无需额外数据,首次实现ImageNet 87.1% 精度,颜水成团队开源VOLO
机器之心发布
Sea AI Lab (SAIL) 团队
VOLO 是第一个在 ImageNet 上无需额外数据达到 87.1% top-1 准确率的模型,进一步拉近了视觉 Transformer 与最顶级 CNN 模型的性能距离。
近十年来,计算机视觉识别任务一直由卷积神经网络 (CNN) 主导。尽管最近流行的视觉 Transformer 在基于 self-attention 的模型中显示出巨大的潜力,但是在没有提供额外数据的情况下,比如在 ImageNet 上的分类任务,它们的性能仍然不如最新的 SOTA CNNs。目前,在无额外数据集时,ImageNet 上的最高性能依旧是由 Google DeepMind 提出的 NFNet (Normalizer-Free Network)所获得。

ImageNet 分类性能实时排行榜(无额外数据集),来源 https://paperswithcode.com/

Cityscapes validation 实时排行榜,来源 https://paperswithcode.com/
在一篇最近发表的论文中,来自新加坡 Sea 集团旗下、颜水成教授领导的 Sea AI Lab (SAIL) 团队提出了一种新的深度学习网络模型结构——Vision Outlooker (VOLO),用于高性能视觉识别任务。它是一个简单且通用的结构,在不使用任何额外数据的情况下,实现了在 ImageNet 上图像分类任务 87.1% 的精度目标;同时,实现了在分割数据集 CityScapes Validation 上 84.3% 的性能,创下 ImageNet-1K 分类任务和 CityScapes 分割任务的两项新纪录。

VOLO 模型与 SOTA CNN 模型(NFNet)和 Transformer 模型(CaiT)的 ImageNet top-1 准确率比较。在使用更少参数的情况下,VOLO-D5 优于 CaiT-M48 和 NFNet-F6,并首次在不使用额外训练数据时达到了 87% 以上的 top-1 准确率。
颜水成教授认为,以 Transformer 为代表,「Graph Representation + Attentive Propagation」以其灵活性和普适性已展现出成为各领域统一框架的潜能,VOLO 算法表明了在视觉领域 Attention 机制也可以超越 CNN, 佐证了各领域走向模型统一的可行性。

- 论文地址:https://arxiv.org/pdf/2106.13112.pdf
- GitHub 地址:https://github.com/sail-sg/volo
方法概述
这项工作旨在缩小性能差距,并证明在无额外数据的情况下,基于注意力的模型优于 CNN。
具体来说,作者发现限制 self-attention 模型在图像分类中的性能的主要因素是在将精细级特征编码到 token 表征中的效率低下。
为了解决这个问题,作者提出了一种新颖的 outlook attention,并提出了一个简单而通用的架构——Vision OutLOoker (VOLO)。
与专注于粗略全局依赖建模的 self-attention 不同,outlook attention 旨在将更精细的特征和上下文有效地编码为 token,这些 token 对识别性能至关重要,但在很大程度上被自注意力所忽略。
Outlooker
VOLO 框架分为两个阶段,或者说由两个大的 block 构成:
- 第一个阶段由多层 outlooker 构成,旨在用于生成精细级别的数据表征;
- 第二个阶段部署一系列 transformer 层来聚合全局信息。在每个阶段的开始,使用 patch 嵌入模块将输入映射到相应大小的数据表示。
第一个 stage 由多层 outlooker 构成,outlooker 是本文提出的特殊的 attention 层,每一层 outlooker 由一层 outlook attention 层和 MLP 构成,如下所示为一层 outlooker 的实现方式。

其中,核心操作为 Outlook attention,如下图所示:

具体来说,outlook attention 的操作如下所示:

总体而言,outlook attention 具有如下优点:
- 较低的复杂度:相对于普通 self-attention 的时间复杂度是 O(H^2xW^2),而 outlook attention 只有 O(HW x k2 x k2)=O(HW x k4),而窗口大小 k 一般只有 3 或者 5,远小于图片尺寸 H 和 W。因此可用于具有更高分辨率的特征图(例如,28x28 标记),这是提高 ViT 的有效方法;
- 更好建模局部细节:适用于下游视觉应用,如语义分割;
- Key and Query free: outlook attention 中无 Key 和 Query,attention map 可以直接由线性生成,去掉 MatMul(Query, Key),节省计算量;
- 灵活性:可以很容易地构成一个带有 self-attention 的混合网络。
作者也提供了 Outlook attention 实现的伪代码,如下图所示:

基于提出的 Outlooker 和传统的 Transformer, 该工作提出了 VOLO 架构,同时包含五个大小变体,从小到大依次为 VOLO-D1 到 D5,架构示意如下图所示:

实验
研究者在 ImageNet 数据集上对 VOLO 进行了评估,在训练阶段没有使用任何额外训练数据,并将带有 Token Labeling 的 LV-ViT-S 模型作为基线。他们在配有 8 块英伟达 V100 或 A100 GPU 的单个节点机上训练除 VOLO-D5 之外所有的 VOLO 模型,VOLO-D5 需要在双节点机上训练。
V0LO-D1 到 VOLO-D5 模型的设置如下表 3 所示:

主要结果
下表 4 中,研究者将 VOLO 模型与 SOTA 模型进行了比较,所有的结果都基于纯(pure)ImageNet-1k 数据集,没有使用额外训练数据。结果表明,VOLO 模型优于 CNN、Transformer 等以往 SOTA 模型。
具体来说,该工作在图像分类和分割中验证了所提方法有效性,下图为 VOLO 在 ImageNet 上的实验结果,可以看出,仅凭 27M 参数,VOLO-D1 就可以实现 85.2% 的准确率,远超以往所有模型。同时 VOLO-D5 实现了 87.1% 的准确率,这也是当前在无额外数据集下 ImageNet 最好结果,比以往 SOTA 模型 NFNet-F6 有 0.5% 以上的提升。

Outlooker 的性能
研究者展示了 Outlooker 在 VOLO 模型中的重要性,他们将最近的 SOTA 视觉 transformer 模型 LV-ViT-S 作为基线。LV-ViT-S 及 VOLO-D1 模型的实验设置和相应结果如下表 5 所示:

研究者还对 Outlooker 与局部自注意力(local self-attention)和空间卷积进行了比较,结果如下表 6 所示。结果表明,在训练方法和架构相同的情况下,Outlooker 优于局部自注意力和空间卷积。

消融实验
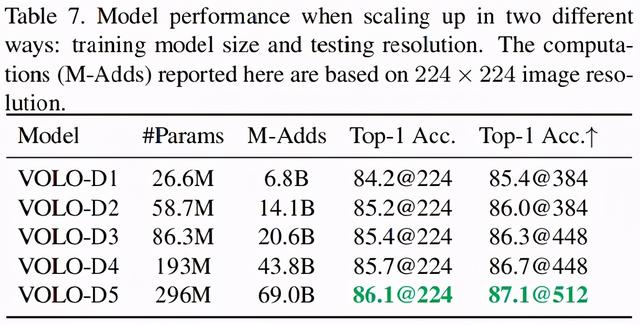
研究者将 VOLO-D1 模型扩展至 4 个不同的模型,即 VOLO-D2 到 VOLO-D5,具体的规格如上表 2 所示,相应的结果如下表 7 所示。结果表明,当增加训练模型大小和测试分辨率时,VOLO 模型都可以实现性能提升。
研究者还发现,VOLO 模型中 Outlooker 的数量对分类性能产生影响。下表 8 中,研究者在展示了不同数量的 Outlooker 在 VOLO 模型中的影响。
结果表明,在不使用 Outlooker 时,具有 16 个 transformer 的基线模型取得了 83.3% 的准确率。增加 Outlooker 的数量可以提升准确率,但使用 4 个 Outlooker 时即达到了性能饱和,之后增加再多的数量也无法带来任何性能增益。

下游语义分割任务上的性能
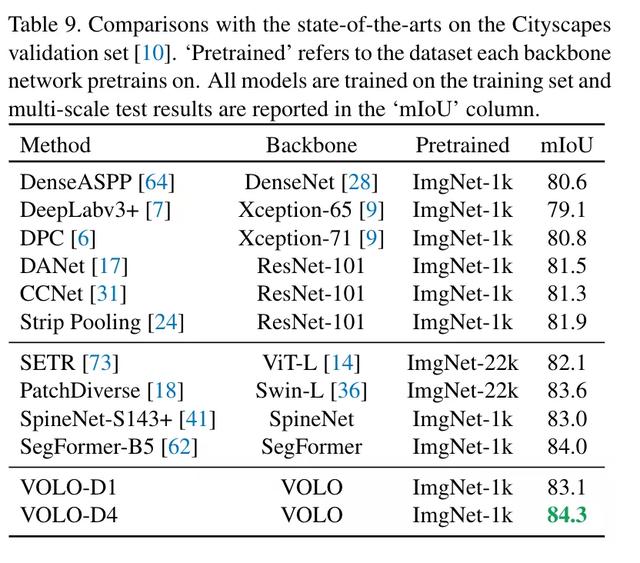
同时,该框架在下游任务上也取得了极大的提升,比如语义分割任务上,VOLO-d4 在 CityScapes 上实现 84.3 mIoU,在 ADE20k 上实现了 54.3 mIoU。

总体来说,实验表明 VOLO 在 ImageNet-1K 分类上达到了 87.1% 的 top-1 准确率,在无额外数据集的情况下,首次在 ImageNet 上超过 87% 准确率的模型。
同时将该框架用于下游任务,比如语义分割 (Semantic Segmentation) 上,在 Cityscapes 和 ADE20k 上也实现了非常高的性能表现,VOLO-D5 模型在 Cityscapes 上实现 84.3% mIoU,目前位居 Cityscapes validation 首位。
工作总结
这个工作提出了一个全新的视觉模型,并取得了 SOTA 的效果。首次在无额外数据集下,让 attention 主导的模型超越了 CNN 主导的模型精度。在证明了视觉 attention 的重要性的同时,为研究社区引入新的的模型框架和训练策略。
感兴趣的读者可以阅读英文原文,了解更多研究细节。