NeurIPS 2018亮点选读:深度推理学习中的图网络与关系表征
机器之心原创,作者:Angulia Chao,编辑:Haojin Yang、Hao Wang。
本文从深度推理学习中的图网络与关系表征入手介绍相关 NeurIPS 2018 论文。
1. 介绍(Introduction)
作者简介:Angulia Yang 毕业于新加坡国立大学,目前从事人工智能相关计算机视觉 (Computer Vision) 的研究与开发工作,主要工作方向集中为迁移学习与语义分割,近期对强化学习与生成模型进展也有持续关注。在工程师的角色之外,我也是机器之心的一枚业余分析师与撰稿人,对编程技术与计算机视觉前沿工作保持时刻关注,通过文字与大家分享我对前沿工作的剖析和新技术的理解,并从中收获启发与灵感。一直相信 AI 技术的产生与发展不是壁垒与掠夺,而是互助与分享,AI For The Greater Goods of Everyone。
Angulia Yang 机器之心个人主页:https://www.jiqizhixin.com/users/9cfaced6-c84b-45bf-bfc4-861e14f74742
今年的 NeurIPS 2018 话题感满满,改名风波不断,开发注册 11 分钟门票就被抢光,到历史最高纪录的 4856 份投稿,最终会议录取了 1011 篇论文,其中 Spotlight 168 篇 (3.5%),oral 论文 30 篇 (0.6%)详细数据统计可以参考我们以前的文章。
针对这一千多篇 NeurIPS 2018 的录取文章,目前会议官方仅仅只放出了它们的题目与摘要,所以本文作者爬取了所有的文章题目,并且利用词云(Word Cloud)进行了录取文章中关键词的提取和统计,得到了如下的词图:



图 0. NeurIPS 文章标题词图。
根据词图不难看出,深度学习与神经网络仍然是今年 NeurIPS 获选文章中的主旋律,强化学习(Reinforcement Learning),贝叶斯(Bayesian),生成模型(Generative Model)也较往年看仍持续了很高的关注度。然而除却传统热点,今年图(Graph)与表征学习(Representation)在接收文章中表现出很强势的上升势头和关注度,可以推想,深度网络在作为极强大的特征抽取工具的同时,在复杂的学习任务中,如何利用它进行高效的特征表示,以及如何有效地获取和利用上下文关联信息,这些方向获得了来自学界的更多关注和探索。本文侧重关注今年关键词中提升较为明显的图(Graph)与表征学习(Representation)应用在视觉任务上的相关工作。笔者分别从两个大的话题下挑选了几篇比较有特点的文章进行详细介绍(文章来源于作者提前发布在 arxiv 上的预印版,可能也会与之后的官方版本有小小的出入),此外有部分文章由于篇幅缘故或是在截稿之前还未在 arxiv 等网站放出预印版,但是本身也有不错的亮点,文章也进行了简要的总结和阅读建议。
作者注:文章篇幅有限,挑选的文章也有相对的作者个人偏好和研究兴趣侧重,所以非常抱歉没有能够涵盖自然语言处理、纯优化算法讨论、贝叶斯学习以及另外一些视觉方面的好文章,大家可以关注机器之心的 NeurIPS18 单篇文章分享。
2. 图网络(Graph Network)
论文:Out of the box reasoning with graph convolutional nets for factual visual question answering
论文链接:https://arxiv.org/abs/1811.00538
看图问答(Visual Question Answering,VQA)是根据给定的图像准确回答对应问题的一类综合任务,它同时要求算法有能力分析理解图像的内容,并且对提出的问题进行语义抽取、关键知识解析。较为常见的图像问答(Visual Question Answering)可以直接从图像内容获取到问题的答案无须推理过程,然而基于事实的图像问答(Fact-based Visual Question Answering, FVQA)需要根据问题中的文字表述结合,问题不再直接包含答案内容,而是在问题中提供一个事实(Fact)与相应的推理关系(Relation), 从而能够映射到答案本身的实体上,即相较于看图问答(VQA),事实图像问答(FVQA)多了一个推断(Reasoning)的过程。因此基于事实的图像问答任务不仅包含图像与相应问题及其答案的语料,还携带了一个数量巨大的知识库(Knowledge Database)里面包括了从各个来源提取到的事实(Fact),先前提出的方法即是基于深度学习在庞大的知识库中进行筛选,得到最终能够直接映射到问题答案的事实(Fact)实体,另一部分分支网络则对图像进行必要的分析和识别,最终匹配筛选好的事实和图像分析结果来得到问题的答案,两个学习过程通常来说也是异步的。然而 NeurIPS2018 这篇「out of the box reasoning with graph convolutional nets for factual visual question answering」工作提出了基于图卷积的网络试图同步学习事实上下文的推理过程与图像内容理解,之前深度网络筛选事实的这一训练过程用图卷积网络代替它成为一个端到端的推理系统,基于此思想,文章最终取得的准确度比之前的 State of the art 工作高出 7%。

图 1. FVQA 数据集格式以及问答结果。
基于事实的图像问答任务(FVQA)输入数据由成对的图像与其对应的问题,外加包含大量事实的知识库(Knowledge Base, KB),图像均为常见的 RGB 彩图,问题则是简单的短句问句,值得一提的是额外的事实(Fact)在知识库中以形如 f=(x,y,r) 的三元组来表示,x 指代图像中的实体信息,y 指代属性或者短语,r 则是关系介词(比如从属关系,是非关系,位置关系等)。
文章提出的方法由两大模块构成:事实追溯(Fact Retrieval)与答案预测(Answer Prediction)。
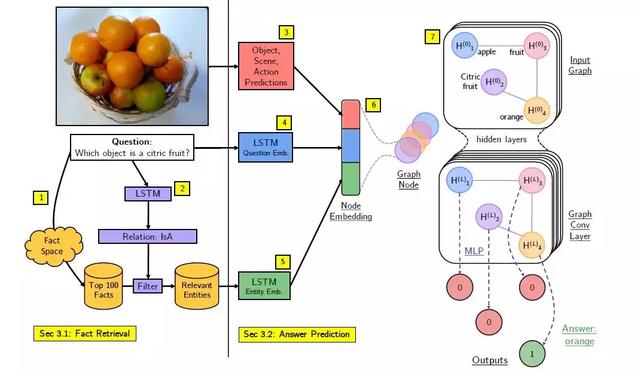
图 2. 网络结构图,左边为事实追溯模块,右边部分为答案预测。
在第一个模块中,首先得到处理后事实(Fact)、图像中的视觉概念(Visual Concept)与问题(Question)的 Glove 词嵌入(Glove Embeddings)信息,之后计算 Fact 与二者之间的余弦相关性(Cosine Similarity)并按照相关性对追溯到的 Fact 进行排序,同时取正相关的前一百条事实(Top-rank 100 Fact)作为一个初筛的小型知识库,之后根据 LSTM 处理后提取出来的问题中的关系(Relation in Question)作为 Ground-Truth 进一步提取过滤符合该关系下的 Facts,得到最终的相关实体集合 E(Relevant entities under certain relation),可表示为:
![]()
作者注:记得上一段提过一条事实(fact)是一个(x,y,r)的三元组合,由于关系 r 已经确定,剩下只是同样关系下的 x, y 元素组合。
至此第一模块类似于预处理和预筛选的功能全部完成。
进入第二个答案预测(Answer Prediction)的模块,将图像中的视觉概念(Visual Concept)与问题的 Glove 词嵌入表示(Glove Embeddings)以及相关事实的词嵌入表示作为三部分的特征进行连接形成完整的一条大特征实体 e(feature entity), e 则代表图卷积网络(Graph Convolution Network, GCN)中的一个节点(Node),由两个隐层的 GCN 与一层 MLP 形成的网络进行训练,网络采用随机梯度下降(SGD)与交叉熵损失(Cross-entropy Loss)进行最终的答案预测。

图 3. FVQA 实验结果,事实条目取 rank-100 时得到最高准确率。
综合看来这篇文章挑选的任务是非常有趣的,相较于以往的图像问答任务,FVQA 在问题的设计中添加了需要进行关系分析与推理(reason)的部分,在图像理解和自然语言处理方面是一个非常有意义的跨模态任务,而文章采用一种端到端(end-to-end)的形式把涉及到的数据输入做了一个特征拼接,同时用图卷积网络介入尝试完成推理过程,并在该任务上达到了 state of the art,这些都是不错的亮点。但是稍有不足之处在于采用图卷积网络所做的『推理』仍然是功能非常有限,更多只是在基于 LSTM 的特征提取上做了一个分类工作,并没有太看到利用图的联通特性进行更多有效的推理过程,以及在第一部分处理过程中也变相的进行了知识库中的事实筛选,且其中部分筛选器目前还是独立于整个系统之外的,无法实现真正意义上的端到端学习训练。
论文:GloMo: Unsupervisedly Learned Relational Graphs (推荐)
论文链接:https://arxiv.org/pdf/1806.05662.pdf
现今深度学习时代下的迁移学习(Transfer Learning)在自然语言处理(NLP)或是视觉任务(CV)中都发挥着非常显著的作用,如同之前有名的画风迁移(Style Transfer)应用就是迁移学习的一个直观应用。迁移学习的过程通常为:在较成熟的任务 A 中的网络里学到数据的特征表达,然后将特征用于学习新的任务 B,使得新任务的训练变得更为容易。
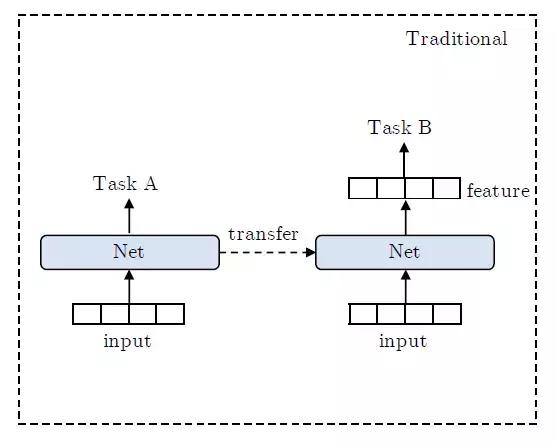
图 4. 传统迁移学习的特征迁移过程。
从整个过程中我们也不难体会到迁移学习涉及的关键就是如何从数据中抽取学习到通用性很强的特征,GLoMo: Unsupervisedly Learned Relational Graphs 这篇文章看到了图(Graph)在关系学习中的优势,提出了名为 GLoMo(Graphs from Low-level unit Modeling)的框架,意在学习成对的数据(Pair Data Units)之间潜在的依赖关系构成的图,这样的潜在关联图(Latent Relational Graph)意在从大量的无标签数据中学习到一个关联矩阵(Affinity Matrix),整体框架如下图所示,不同于之前传统迁移学习框架在不同任务之间进行特征的直接迁移使用,GLoMo 通过大量的无标签数据训练一个神经网络输出得到最终的一个关系图(Latent Graph),利用迁移过来的关系图与任务本身学到的特征相乘得到结构性加强的特征,从而对下半程的任务训练进行效果加强。这样的迁移学习机制不仅可以用图中的每个节点更好的表示数据的语义信息,同时也使学习到的特征具有结构感知的能力,将学习到各个节点的交互信息存在图中,最终 GLoMo 也在图像问答(Image Question Answering),自然语言推演(Natural Language Inference),情感分析(Sentiment Analysis),图像分类(Image Classification)等 NLP 与 CV 任务中均取得了不错的成绩,以证明 GLoMo 的图状结构化信息迁移框架应用在不同的任务上都是非常有帮助意义的。
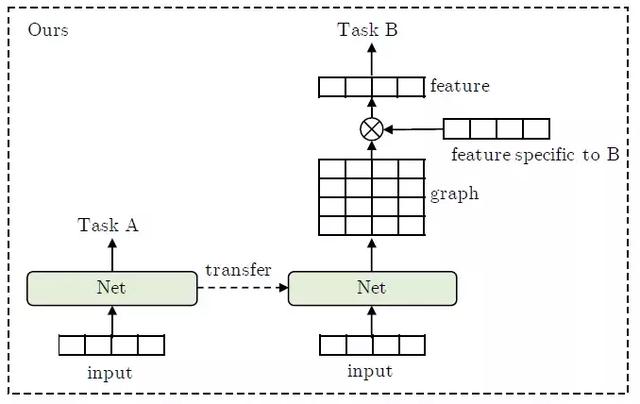
图 5. GLoMo 迁移学习过程, 特征利用图网络在主要学习的 TaskB 上进行了特征加强。
接下来我们具体看一看 GLoMo 的一个完整学习流程:
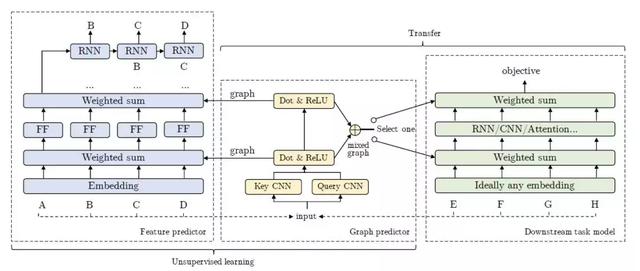
图 6. GLoMo 网络结构流程图。
GLoMo 整体由特征预测(Feature Predictor),图预测(Graph Predictor),下游任务模型(Downstream task model 可认为是整个学习任务的主要模型)三个部分组成,通过无监督学习与特征迁移两个阶段将它们串联起来。当处于无监督学习的阶段时,特征预测器与图预测器进行共同训练从而得到上下文信息的一个预测结果,同时 RNN 解码器应用于特征预测的所有位置得到输出,待到特征迁移阶段,图预测的权重进行冻结并且抽取出相应的图网络特征输出,作为权重与特征预测器产生的特征进行加权取和操作(weighted sum)为下游的主要任务模型服务。
GLoMo 在多个独立任务的数据集下都进行了关系图的迁移实验,最终结果都取得了一定的提升:

图 7. GLoMo 在多项 NLP 相关任务的 benchmark 上取得的结果。
GLoMo 这篇以无监督的方式学习数据中潜在的关联信息转换为图结构,并利用学到的特征对新训练任务进行特征加强,使得网络学习到更具通用性的特征。GLoMo 框架的设计有非常不错的创新且能够很好的泛化应用到不同的任务,且均取得了一定的性能提升,对于迁移学习的机制提出了新的思路,并且启发学习数据间的潜在关联来强化网络特征表示,是一篇非常值得一读的论文,目前工程代码以及训练方式都还没有公开,期待能有比较简洁的训练过程。另一方面,GLoMo 目前的实验主要还是集中于自然语言处理的相关任务,视觉任务涉及不多,但是在如同视频理解等较为综合的任务中,用图来学习局部特征之间的相关性,而不局限于单个像素对之间的相关性,然后较好的做特征迁移和利用,也同样是值得思考和尝试的方向。
论文:Symbolic graph reasoning meets convolutions (推荐)
本文目前只公开摘要
这篇论文在传统卷积神经网络(CNN)基础上提出了一个名为 SGR(Symbolic Graph Reasoning)的新网络层,尝试着利用外部的各种人类知识来赋予网络进行全局语义推理的能力。与之前如 CRF 等独立的图模型不同的地方在于 SGR 可以被插入到任意的卷积层之间并使用先验知识图(Prior Knowledge Graph)进行初始化,图中的节点分别表示先验知识图里每条语义信息的不同特性。SGR 由三个主要部分构成:1. 原始卷积特征投票产生语义图节点(Local-to-semantic)2. 传递信息并保持语义一致性的图推理模块 3. 从语义特征转换回加强后的卷积信息表示(Semantic-to-local),目前该文章至截稿前还未提前发布,根据文章的摘要提出 SGR 层加入后,对于传统 CNN 在三个语义分割任务以及一个图像分类任务在性能上都有了显著的提升,将图形结构化表达灵活加入网络与对图像分割任务特征表达的加强,都是 SGR 这篇工作非常值得关注的闪光点与创新。
论文:Graph Oracle Models, Lower Bounds, and Gaps for Parallel Stochastic Optimization
论文链接:https://arxiv.org/pdf/1805.10222.pdf
这篇文章着眼于利用并发性在随机优化与算法学习中的作用,提出一个普适性的先知框架(Oracle based framework),通过一个依赖关联图(Dependency graph)捕捉不同的随机优化设置信息,并且由此图推导出通用的算法下界(Lower bounds),文章着眼于找到通用的随机算法的优化并探究在多重平行的算法优化设置条件下,算法模型的更新延迟以及通信过程的并发处理,现今的多数深度模型优化过程都是基于随机优化的算法占主导(如随机梯度下降),所以文章的对此类优化算法的探索是比较有意义的,但文章相对较抽象,阅读有较高的数学门槛,适合专注于算法优化的相关学者。
论文:M-Walk: Learning to Walk in Graph with Monte Carlo Tree Search
论文链接:https://arxiv.org/pdf/1802.04394.pdf
根据已知查询命令作为原始节点,在庞大的图里搜素寻找目标节点的寻路算法,是一个非常重要的研究问题,也在如知识图库补全(Knowledge base completion,KBC)等任务上有不错的应用意义,通常这个问题可以被解构为基于强化学习(Reinforcement learning)的状态转换模型(State transition model),但是单纯强化模型在针对稀疏奖励的(Sparse reward)情况下效果并不太好,故 M-walk 结合循环神经网络(RNN)以及因为 alphago 名声大振,以搜索见长的蒙特卡洛树(MCTS),开发出在图中行走搜索的算法代理,尝试在稀疏奖励的环境下提升准确性的寻路方式。M-walk 通过 RNN 编码寻路状态并且将它分别映射为选路策略(Policy)和 Q-values,训练阶段,蒙特卡洛树协助神经网络策略产生寻找目标的路径,这种情况下产生的路径更容易找到反馈为正的目标奖励,实验结果表明 M-walk 比其他基于强化学习的方法学到更好的寻路策略,同时也在效果上超越了传统的知识图库补全任务(KBC)的 baseline。文章属于偏工程实践的工作,研究的问题有不错的应用价值, 此外文中创新式地利用蒙特卡洛树的加入辅助解决稀疏奖励的难点,都是文章的亮点。
3. 表征学习(Representation)
论文:Learning Plannable Representations with Causal InfoGAN (推荐)
论文链接:https://arxiv.org/pdf/1807.06358.pdf
GAN 近年来在图像、语音、甚至视频这样的高维度数据(High dimensional data)的学习方面都展示了非常强大的模拟能力和「想象力」,Causal infoGAN 则是针对动态系统设计的以目标为导向的可视化规划网络(Goal-directed visual plans)。它使用可视化的方式将动态系统由当前状态到理想目标状态的推理过程通过 GAN 学习进行表达,并将这个规划模型通用到离散或是连续型的状态,最终将生成的路径规划投射到一系列存在时序关系的视图进行表达和展示。
对于未来机器人,我们期待在非特定场景下完成一些常规任务时他们拥有对所处场景的基本推理能力并由此能自治地规划自己的行动,在人工智能的研究范畴内对这个问题的探索主要发展为两个分支:自动化规划与调度(Automated planning and scheduling)与强化学习(Reinforcement Learning)。自动规划调度很大程度上都依赖于人类本身的先验观察以及逻辑设计,但是对于难以界定的形变(比如绳子扭曲程度)和状态判定有着固有的缺陷,当前的大多数工作都是基于深度神经网络的强化学习,通过制定学习策略(Policy)试错以及合适的奖励函数(Reward function)设计,目前强化学习针对很多特定任务都已取得很好的效果,但也正因如此,许多强化学习方法对于特定任务所设计的奖励函数很难轻易的泛化和迁移到其他任务,目前提出的几个致力于构建多任务通用的强化学习方法很难做到样本高效性(Sample efficient,针对类似于图像这样的高维度输入设计奖励函数具有很强挑战性),提出的通用方法受限于只能解决相对简单的决策问题(Decision making problem),另一方面,当前通用的强化学习方法多是基于环境的深度模型学习和规划,学习过程经常分解细化到像素级别(Pixel level),这使得在强化学习过程中基于随机搜索(Random-based search)的行为选择非常有效,规划物体从初始状态直接到目标状态效果很好,即便如此,学习计算成本高昂而且从中学习到的表征(Representation)是非结构化的,无论是长时间段的推理(Long-term reasoning)或者是扩展更复杂的高级决策问题,深度强化模型都仍然存在不足。
基于如上考量,Causal infoGAN 尝试结合深度学习的动态模型和传统的状态规划,成为一个用于长时段推理规划并能在真实场景下也可以有效感知学习的方法。
Causal infoGAN 框架的整体结构如下图所示:
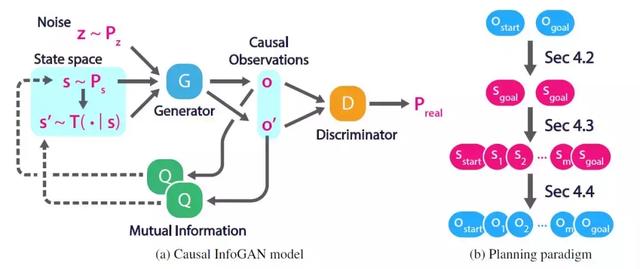
图 8. 左边 a 为 Causal InfoGAN 整个网络模型流程图,右边 b 为状态规划策略。
首先从先验概率分布 P 中抽取抽象状态 s, 根据 s 便可以使用转换模型 T 获取相对应的目标状态 s',成对的 s 与 s' 样本与一个随机噪音样本输入到生成器(Generator)得到对应的 Causal Observations 输出 o 同 o',而判别器(Discriminator)映射成对的 Causal Observations 到真实的概率分布。右图所示的规划范式则具体展示了框架进行 causal 推理的过程,将初始和目标的 Observations 先映射为抽象的状态,之后应用相应的规划算法(Planning algorithm)寻找和生成初始状态到目标状态间的中间路径过程,也即是规划过程,根据学习获得的规划模型,最终又反推得到一系列中间状态路径对应的 Observations。

图 9. Causal InfoGAN,InfoGAN,DCGAN 对绳结扭曲过程模拟的可视化过程,可以看到 Causal InfoGAN 对绳子弯曲过程的变化预测更合理。
Causal infoGAN 在绳子打结这个任务下,将得到的规划寻路 observations 以图片形式展示出来并且与 infoGAN,DCGAN 做了对比。三个网络都给出了自己从初始阶段到目标状态下规划的结果,可以明显看出 Causal infoGAN 展示的规划过程是绳子打结过程推演最符合逻辑的,证明 Causal infoGAN 确实具有合理规划长时段任务的能力,目前文章网上已经有 infoGAN 的 github 项目,causal infoGAN 项目的 github 已建立但仍为空,期待作者会在短期放出,现下验证算法的实验多集中于尝试性实验(toy experiments),我们可以期待该算法作为启发在后续能应用到真实场景下机器人多行为控制实验中,同时可以有机会在同等任务下与前沿的强化学习模型做一个更全面的横向对比,总的来说 Causal infoGAN 是一个比较简洁而且思路新颖的算法,对后续的机器人控制算法研究也具有不错的启发意义。
论文:Flexible Neural Representation for Physics Prediction (推荐)
- 论文链接:https://arxiv.org/abs/1806.08047
- 代码地址:https://neuroailab.github.io/physics/
这篇文章与其说是为了解决一个细分领域的问题,不如说是一种对学习解构场景的新型范式探索。文章提出一个名为层次化关系网络(Hierarchical Relation Network, HRN)的端到端(End-to-end)可微神经网络,HRN 试图将空间环境中的物体用层次化的卷积图进行表达(Representation),并在此种表达下学习去预测物体的动态物理变化。相比于其他的神经网络结构,HRN 能够准确地把握住物体在碰撞,非严重变形情况下的复杂变化,并预测较长时间段内物体可能产生的动态变化,这表明这样的表征结构和网络极有潜能成为新一代视觉任务,机器人或定量认知科学下的物体预测基石。

图 10. 将一个完整的物体用粒子团表示,之后再抽象为树状的结构化表示。
人类对于环境的感知能力向来都敏捷而强大,对于眼前场景人类能够在很短时间内将它们解构为不同的独立物体(Object),当场景中有物体发生碰撞或者形变等改变时,人眼也能在一段时间内敏锐地察觉到这一系列变化。然而神经网络面对同样的变化就没有如此的感知能力,所以文章提出为了使网络同样具备对物理变化的感知能力,将一个物体解构为更小的粒子(Particles)集合,同色的粒子作为一组,通过结构化的组合,最终形成图来表达物体中的层级关系,粒子群组间也添加关联限制,这样当物体产生变化的时候根据粒子间关联束缚的改变,整个物体的状态改变也能被预测感知。
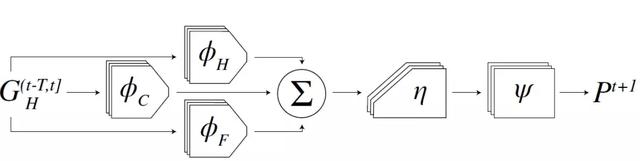
图 11. HRN 网络感知与反馈流程。
HRN 模型将状态变化前的粒子图(Particles graph)作为网络输入同时输出预测产生的下一个状态。从图中可以看到,结构化卷积图模块将粒子各部分产生的影响求和输入,粒子对的状态和彼此之间的关联也将这样的影响进一步传导下去,最终在网络出口计算出粒子的下一状态。
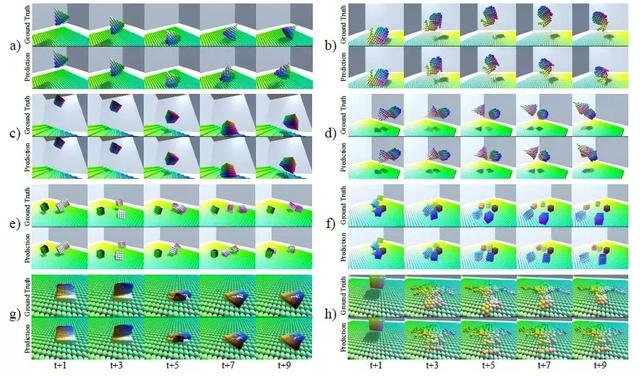
图 12. 图中 a-h 分别为不同情况下,HRN 对于物体在立体空间中碰撞或形变过程的状态预测与可视化模拟结果。
通过模拟物体在立体环境空间中碰撞或者形变后产生的状态改变,可以观察到 HRN 应用下,物体状态预测与 ground truth 的对比图。在一段连续时间之内,物体的形变和空间位置转变被很好的模拟预测了出来。文章证明了物体在图结构组织下的粒子表征,以及 HRN 应用后对场景物体变化的感知确实有帮助,并且为未来算法模型对环境感知的能力提升开了一个非常不错的头,目前文章代码也已陆续公开,在这篇文章的基础上,我们同样可以期待下一个面对真实场景的 HRN 能做到的感知实验。
论文:Beyond Grids: Learning Graph Representations for Visual Recognition (推荐)
本文目前只公开摘要
文章从视觉识别任务里提取 2d 特征图,之后从中提出学习型图(learning graph),将二维的平面图像转换为图结构从而形成了新形式的表征方法。文章提出的方法还可以通过图形结构将信息传播到所有的图节点下,并且能将学到的图表示映射回 2D 网格之中。文章的图表征在常规网格之上进行了推理可以捕捉图像子区域之间的长时段依赖关系,支持端到端的训练并且能够容易的整合到现存的网络模型中,文章在三个非常有挑战性的视觉任务:语义分割,目标检测与物体实例分割上都做了实验评估,最终文章陈述的方法实验结果均好于当前 state-of-art 结果。这篇文章目前截稿为止只放出了摘要部分,立意选取为前沿的视觉任务的图表征方式,工程性方面支持与当前网络整合且有端到端的训练方法,结果根据其表述更是在多个高级视觉任务当中取得了非常好的结果,综合其结果和方法描述可以说是本届会议非常值得期待的一篇工作。
论文:Learning Hierarchical Semantic Image Manipulation through Structured Representations
论文链接:https://arxiv.org/pdf/1808.07535.pdf
理解、推断以及操纵图像中的语义概念是一个长青的研究课题,这篇工作向我们展示了一个新颖的结构化语义图像操作(semantic image manipulation)框架,高光点在于这篇工作应用了一个结构化语义布局(structured semantic layout)作为框架进行操作的媒介表征(intermediate representation)。这样的框架优越性就在于能允许使用的用户可以在物体实例层次(object-level)上增加,移除或者变更 bounding box。实验评估结果也表明了此种表征方式下的图像操作框架无论在量级上还是最终效果上均优于现有的图像生成填充模型(image generation and context hole-filing models),同时该框架也证实了其在语义实例分割,交互图像编辑,数据驱动的图像操作等任务方面的益处与可用性,这篇文章提出的结构化语义布局是非常有趣的一个亮点,值得从事视觉相关研究任务的学者了解并阅读其内在的优点。
4. 生成模型与强化学习(Generative Model and Reinforcement Learning Related)
论文:IntroVAE: Introspective Variational Autoencoders for Photographic Image Synthesis (推荐)
论文链接:https://arxiv.org/pdf/1807.06358.pdf
本文是一篇较偏向应用的文章,不久之前的 PGGAN 生成高清人脸的文章(https://research.nvidia.com/sites/default/files/pubs/2017-10_Progressive-Growing-of/karras2018iclr-paper.pdf)发表后,变分自编码器(VAE)等细化和提升的文章也陆陆续续发表,今天的这篇文章提出了名为自纠正变分自编码器(IntroVAE)的方法,通过在训练过程中自我评估并做出纠正行为,从而生成高清人脸。IntroVAE 保留了 VAEs 系列模型训练稳定以及精致的流体表达等优点,同时它不需要额外的判别器,最终生成了类比下同等或者更加优质的高清人脸。
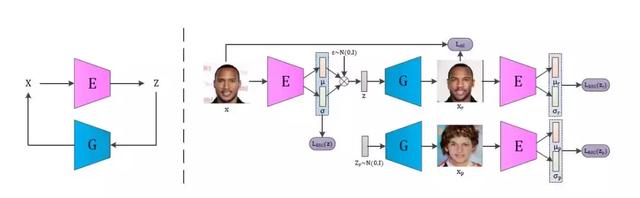
图 13. IntroVAE 网络流程结构图。
模型本身非常简洁,主要框架就是推理模型(Inference model E)与生成器(Generator G),在输入与特征编码之间形成一个闭环,从而达到 IntroVAE 想要实现的自评估的效果,训练流程也与普通生成网络大致无二。

图 14. IntroVAE 网络训练算法过程。

图 15. 图中 a 为人脸高清原图,b 为 PGGAN 生成的人脸,c、d 为 IntroVAE 网络的重构人脸以及人脸示例图片。
最终生成的高清人脸从视觉效果来看也与之前的工作相差无二,文章亮点有限,但是基于 IntroGAN 能够自我评估的机制,是否存在更加简单的训练方式以及更加轻量级的工作流程,期待能够在后续的工作中看到。
5. Other recommendation on the List
1. efficient loss based decoding on graphs for extreme classification
Image Generation and Translation with Disentangled Representations
论文链接:https://arxiv.org/pdf/1803.03319.pdf
2. Submodular Field Grammars: Representation, Inference, and Application to Image Parsing
论文链接:https://homes.cs.washington.edu/~pedrod/papers/nips18.pdf
3. Adaptive Sampling,Towards Fast Graph Representation Learning
论文链接:https://arxiv.org/pdf/1809.05343.pdf
4. Visual Reinforcement Learning with Imagined Goals
论文链接:https://arxiv.org/pdf/1807.04742.pdf
5. Graphical Generative Adversarial Networks
论文链接:https://arxiv.org/pdf/1804.03429.pdf



















评论