战性,这主要是因为年龄变化会引起人脸图像呈现出较大的差异。
为了减少年龄变化所造成的差异,本文提出一个全新的算法,目的在于去除混合了身份和年龄信息的人脸特征中的年龄成分。具体而言,我们将混合的人脸特征分解成为两个不相关的组成成分:身份成分和年龄成分,其中的身份成分包含了对人脸识别有用的信息。
为了实现这个想法,我们提出去相关的对抗学习算法,其中引入了一个典型映射模块,用于得到生成的成分特征之间的最大相关性,与此同时主干网络和特征分解模块则用于生成特征以最小化这个相关性。这样,主干网络能够学习得到身份特征和年龄特征并使得其相关性显著降低。与此同时,身份特征和年龄特征通过身份保持和年龄保持的监督信号进行学习,以确保它们的信息正确。我们在公开的跨年龄人脸识别数据集(FG-NET、MORPH Album 2 和 CACD-VS)进行了实验,结果表明了这个方法的有效性。
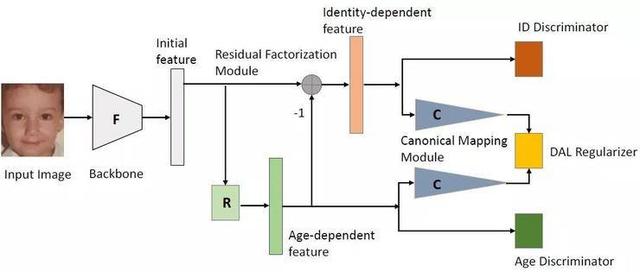
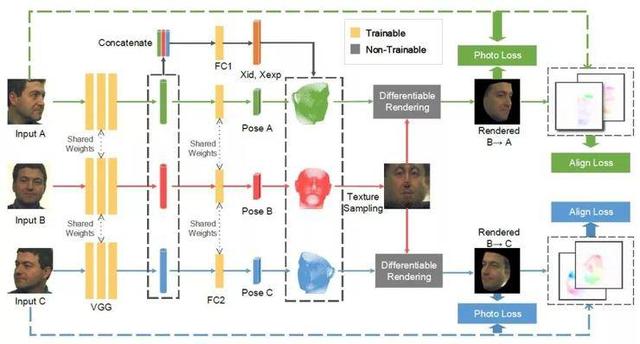
3.MVF-Net: 多视角3D人脸可变形模型的参数回归
MVF-Net: Multi-View 3D Face Morphable Model Regression
本文由腾讯AI Lab主导,与香港中文大学合作完成。本文阐述的问题是用多视角人脸图片作为输入重建3D人脸模型。虽然最新的基于3D人脸可变形模型(3DMM)的方法取得了不少进步,但大部分工作仍局限于单张照片的输入。
单张照片3D人脸重建有一个内在的缺点:缺乏3D约束会导致无法解决的几何结构混淆。我们在本文中探索了给定多视角人脸照片输入的设定下进行基于3DMM的3D人脸重建问题。我们提出了一种全新的使用端到端卷积神经网络来回归3DMM参数的方法。在这个方法中,通过使用一种新型的自监督视角对齐损失函数,模型能建立不同视角之间的稠密像素对应关系,从而引入多视角几何约束。
该新型损失函数使用可导的光流估计模块将投影合成的目标视角图像与原始输入图像之间的对齐误差反向传播回3DMM参数的回归中。这样就能在最小化损失函数的过程中恢复对齐误差较小的3D形状。实验验证了多视角照片输入相对于单张照片输入的优势。
4.基于联合表征和估计器学习的人脸面部动作单元强度估计
Joint Representation and Estimator Learning for Facial Action Unit Intensity Estimation
本文由腾讯AI Lab主导,与中科院自动化研究所和美国伦斯勒理工学院合作完成,提出了一种用于人脸面部动作单元强度估计的新方法。人脸面部动作单元描述的是人脸上局部的肌肉运动,对其强度的估计面临着两个难题:其表观变化难以捕捉;含有面部动作单元标注的数据集较少。
我们针对这些难题提出了一个样本特征和回归模型联合学习框架。该框架可以灵活地嵌入各种形式的先验知识,且仅需少量标注数据集即可进行模型学习。实验结果表明,该方法在标注数据较少时能得到比现有算法更好的结果。深度学习模型可视为联合学习特征和回归的模型,但训练数据不足时会发生严重的过拟合;而我们提出的方法即使仅有 2% 的标注数据,也依然可以达到较好的效果。
视觉-语言技术
Visual - Language Technology
视觉和语言是人类了解世界以及与世界交流的两种主要方式,深度学习技术的发展为这两个原本相对独立的学科搭建了桥梁,使这个交叉领域成为了计算机视觉和自然语言处理的重要研究方向。这个研究方向的基本问题是用语言描述图像或视频中的内容,在此基础上,我们可以查询图像或视频中与语言描述相关的部分,甚至根据语言描述的内容生成对应的视觉内容。视觉-语言技术在视频网站、视频处理、游戏以及与人沟通的机器人等许多领域都会有重要的应用。
腾讯 AI Lab 有多篇 CVPR 入选论文探索了这一技术领域的新方法,除了下面的两篇,上文“视频”部分也介绍了基于语言查询定位视频片段的研究。
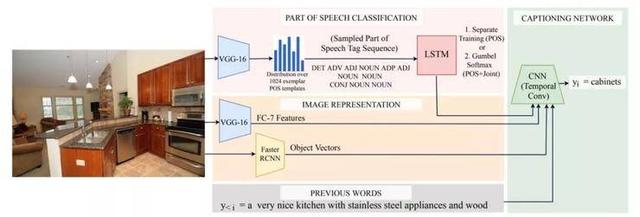
1.基于词性的快速准确且多样化的图像生成自然语言描述方法
Fast, Diverse and Accurate Image Captioning Guided By Part-of-Speech
本文由美国伊利诺伊大学香槟分校(UIUC)与腾讯AI Lab 合作完成,是CVPR oral 展示论文之一,提出了一种新的基于输入图像生成自然语言描述的方法。针对输入的图像,我们首先生成有语义的图像总结,然后利用这种图像总结来产生自然语言描述。我们利用词性标签序列来表达这种总结内容,再利用这种表达来驱动图像描述的生成。
我们的方法实现了
(1)更高的准确率;
(2)比传统波束搜索等更快的多样化句子生成速度;
(3)更加多样化的语言描述。
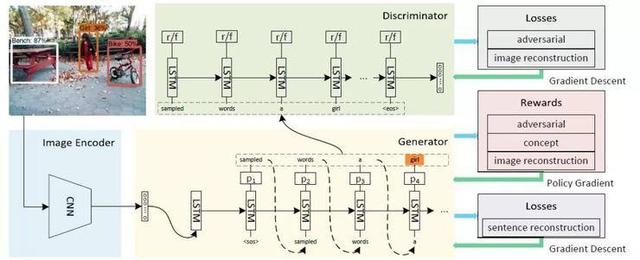
2.无监督图像描述生成
Unsupervised Image Captioning
本文由腾讯 AI Lab 主导,与罗切斯特大学合作完成,提出了一种无监督图像描述生成模型。深度神经网络模型在图像描述任务上取得了巨大的成功。但是大多数现有的图像描述模型都依赖图像-句子对,而这种图像-句子对的收集过程又成本高昂。本文首次尝试用无监督的方式来训练图像描述模型。
我们提出的方法仅需要一个图片集、一个句子集和一个已有的检测模型。我们用句子集来让图像描述模型学习如何生成通顺的句子,同时我们把检测模型的知识蒸馏到图像描述模型当中,从而使得后者可以识别图像内容。为了让图像和生成的描述更加相关,我们把图像和描述语句投影到了同一个语义空间。因为已有的句子集主要是为语言研究设计的,它们涉及的图像内容不多,并不适合用于无监督图像描述研究。所以我们从网上下载了二百万个图像描述用于此项研究。实验表明我们提出的模型可以在没有使用任何标注句子的情况下,生成合理的图片描述。
图像分割
Image Segmentation
图像分割是指将图像细分为多个图像子区域(像素的集合)的过程,可简化或改变图像的表示形式,使得图像更容易理解和分析。图像分割可用于定位图像中的物体和边界,这在移动机器人和自动驾驶等需要对目标的范围有精确判定的应用中具有非常重要的价值。图像分割方面的难题包括如何设定不同的分割层次、分析不常见目标的形状、不同视角与深度的场景、对遮挡情况的处理以及边缘的精确认定等等。
腾讯AI Lab 有多篇 CVPR 入选论文在图像和视频分割上做出了有价值的贡献。除了前文用于视频对象分割的 MHP-VOS,我们还提出了一种不依赖于物体检测的人体实例分割方法,并为之创造了一个新的数据集。另外,我们还探索了室内场景形义分割与人群计数问题。
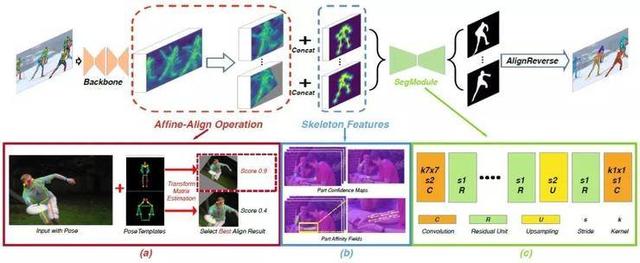
1.Pose2Seg:不依赖于物体检测的人体实例分割
Pose2Seg: Detection Free Human Instance Segmentation
本文由腾讯AI Lab、清华大学和卡迪夫大学合作完成,提出了一种不依赖于物体检测的人体实例分割方法和一个新的数据集。目前主流的图像实例分割方法大多需要首先从图像中检测物体的包围框,然后从包围框中分割目标对象。Mask R-CNN 等最新的一些工作将这两个步骤合二为一。
但是很少有研究考虑到“人”这一类别的特殊性——“人”不仅可以通过包围框定位实例,还可以通过骨骼姿态检测来定位。同时,在一些严重遮挡的情况下,相比于包围框,人体骨骼姿态可以更有效地区分不同的实例。
本文提出了一种全新的基于姿态的人体实例分割框架,可通过人体姿态检测来分离实例。我们通过大量实验证明了基于姿态的实例分割框架可以比最先进的基于包围框的实例分割方法获得更好的准确性,同时还可以更好地处理遮挡情况。
此外,由于目前很少有公开数据集包含大量的丰富标注的严重遮挡实例,使得遮挡问题很少被研究者注意到。在本文中我们还公开了一个新的数据集“Occluded Human (OCHuman)”。这个数据集包含4731张图像,有8110个详细标注的人体实例。标注信息包括包围框、实例分割掩码以及人体姿态关键点。全部人体实例都存在严重的互相遮挡,因此这个数据集是目前最有挑战的数据集。通过这个数据集,我们希望强调遮挡问题的挑战性,并推动在检测以及分割中对遮挡问题的研究。
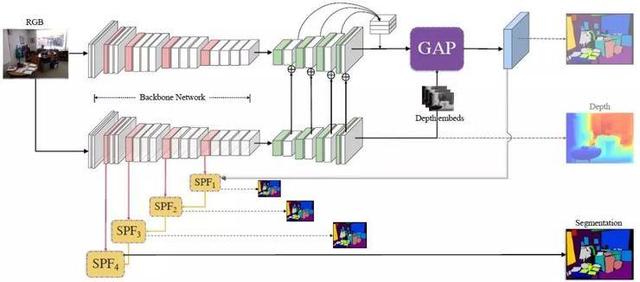
2.基于几何感知知识蒸馏方法的室内场景形义分割
Geometry-Aware Distillation for Indoor Semantic Segmentation
本文由腾讯AI Lab与伊利诺伊大学香槟分校、香港城市大学合作完成,提出了一种新的室内场景语义分割方法。已有研究表明,联合推理来自RGB-D域的2D外观和3D信息有利于室内场景语义分割。然而,大多数现有方法需要精确的深度图作为输入来分割场景,这严重限制了它们的应用。
在本文中,我们提出通过提取几何感知嵌入特征来联合推断语义和深度信息,以消除这种强约束,同时仍然利用有用的深度域信息。
此外,我们还提出了几何感知传播框架和多级跳过特征融合模块,可使用这种学习嵌入来提高语义分割的质量。通过将单个任务预测网络解耦为语义分割和几何嵌入学习这两个联合任务,加上我们提出的信息传播和特征融合架构,我们在若干公开的具有挑战性的室内数据集上进行了实验,结果表明我们的方法可以超过目前最先进的语义分割方法。
应用价值:
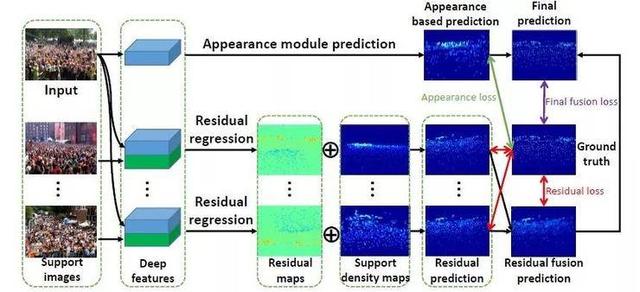
3.基于残差回归和形义先验的人群计数
Residual Regression with Semantic Prior for Crowd Counting
本文由腾讯AI Lab主导,与香港城市大学合作完成。人群计数是一个很有挑战性的问题。最近基于深度学习的方法虽然取得了一些进展,但是样本之间的相关性带来的知识还没被全面挖掘。本文提出了利用残差回归来学习样本之间的相关性。通过融入相关性,我们实现了人群计数性能的提升。我们也展示了怎样如何有效地利用形义先验来提升模型性能。另外我们还观察到对抗损失可以用来提升预测的密度图质量,继而提升结果。实验结果证明了我们方法的有效性和泛化能力。
机器学习和优化方法
Machine Learning and Optimization Methods
基于卷积神经网络的深度学习确实已经推动计算机视觉领域实现了巨大的进步,但这个方法还远非完美,在少样本学习、学习效率和泛化能力等问题上还有很多改进的空间。同时,人工智能研究界也在不断探索新的机器学习方法以及为各种机器学习技术提供理论验证和支持。
今年的 CVPR 上,我们入选的论文涵盖单样本学习、开放域学习、模型压缩、多任务与自适应学习等多个研究方向,也在训练方法等方面做出了一些理论研究贡献——我们首次提出了一种全新的用于保证 Adam/RMSProp 的全局收敛性的充分条件,还提出了一种用于稀疏广义特征值问题的分解算法。
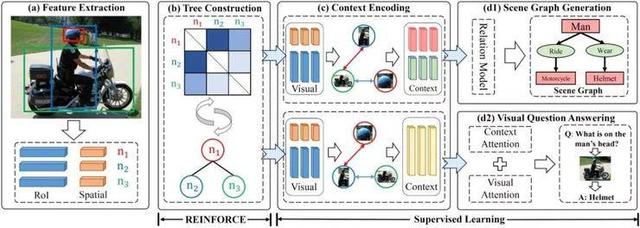
1.为视觉环境构建动态树结构的学习方法
Learning to Compose Dynamic Tree Structures for Visual Contexts
本文由腾讯AI Lab与新加坡南洋理工大学合作完成,是CVPR oral 展示论文之一。我们提出了一种动态树构建方法,可将图像中的物体放置到一个完整的视觉环境中。该方法有助于解决场景图生成、视觉问答等视觉推理问题。
相比于现有的结构化物体表示方法,我们提出的视觉环境树模型VCTree具有两大优点:1)二叉树非常高效且具有很强的表示能力,可以学习物体之间内在的并行或层次关系(例如,“衣服”和“裤子”往往同时出现,且它们都属于人的一部分);2)不同图像和任务的动态结构往往各有不同,我们的模型能捕获这种变化,从而在物体之间传递依赖于具体图像内容和任务的信息。
在构建VCTree时,我们设计了一种评分函数来计算每一对物体和给定任务的有效性,从而得到物体之间的评分矩阵。然后我们在该评分矩阵上构建最大生成树,并进行二值化。随后,我们采用双向树LSTM模型对VCTree进行编码,并利用任务相关的模型进行解码。我们开发了一种混合学习流程,将监督学习和树结构强化学习结合到了一起。我们在场景图生成和视觉问答这两个视觉推理任务上进行了充分的实验,结果表明VCTree不仅在这两个任务上优于当前最佳方法,同时还能挖掘出可解释的视觉环境。
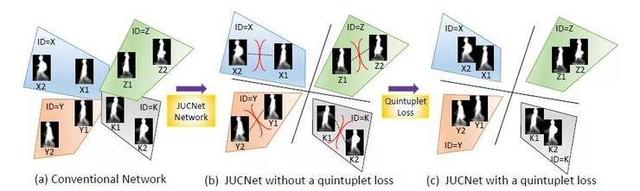
2.基于五胞胎损失的步态联合学习
Learning Joint Gait Representation via Quintuplet Loss Minimization
本文由腾讯AI Lab主导,与澳洲国立大学合作完成,是CVPR oral 展示论文之一。步态识别是指通过走路的模态来远距离地识别一个人,这是视频监控领域一个重要问题。现有的方法要么是通过单张步态图来学习独一的步态特征,要么是通过一对步态图来学习不同的步态特征。有证据表明这两种方法是互补的。
在本文中,我们提出了一种步态联合学习的网络,其融合了这两种方法的优势。另外,我们还提出了一种“五胞胎损失”,通过该损失可以同时最小化类内差和最大化类间差。实验结果表明我们提出的方法取得了当前的最佳性能,超过了现有的方法。
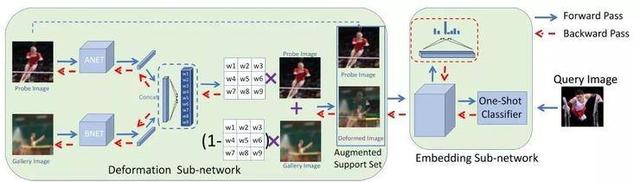
3.基于图像变形元网络模型的单样本学习
Image Deformation Meta-Networks for One-Shot Learning
本文由腾讯AI Lab、复旦大学、卡耐基梅隆大学合作完成,是CVPR oral 展示论文之一。人类可以精确地识别和学习图像,即使图像缺少了一块或与另一幅图像相重叠。结合这种能力来合成包含新概念的变形实例可以帮助视觉识别系统完成更好的单样本学习,即从一个或少数几个示例中学习相应的视觉概念。
我们的主要观点是:虽然变形的图像可能在视觉上不真实,但它们仍然保有关键的形义信息,并且对相应的分类器决策边界有很大贡献。受到最近元学习进展的启发,我们将元学习者与图像变形子网络结合起来,进而产生额外的训练样例,并以端到端的方式同时优化两个模型。变形子网络通过融合一对图像来得到相应的变形图像。在业界公认的单样本学习的基准数据集上(即miniImageNet和ImageNet 1K Challenge),我们所提出的方法明显优于现有技术。
4.Adam 和 RMSProp 收敛的充分条件
A Sufficient Condition for Convergences of Adam and RMSProp
本文由腾讯AI Lab主导,与石溪大学合作完成,是CVPR oral 展示论文之一。Adam/RMSProp作为用于训练深度神经网络的两种最有影响力的自适应随机算法,已经从理论上被证明是发散的。针对这一问题,目前的作法是通过对 Adam/RMSProp 的算法结构进行修改来促进Adam/RMSProp 及其变体收敛。常用的策略包括:降低自适应学习速率、采用大的batch-size、减少学习率与梯度的相关性。
在本文中,我们首次提出了一种全新的充分条件来保证 Adam/RMSProp的全局收敛性。该充分条件仅取决于基本学习速率参数和历史二阶矩的线性组合参数, 并且无需对 Adam/RMSProp 算法结构做任何修改。根据文中提出的充分条件,我们的结论直接暗含 Adam 的几个变体(AdamNC、AdaEMA等)的收敛性。
另外,我们严格说明 Adam 可以等价地表述为具有指数移动平均动量的 Weighted AdaGrad,从而为理解 Adam/RMSProp 提供了新的视角。结合这种观察结果与文中提出的充分条件,我们更深入地解释了Adam/RMSProp 发散的本质原因。最后,我们实验了应用 Adam/RMSProp 来解决反例和训练深度神经网络,从而对本文提出的充分条件进行了验证。结果表明,数值结果与理论分析完全一致。
雷锋网雷锋网雷锋网
Ps:想要了解更多顶会动态?那就点击链接加入CVPR顶会交流小组吧
https://ai.yanxishe.com/page/meeting/44%EF%BC%9F=leifeng



















