一种基于学习视觉动力学方法,自动驾驶汽车的非线性模型预测控制
自动驾驶车辆的研究可分为感知、定位、决策、规划、控制等层面,其中控制层的任务是根据规划层输出的参考轨迹,结合车辆自身状态,控制车辆跟踪参考轨迹形式,实现车辆的纵、侧向控制。车辆的纵向控制主要实现速度的跟踪,侧向控制则实现路径的跟踪。近年来,基于车辆运动学与动力学模型的模型预测控制(MPC)理论在自动驾驶车辆控制方面得到了广泛的应用,MPC基于预先设定的系统模型,通过滚动优化,解决设定的优化问题并求解出控制输入。MPC的优点在于能够系统地处理输入和输出的约束,适用于多输入多输出控制系统,同时可以明确地考虑系统的时间延迟。
摘要:在本文中,我们介绍了一种基于学习的视觉动力学方法,用于自动驾驶汽车的非线性模型预测控制(NMPC),即基于学习的视觉动力学(LVD)NMPC。LVD-NMPC使用先验过程模型和学习视觉动力学模型来计算驾驶场景的动力学,受控系统的期望状态轨迹以及由约束预测控制器优化的二次成本函数的加权增益。视觉系统被定义为一个深度神经网络,旨在估计图像场景的动态。输入基于感官观察和车辆状态的历史序列,由增强记忆组件集成。深度Q学习用于训练深度网络,深度网络一旦经过训练,也可用于计算车辆的所需轨迹。我们根据使用标准NMPC执行的基线动态窗口方法(DWA)路径规划以及 PilotNet神经网络来评估LVD-NMPC。性能是在我们的模拟环境GridSim,真实世界的1:8比例模型车以及真实尺寸的自主测试车辆和nuScenes计算机视觉数据集上测量的。
关键词:自动驾驶汽车,视觉动力学,学习控制,人工智能,深度学习,感知与控制,机器人视觉
1 引言
在过去的十年里,学术界和工业界都在大力推进自动驾驶领域的研究。自动驾驶汽车是配备了驾驶功能的智能主体,旨在了解周围环境并获得控制行动。如Grigorescu等人对自动驾驶的深度学习调查所示[1]。驱动函数传统上被实现为感知规划-行动管道。最近,Bojarski等人[2]和Pan[3]等人提出了基于End2End学习的方法。或者Kendall[4]等人提出的深度强化学习(DRL)”也被提出,尽管主要是作为研究原型。
在模块化的感知-规划-行动系统中,视觉感知通常与低阶控制解耦。基于视觉伺服的概念,在机器人操作领域研究了感知和控制的紧密耦合,如Gu[5]等人的操作故障检测器。然而,在自动驾驶汽车中却并非如此,因为不同模块之间的内在依赖关系并未被考虑在内。
这项工作是对视觉动力学和控制领域的贡献,其中提出的基于学习的视觉动力学非线性模型预测控制(LVD-NMPC)算法用于控制自动驾驶汽车。学习控制中视觉动力学概念的介绍可以在Grigorescu的工作中找到[6]。LVD-NMPC的框图如图1所示,其中主要组件是定义为深度神经网络(DNN)的视觉动力学模型和约束非线性模型预测控制器,它接收来自视觉模型的输入。该模型使用 Q 学习算法进行训练,可计算所需的状态轨迹和 NMPC 的调谐增益。
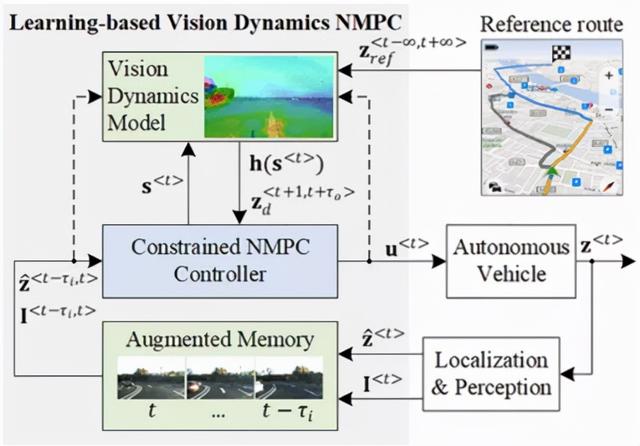
图1. LVD-NMPC:基于学习的视觉动力学、自动驾驶汽车非线性模型预测控制。虚线说明了训练期间使用的数据流。LVD-NMPC:基于学习的视觉动力学非线性模型预测控制。
数据驱动和经典控制方法之间的协同作用已被考虑用于模仿学习,其中转向和加速控制信号以End2End方式计算,正如Pan[3]等人所提出的那样,他们的方法设计用于具有预定义边界的驾驶环境,驾驶轨道上不存在任何障碍物。
正如Grigorescu[1]等人所显示的那样,这种传统的解耦视觉感知系统使用视觉定位来估计自我车辆相对于参考轨迹的姿势,以及障碍物检测。路径和行为规划器进一步使用该信息来确定由运动控制器执行的安全驾驶轨迹。在我们的工作中,我们通过用学习的视觉动力学模型取代经典的感知规划管道来改进传统的视觉方法。该模型用于计算安全驾驶轨迹,并估计NMPC二次成本函数的最佳调谐增益。我们的公式利用了基于模型的控制的优势和深度学习方法的预测能力,使我们能够将视觉动态封装在DNN的层中。本文的主要贡献如下:
1.基于先验过程模型和视觉动力学模型的自动驾驶汽车LVD非线性模型预测控制器;
2.DNN架构,用作非线性视觉动力学近似器,用于估计最佳所需状态轨迹和NMPC的调谐增益;
3.一种基于模仿学习和Q-learning训练方法的LVD非线性模型预测控制器的训练方法。
本文的其余部分组织如下。下一节将介绍相关的工作。在“视觉动力学模型学习与控制系统”部分给出了LVD-NMPC的方法,并给出了实验结果。最后,在“结论”部分对文章进行了总结。
2 相关工作
近年来,将深度学习技术应用于自动驾驶的趋势越来越明显,特别是在End2End学习领域,如Pan[3]等人, Fan[7]等人和Bojarski[2]等人,提出的方法以及DRL,基于DRL的自动驾驶的相关算法可以在Kiran[8]等人,Kendal[4]等人,和Wulfmeier[9]等人的作品中找到,机器学习技术也被用到更传统的控制方法中,例如NMPC,Lucia和Karg[10]的不确定性感知NMPC以及Ostafew[11]等人和McKinnon以及Schoellig[12]的学习控制器。
End2end学习,正如Amini[13]等人所描述的那样,直接映射原始输入数据来控制信号。LVD-NMPC中的方法类似于Pan[3]等人考虑的方法,与我们的方法相比,他们的DNN策略经过训练,可以在预定义的无障碍轨道上进行敏捷驾驶。这种方法限制了他们的系统对自动驾驶的适用性,因为自动驾驶汽车必须通过动态障碍物和未定义的车道边界在道路上行驶。Zeng[14]等人提出了一种end2end神经运动规划器,而Fan[7]等人设计了一个End2End学习系统来预测可驾驶表面。这项工作没有考虑障碍物检测和回避,仅改进了感知系统,而没有解决感知和低级车辆控制之间的内在依赖性。
DRL是一种机器学习算法,其中代理通过与其环境交互来学习操作。Kiran[8]等人已经发表了对用于自动驾驶的DRL的广泛综述:DRL对现实世界物理系统的主要挑战。在我们的例子中,智能体(即自动驾驶汽车)通过探索其环境来学习。逆强化学习(IRL)提供了一个解决方案,它是一种用于求解马尔可夫决策过程的模仿学习方法。Wulfmeier[9]等人使用卷积DNN扩展了最大熵IRL,用于学习城市环境中的导航成本图。然而,这种方法通常不考虑车辆的状态和低电平控制所需的反馈回路。
NMPC,正如Garcia[15]等人所提出的,是一种控制策略,它通过解决围绕非线性动态系统模型定制的优化问题来计算控制动作。在过去的几十年中,它已成功应用于研究和汽车行业的自动驾驶应用。Nascimento[16]等人和Nasciment[17]等人提出了非线性模型预测控制器,用于非全息移动机器人的轨迹跟踪。为了处理不确定性,Lucia和Karg[10]以及Gango[18]等人已经使用了基于学习的模型预测控制方法来近似显式NMPC系统。
学习控制器(传统的反馈控制器),如NMPC,利用由固定参数组成的先验模型。与具有固定参数的控制器不同,学习控制器利用训练信息来学习其模型。在以前的工作中,已经引入了基于简单函数近似器的学习控制器,例如Ostafew[11]等人工作中的高斯过程建模或McKinnon和Schoellig[12]的贝叶斯回归算法。
针对现有方法及其局限性,提出LVD-NMPC方法将驾驶场景的动力学封装在视觉动力学模型中,使约束NMPC适应执行所需的车辆状态轨迹。
3 视觉动力学模型学习与控制系统
3.1 问题定义
图二显示了自动驾驶问题的简单说明。给定过去的车辆状态
![]()
,一系列观测值
![]()
,和用于跟踪的全局参考路线
![]()
,任务是计算控制信号
![]()
,时间t+1, 使自动驾驶汽车跟踪安全轨迹
![]()
, 考虑一个离散采样时间
![]()
和
![]()
分别是过去和未来的时间视界。
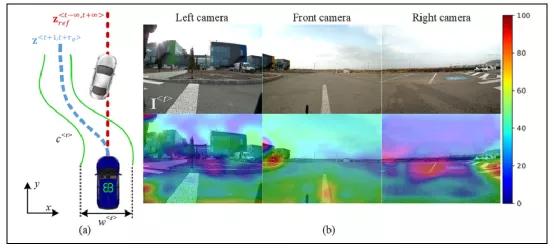
图2. 自动驾驶问题定义。给定车辆的状态、全局路线(红线)和一组感官测量值,目标是计算在控制视线上进行跟踪(蓝线)的安全路径
![]()
,视觉动力学模型估计曲率
![]()
,和宽度
![]()
的道路。(a)避障说明。(b)观察
![]()
视觉动力学模型中的(顶部图像)和激活图(底部图像)。色度尺度显示了激活图中神经元在像素级的贡献,其中红色对应于高贡献,蓝色对应于几乎没有贡献(最好以颜色查看)。
参考轨迹
![]()
引用表示从车辆起始位置到目的地应跟随的全局路线。它可以作为一组航点给出(例如GPS坐标)。因为
![]()
是一个全球轨迹,它被认为在
![]()
间隔,
![]()
与所需的轨迹
![]()
不同,后者是为
![]()
区间计算的,
![]()
由非线性模型预测控制器执行,并且必须考虑可驾驶区域和场景中存在的障碍物。
该车辆基于Paden[19]等人描述的机器人的运动学自行车模型建模,具有位置状态
![]()
和非滑移假设。x,y和ρ分别表示车辆在2D驾驶平面中的位置和航向。我们将纵向速度和转向角作为控制动作:
![]()
,其中
![]()
是质量中心当前速度相对于汽车纵轴的角度,如Borrelli[20]等人所提出的。
驾驶场景建模为视觉动态状态
![]()
,其中c和w是道路的曲率和可遍历宽度。在估计所需轨迹时,高w对应于宽松约束,而低w表示必须精确遵循以满足安全约束的路径。我们考虑可遍历宽度的规范化值
![]()
,其中1是最大道路宽度,0表示不可行驶区域,在这种情况下,车辆必须停车。
获取训练样本时,以下数量存储为序列数据:历史位置状态
![]()
,从前置摄像头获取的感官信息
![]()
,全局参考轨迹
![]()
和从人类驾驶员处录制的控制操作
![]()
。出于实际原因,全局参考轨迹存储在采样时间t的有限视界
![]()
上。单个图像对应于观测实例
![]()
,而连续的图像序列表示为
![]()
3.2 控制系统设计
LVD-NMPC的方框图如图1所示。考虑以下非线性的状态空间系统
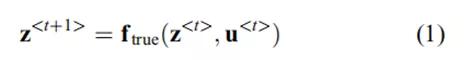
其中
![]()
为可观测状态,
![]()
为平均状态,
![]()
为离散时间t的控制输入。我们假设每个状态测量都被方差
![]()
的零均值加性高斯噪声破坏。
![]()
近似为先验模型和基于经验的视觉动态模型之间的和。

其中,
![]()
代表环境依赖关系。
这些依赖关系由系统和环境在t时刻的状态组成,定义为
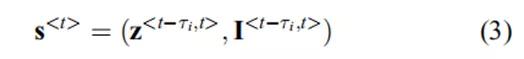
其中,
![]()
表示由所谓的增强内存组件沿时间间隔
![]()
集成的历史依赖关系集。模型
![]()
和模型
![]()
均为非线性过程模型。
![]()
是一个已知的过程模型,代表了我们对
![]()
的知识,而
![]()
是学习到的视觉动力学模型。当采样时间定义为
![]()
时,LVD-NMPC所采用的标称过程模型为
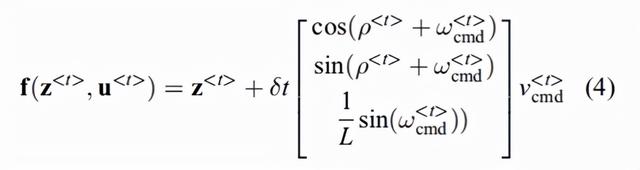
其中,
![]()
是前轮和后轮之间的长度。我们区分了给定的参考轨迹
![]()
参考文献,从控制的角度来看,它实际上是无限的,以及一个期望的状态轨迹
![]()
,在有限的预测范围内计算到。最优未来状态由约束非线性模型预测控制器计算,基于期望的状态轨迹
![]()
,由视觉动力学模型估计。
视觉动力学模型学习预测驾驶场景的动态
![]()
集成的历史状态。视觉测量值被方差为
![]()
的零高斯噪声破坏。当查询时,它返回
![]()
和
![]()
给定历史状态序列的预测。方程(2)中的
![]()
模型是用
![]()
和
![]()
乘以三个加权常数来计算的。
![]()
用于修正航向,而
![]()
则调整车辆在二维驾驶平面中的位置。
该场景的动力学用于计算期望的轨迹
![]()
,考虑全局参考路径
![]()
参考。
![]()
可以解释为车辆与参考路线的定量偏差
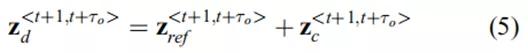
其中,
![]()
是对车辆路径的最优轨迹的视觉动力学估计,以相对于车辆姿态的
![]()
坐标计算。一旦查询到
![]()
,则基于
![]()
,通过
![]()
到采样预测路径的坐标
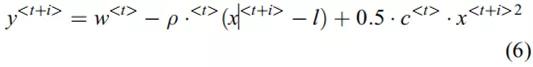
其中,
![]()
和
![]()
是在采样时间为
![]()
时计算的前向距离。正如“学习视觉动力学模型”一节中详细介绍的,使用DNN编码
![]()
和在
![]()
之上,我们定义一个二次代价函数,由约束NMPC在离散时间间隔
![]()
进行优化
![]()
其中
![]()
是一个正半定标量状态权矩阵,
![]()
是一个正定标量输入权矩阵,
![]()
是由视觉动力学模型估计的期望状态序列
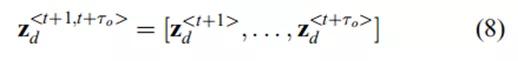
其中,
![]()
是预测状态的序列
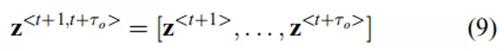
![]()
是控制输入序列
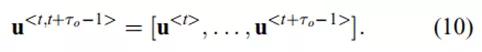
曲率
![]()
通过
![]()
中的轨迹点的多项式插值计算;而与代理的速度成正比(最大速度对应于
![]()
,而没有运动用
![]()
表示)。方程(6)用于轨迹和
![]()
之间的转换。在训练时,
![]()
是人类驱动的轨迹。
可遍历宽度
![]()
用于自动确定方程(7)中的状态和输入权重矩阵之间的比值。该操作是通过根据
![]()
加权
![]()
和
![]()
中的主对角线的系数来完成的
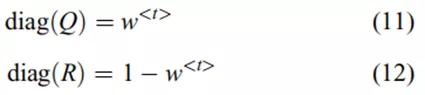
这样,当道路具有较高的遍历性时,以较高的
![]()
值表示,就可以选择更激进的控制动作。
受约束的NMPC目标是找到一组控制动作,优化车辆在给定时间范围
![]()
内的运动,同时满足一组硬约束和软约束

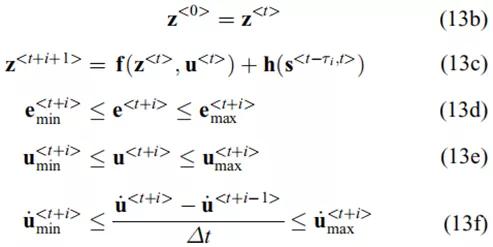
其中
![]()
为初始状态,
![]()
为控制器的采样时间。
![]()
为跨轨误差,
![]()
和
![]()
分别为跟踪的下限和上限。此外,我们分别考虑
![]()
和
![]()
分别作为执行器和执行器变化率的上下约束界。DL-NMPC-RSD控制器在每次迭代t实现了
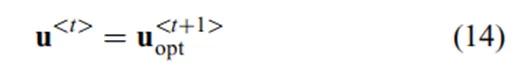
我们利用方程(7)中的二次代价函数,并利用弗莱彻的布罗伊登-弗莱彻-戈德法布-山诺算法来求解上述的非线性优化问题[21]。利用Houska等人的开源自动控制和动态优化(ACADO)工具包实时解决了方程13(a)的优化问题[22-23]。
3.3 学习视觉动力学模型
视觉动力学模型的作用是利用存储在增强记忆组件中的时间信息和全局参考轨迹
![]()
来估计场景的动态
![]()
参考。由于实际原因,我们考虑参考轨迹在有限时间间隔
![]()
内变化该模型是通过结合卷积DNN和两个长短期记忆(LSTM)网络的稳健时间预测来编码的,一个用于
![]()
中的每个元素。
虽然该模型可以直接学习局部状态序列,如格里格雷斯库等人之前的神经轨迹工作[24],我们选择学习视觉动力学模型
![]()
,它既可以用于自我载体姿态形式的状态预测,也可以用于调整NMPC的二次代价函数。
给定一系列的时间观察
![]()
:
![]()
,系统的状态
![]()
在
![]()
和在时间t参考设置点
![]()
,任务是学习
![]()
从状态
![]()
导航到目标状态
![]()
。
在强化学习术语中,自动驾驶问题可以被描述为一个部分可观察的马尔可夫决策过程(POMDP)
![]()
其中,
![]()
表示感官测量;_x0007_
![]()
是一个有限状态集;_x0007_
![]()
是一组轨迹序列,由车辆用来导航驾驶环境通过
![]()
;_x0007_
![]()
是一个随机转移函数;
是一个标量奖励,控制着
![]()
的计算;_x0007_
![]()
是一个折扣因素,调节未来奖励与即时奖励的重要性。
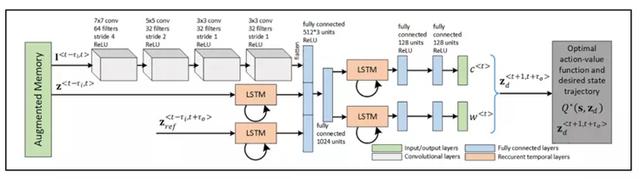
图3. 视觉动力学模型实现为一个深度神经网络。训练数据由观测序列、历史系统状态和参考状态轨迹组成。卷积神经网络首先对观测数据流进行处理。其次,单独的LSTM分支负责计算道路的曲率和宽度,然后用来获得所需的路径。LSTM:长期短期记忆。
训练的目标是找到期望的轨迹,使相关的累积未来奖励最大化。我们定义了最优动作值函数
![]()
用于计算起始
![]()
和控制命令
![]()
的状态轨迹
![]()
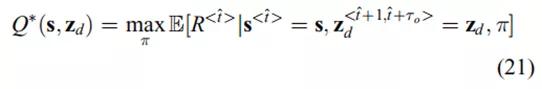
其中
![]()
是一个动作,也称为策略,将一个概率密度函数封装在一组可能发生的动作上。对于计算
![]()
,我们从图3中提出了DNN,其中连续的图像序列由一组卷积层处理,然后被输入到两个LSTM分支。
我们的深度网络是处理来自增强记忆组件的连续时间观察序列。增强内存作为缓冲区,其中观察
![]()
和车辆状态
![]()
同步并存储在过去的时间间隔
![]()
,其中
![]()
是当前时间,
![]()
是我们存储观察和状态的最大时间。我们的DNN的架构主要基于卷积层、循环层和全连接层,图3中分别为灰色、橙色和蓝色。四个卷积层的序列用于将视觉输入编码成一个潜在的一维中间表示,可以输入到后续的循环层。特别是,视觉输入首先通过64个大小为7x7,的卷积滤波器,然后是32个大小为5x5的过滤器和2个大小为32个过滤器的块,都有3x3大小。循环层已经被实现为LSTM网络,其中输入被表示通过存储在增强存储器中的序列。前两个
![]()
用于编码车辆状态序列
![]()
和给定参考轨迹
![]()
。输出被连接为一维潜在表示的扁平化扩展。完整的潜在空间由1.536个神经元组成,所有都使用校正线性单元(ReLU)激活函数激活。为了提高训练过程中的收敛性,中间表示法使用一个额外的连接层减少到1.024神经元单元。然后,该网络分支成两个头,分别负责估计道路的当前曲率
![]()
和宽度
![]()
。这两个分支都使用一个LSTM和两个连续的128个神经元的层,它们也使用ReLU功能激活。最后,利用得到的曲率和道路宽度来预测车辆
![]()
的期望未来轨迹,进而用于计算方程(16)中的最优动作值函数。
使用数据驱动技术进行控制的最大挑战之一是Pan等人描述的所谓的“DaGGer效应”[3],即当训练和测试轨迹显著不同时,性能会显著下降。应对这一现象的一个方法是确保在训练时提供足够的数据,从而提高神经网络的泛化能力。“DaGGer效应”也是为什么使用奖励函数来探索不同轨迹的深度学习方法比标准的监督模仿学习更受青睐的主要原因。在下一节中,我们表明可以实现高的泛化,证明LVD-NMPC可以安全地导航驾驶环境,即使在训练时没有遇到障碍。
4 实验
LVD-NMPC的性能基于基线非学习方法,即随机方法,以及博贾斯基等人的试点网[2]。DWA-NMPC使用了Fox等人提出的DWA[25]和Chang[26]等人用于路径规划,约束NMPC用于运动控制,依赖于Redmon和Farhadi的YoloV3算法的感知[27]。
LVD-NMPC测试了三个不同的环境:(I)在GridSim模拟器,(II)室内导航使用1:8比例模型汽车从图4(a)和(III)真实驾驶全面自动驾驶测试车辆从图4(b),以及nuSchenes计算机视觉数据集

图4. 用于数据采集和测试的测试车辆。
(a)奥迪1:8比例模型车和(b)实尺寸大众帕萨特自动测试车。
4.1 相互竞争的算法和性能指标
DWA是基于机器人操作系统DWA本地规划器实现的,并考虑了Redmon和Farhadi的YoloV3目标探测器提供的障碍[27]。对于Bojarski等人提出的PilotNet算法[2],将输入的图像直接映射到车辆的转向命令上。转向指令以0.01°的增量值执行,依赖于领航网的输出,而速度使用比例反馈律控制,增益
![]()
。
为了评估每个算法的成功率,地面真相被认为是由人类驾驶员驱动的路径。从“学习视觉动力学模型”部分出发,计算了POMDP设置中的轨迹序列
![]()
的曲率和道路宽度的地面真相。曲率由人驱动路径的多项式插值给出,而道路宽度的地面真实值与车辆的纵向速度相关。
理想情况下,每种方法都应该以最大速度导航环境,并尽可能接近地面真相。Codevilla[28]等人指出,实验3中采用的线下政策评价存在局限性,可以通过选择适当的评价指标来部分克服。Codevilla[28]等人的累积速度加权绝对误差项已被选为绩效指标。该度量旨在同等地量化实验I和实验II,它们是纯闭环实验,并在实验III中进行离线评估。此外,计算了平均速度,曲率误差
![]()
和处理时间。
![]()
表示用多项式插值计算的估计路径曲率与实际路径曲率的差值,而
![]()
定义为
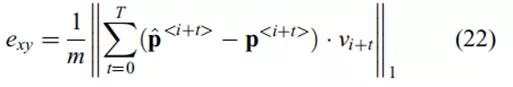
其中,和
![]()
分别是估计的轨迹和人类驱动的轨迹上的坐标。
![]()
是对
![]()
的预测视界计算的展望距离。为了比较三种竞争方法,方程(17)中的度量量化了系统的总误差。在实验I和实验II中,还测量了一种算法撞击车辆的次数和达到目的地目标的次数。下面,我们将讨论实验中三种竞争算法的计算指标的所得值,如表1所示。
表1. 实验I、实验II和实验III的结果
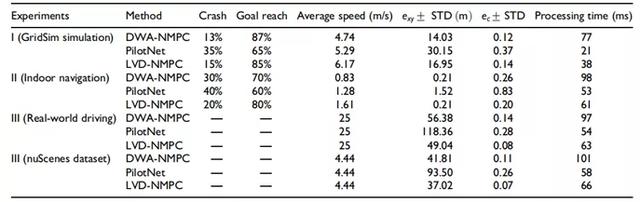
LVD-NMPC:基于学习的视觉动力学、非线性模型预测控制;DWA-NMPC:动态窗口法、非线性模型预测控制;STD:标准差。
4.2 实验一:仿真算法比较
第一组实验是在GridSim中进行的超过10次目标导航试验的模拟。GridSim,由Trasnea[29]等人提出,是我们的自动驾驶模拟引擎,它使用运动学模型从模拟传感器生成合成的占用网格。它允许将多个驾驶场景轻松地表示和加载到模拟器中。模拟参数与格里戈雷斯库等人的神经轨迹状态轨迹规划方法相同[24]。
为了训练领航网和LDV-NMPC,目标导航任务运行超过10条驾驶路线,如下。一个轨迹数据库已经被映射到感官信息上,而自我交通工具是由一个人手动驱动的。这导致了超过200.000对数据样本。由于GridSim以占用网格的形式提供观测,因此原始输入数据由车辆和障碍物之间的距离组成,以2°的角度采样,而不考虑任何视觉观测。由于占用网格结构的简化观察,不考虑视觉数据,模拟实验集被用作简单的理智检查,以评估竞争的方法。
总的来说,根据表1第一行实验集I(GridSim模拟)的碰撞百分比(13%)、目标达到(87%)和位置(14.03m)和曲率(0.12)误差,分析性非学习DWA-NMPC方法在本实验中提供了最高的定量结果。这并不奇怪,因为车辆的完整状态和障碍物的精确位置是先验已知的。然而,指出GridSim模拟结果如果表1,LVD-NMPC相对接近类似的值计算指标(15%崩溃,85%的目标达到,平均速度6.17m/s,16.95m和0.14位置和曲率误差,分别以及38ms计算时间),甚至优于其他方法的车辆速度。在接下来的实验中,PilotNet提供了最快的处理时间,主要是因为PilotNet的成本效益最高的组件是输入数据在其神经网络上的前向传播。DaGGer效应可以避免的,因为模拟环境允许我们收集尽可能多的训练数据。
4.3 实验二:室内算法比较
在这个实验中,我们使用图4(a)中的1:8比例的奥迪车型对不同的室内导航任务进行了测试。汽车必须遵循的参考路线被定义为直线、正弦曲线、圆形和一个75米的预先录制的循环。第一组10次试验在参考路线上没有任何障碍,而第二组10次试验包含静态和动态障碍。静态障碍物由纸板箱组成,模型车可以避开它,而动态障碍物则由另外两辆模型车表示,它们以不同的速度和不同的轨迹手动驾驶。车辆的状态是使用车轮测程仪和惯性测量单元进行测量。
除处理时间外,LVD-NMPC的定量结果最高,对PilotNet更好。DWA-NMPC计算时间增加的主要原因是环境感知和定位的不确定性。这是解耦处理管道中遇到的常见现象,感知精度的下降会导致控制性能的下降,反之亦然。但LVD-NMPC的情况并非如此,因为通过我们的视觉动力学模型,感知与运动控制紧密耦合。我们的算法基于模型的特性允许我们执行优于无模型的方法,如PilotNet,该方法在其控制输出中往往会产生抖动效应。
快照的控制循环LVD-NMPC如图5所示,所需的轨迹(用绿色表示)计算使用提出的输出DNN从图3和一组候选轨迹(如蓝色所示)计算使用车辆的动态模型从方程(4)。我们已经观察到,LVD-NMPC的优势依赖于汽车的解析动力学模型的组合,该模型随后通过深度网络的估计来适应看不见的情况,如状态估计方程(2)所述。
图6显示了10m试验距离下的速度、转向、位置误差和航向误差,在参考路线上的(0m;5m)位置有一个障碍物。障碍物的位置是相对于起始位置的。可以观察到,LVD-NMPC具有更平滑的轨迹,比竞争方法更早地开始适应控制输入。DWA-NMPC和PilotNet更激进,在两个控制输出中都会遇到抖动效应。这种不确定性分别与DWA-NMPC和PilotNet情况下的感知系统的准确性和缺乏系统模型有关。
为了评估这些方法对DaGGer效应的行为,我们已经放置了参考路线障碍,在训练时没有提供。嵌入在LVD-NMPC和试点网中的DNNs成功地绕过了这些障碍,利用了训练数据中出现的环境地标。这表明,尽管基于学习的方法能够正确地调整车辆的运动轨迹,但它们仍然需要足够的训练数据来识别环境地标。
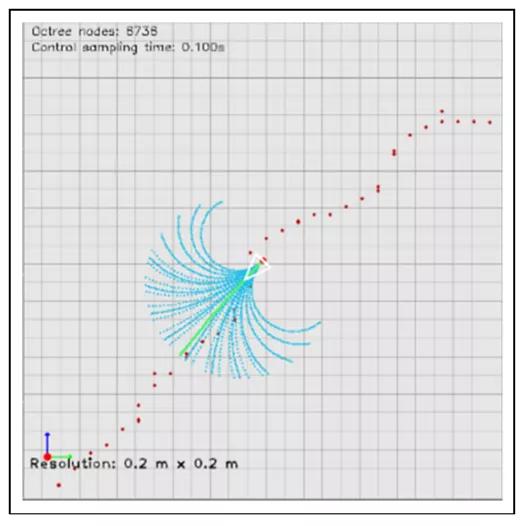
图5.使用LVD-NMPC估计所需的轨迹。车辆从可能的候选对象(蓝色)(最佳颜色观看)中选择最佳轨迹(绿色)。LVD-NMPC:基于学习的视觉动力学非线性模型预测控制。
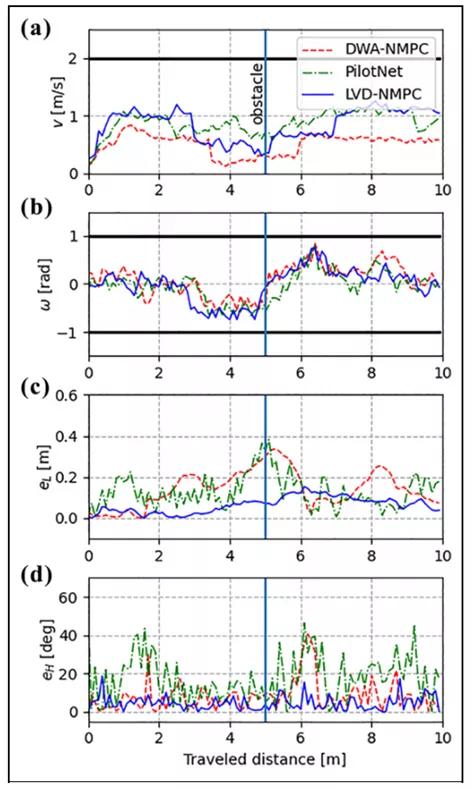
图6.(a-d)速度、转向、位置误差和航向误差相对于使用图4(a).中的模型汽车的10米行驶距离LVD-NMPC提供了一个更平滑的车辆轨迹,在学习视觉动力学模型时,它利用了学习到的障碍和环境地标。致动器的约束条件用黑线表示。LVD-NMPC:基于学习的视觉动力学非线性模型预测控制。
4.4 实验三:道路上的算法比较
最后,第三个实验测试了LVD-NMPC在不同环境下超过100公里的真实驾驶环境。总共获得了大约463.000个样本,并分为75%的训练集和25%的测试集。这些数据被用于以自我监督的方式训练图3中的深度网络,其中成对观察(图像)和标签(驱动轨迹)作为方程(16)中优化函数的输入。虽然训练以自我监督的方式进行,但相同的真实世界数据可以用于训练仅基于使用逆DRL的观察的DNN。这种方法是由伍尔夫迈尔[9]等人提出的,其中使用逆DRL学习了移动导航的成本函数。然而,使用DRL进行自动驾驶最直接的方法是在模拟环境中学习网络的参数,在那里汽车将自动探索其驾驶环境。在这样的系统中,奖励函数会根据视觉输入来改变汽车的位置和方向。最终,在这种情况下,挑战将是将训练过的DNN映射到现实世界的车辆。
除了我们自己的真实驾驶数据外,我们还评估了在nuScenes数据集(https://www.nuscenes.org/)上的竞争方法。在不同的基准数据集中,我们选择了由于其传感器设置和测程信息。数据收集包含超过15小时的驾驶数据,分为在波士顿和新加坡收集的1000个驾驶场景,每个场景的长度为20秒。覆盖面积约为242公里,平均速度为16km/h。我们已经将自我载体姿态转换为我们的全球二维参考路径坐标。原来的1600px×900px分辨率已经降到640px×360px。
我们遇到了与实验II相似的结果,LVD-NMPC提供了更准确的控制输出估计。由于测试车辆是一辆真实尺寸的汽车(相对于1:8的奥迪车型),性感度的价值大于实验II。另一方面,曲率误差更低,因为驾驶本身包含的曲线比室内导航实验更少。在nuScene数据集上的结果稍好一些,主要是由于在数据采集过程中车辆的速度相对较低。
如表1所示的真实实验I和II的结果所示,我们的模型在嵌入式NVIDIAAGXXavier开发板上提供了略高于60ms的推理时间,配备了集成的VoltaGPU处理器,具有512CUDA核。根据车辆的速度,如果车辆以相对较低的速度行驶,这个推断时间就足够了。然而,高速车辆需要增加计算时间,因为环境也会随着速度的提高而变化。
表1中使用的度量可以聚合在一个度量中,其中每个元素,即崩溃和目标达到的百分比、平均速度、位置和曲率误差和处理时间,将合并在单个加权函数中。然而,在这种情况下,单个测量值的内在值将会丢失。例如,由于高处理时间而产生最优度量值的模型可能比模型更容易崩溃,这在计算时间方面更慢。
5 结论
本文介绍了用于控制自动驾驶汽车的LVD-NMPC方法。该方法使用DNN作为视觉动力学模型,它估计车辆的期望状态轨迹,作为约束非线性模型预测控制器的输入,以及上述控制器的加权增益。LVD-NMPC的优点之一是q-学习训练是自监督的,而不需要手动标注训练数据。实验结果表明,该方法对最先进的竞争算法的鲁棒性,无论是经典的还是基于学习的。
作为未来的工作,我们计划研究LVD-NMPC的稳定性,特别是与汽车级部署所需的功能安全要求有关。我们已经在一个嵌入式设备上实现,即NVIDIAAGXXavier,我们相信该控制器可以用于现实世界的汽车,只要满足安全要求。撇开安全不谈,它目前的实现直接与车辆计算机的计算能力有关。它的深度学习加速器速度越快,LVD-NMPC能够应对的情况就越动态。