Arm开辟新战线背后|半导体行业观察
来源:内容由 公众号 半导体行业观察(ID:icbank)翻译自「nextplatform」,谢谢。
编者按:近来,全球最大的IP供应商Arm正在面向基础设施业务推出一个全新的产品线。在一个全新的领导人的领导下的全新出击,Arm这个决定背后的原因是什么?我们来看一下thenextplatform的这篇深入报道。

由于过去10年晶体管的微缩,数据中心服务器中和台式机中、笔记本电脑中的处理器架构之间的差距越来越大。三种截然不同的工作负载的需求意味着你不能只修剪服务器处理器以制作适合客户端的东西,也不能使用台式机或笔记本电脑芯片,加上一些额外的存储器和I/O把它变成服务器引擎。
这就是为什么Arm控股(Arm Holdings,软银的子公司,控制着主导智能手机的Arm处理器架构,并正试图将触角伸进数据中心)将其处理器产品线一分为二的主要原因。至少对我们来说,Arm似乎还想让服务器芯片合作伙伴更容易地组装出复杂而有竞争力的设计,而无需在独特的IP上投入数千万美元。
为什么Calxeda会破产?为什么Broadcom离开,高通或许紧随其后?为什么三星在公开谈论其服务器芯片的工作之前就放弃了?为什么AMD在其Epyc X 86服务器芯片问世时停止谈论它的Arm服务器业务?为什么Applied Micro的服务器芯片业务在一年多的时间内两次易手,现在从某种成都看,是改造成了Ampere?为什么Marvell的Cavium单元仍然是Arm服务器芯片的唯一选择?这些就是Arm持续大幅投资的原因。除非你把HiSilicon和Phytium计算在内,否则它们在中国势力范围之外没有希望。顺便说一句,我们确实包括了Mellanox Technologies(在收购EZchip之后出现)的Bluefield处理器。亚马逊仍然可以通过其Anapurna Labs自产的Arm芯片做一些有趣的事情,比如让别人购买。
每个在服务器处理器市场上寻求竞争的人都对Arm要花很长时间才能从英特尔的Xeons大山中夺取有意义的份额感到失望,Xeons这座大山被压倒性地选为世界上绝大多数工作负载的现代数据处理引擎。
有一段时间,Arm希望到2020年获得全球服务器出货量的20%,一年后的2021年在一片欢腾中将赌注提高到的25%(软银收购之前)。这些乐观的股价数据或许在一定程度上是基于这样的预期:IBM的Power8和Power9不会对英特尔Xeons造成太大威胁(或许这样描述不公平)。英特尔在Xeon性能改善速度放缓的情况下,也会像当初一样提高Xeon的价格,而AMD在把它的“Naples”Epyc处理器推向市场时存在问题——或是设计问题,或是晶圆厂合作伙伴问题,亦或两者兼而有之。
从总体上看,Naples似乎完成了让对话转移到Epyc、并让许多数据中心远离Arm的任务,这要归功于Epycs和Xeons的软件兼容性,以及Arm服务器芯片制造商所经历的艰难历程。CIO们最讨厌冒险。市场已经扩大,到今年年底,AMD可能有5%的份额,但仍然没有对英特尔造成任何伤害,因为没有人会因购买英特尔而被解雇。(至少现在还没有。他们以前也是这么说IBM的,记得吗?)而且看起来,Arm正在开发新的Neoverse系列基础架构芯片,其目的是要比之前几代Cortex A系列处理器(由服务器引擎改造而成)减少一点风险。
我们不得不从Arm高层本周在圣何塞召开的技术大会上发布的少量信息中推断出更多的信息。但Arm基础设施业务部门的高级副总裁兼总经理Drew Henry给了我们一些提示,并提出了Neoverse计划的框架。
不断变化的数据中心改变了处理
回到Unix工作站的全盛时期,以及它们作为服务器平台出现的时候,Henry是SGI视觉计算业务的总经理,在一些初创公司工作了一段时间之后,他在英伟达主管GeForce显卡业务长达11年。此后,Henry在SanDisk工作了三年,经营其客户平台Flash业务,向所有超级计算机和电信公司销售各种消费设备,然后去了一些神秘的初创公司工作,致力于并行计算和机器学习问题,直到2017年9月接受Arm的工作。去年11月,在Henry来到Arm几个月后,我们采访了他,Neoverse的发布是他在过去一年里所做的工作的顶峰,他一直在努力使Arm更好地与数据中心和边缘计算的未来保持一致。
像许多人一样,我们已经认识到,很多计算都是在边缘进行的,否则数据中心就可以胜任。这是有关处理数据的问题,这些数据的增长速度远远快于摩尔定律的发展速度,而与此同时,摩尔定律正在放缓,计算、网络和存储方面的容量和性价比的增长速度也在放缓。(近年来,一些巧妙的通信工程正在拯救网络,但100 GB/秒的信令通道似乎是未来的一个相当大的障碍。)数据将不得不在边缘进行处理,因为将数据转移回数据中心的成本太高,而且耗费时间太长。也许我们将生活在一个没有数据中心的世界里,但是这个世界里有一个数据和计算网格——也许是一个数据星系,有不断升级的统一和改进的数据,以及不同的计算、存储和网络能力来支持这一点。
在详细介绍Neoverse芯片计划和路线图之前,Henry做了一个总结,提醒我们Arm在今天的数据中心中占有非常大的份额,即使该架构在传统服务中的份额很小。
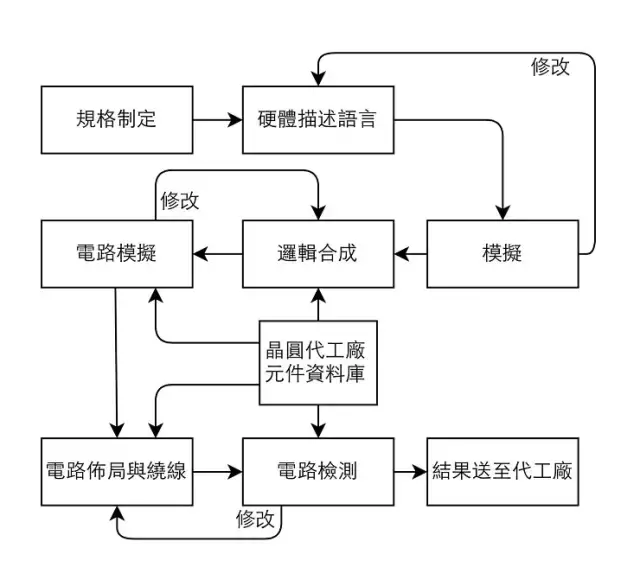
这意味着Arm集团向蜂窝基站、交换机、网关、广域网路由器和少量服务器销售的芯片份额将会增加,这一份额已经从7年前的约5%增长到2018年的近30%。
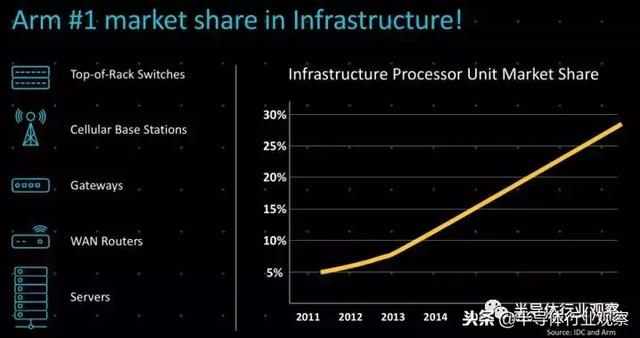
由于数据中心的存在和智能手机的绝对主导地位,Arm或许对数据中心和设备如何交互,以及这种交互是如何变化的有着最好的整体看法。Henry表示,云数据中心以各种形式创建和分发媒体内容的模式——目前传输的容量的75%是视频,尽管我们认为,与数十亿台个人电脑和智能手机相比,视频信息内容还不能与其他传统媒体(如文本和语音)相媲美。但很快,它就会成为一个数据中心的集合,这些数据中心与设备的边缘中心一起工作,在它们之间的网络中来回移动的数据会更多。就像这样:
这两个数据中心将会有三个数量级的增长——如果你把所有的边缘中心加起来,就会有数千万个这样的中心,这将连接到多出三个数量级的设备——几十万亿个这样的中心。这将是一个异常繁琐的世界,有很多机器学习推理和数据净化,以及对原始、瞬时和短暂数据的局部反应。这将是一个真正的互联网。
Henry解释说:“在处理的过程中有一种再分配。处理正在从核心转移到边缘,甚至进入设备本身,因为应用的延迟不能容忍。我们深入参与了这些不同系统的设计。”
新的转折
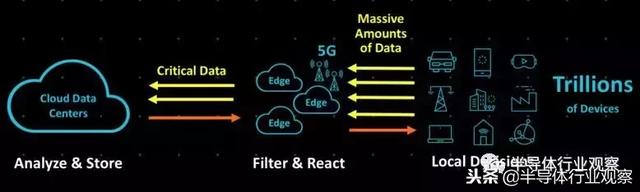
Neoverse系列芯片将采用目前的Cortex-A72和Cortex-A75设计,这些设计将通过增强功能进行改造,并使用台湾半导体制造公司目前的16nm和14nm工具和掩模,以及三星和GlobalFoundries的对应产品进行制造。Henry没有透露这些芯片,他将其称之为Cortex-A72和Cortex-A75的分支,虽然尚不知道如何区分,但我们很快就会看到。我们知道它们将被重新命名为“Cosmos”平台,并将在16nm工艺制造,如路线图所示:
明年,Arm将推出继承“Cosmos”的“Ares”产品,这是事情变得有趣的地方。如上图所示,Arm承诺一种架构,每一代将提供大约30%的性能增强,并且每年都会对设计进行调整,以保证性能的实现。到2021年,Arm推出的芯片设计如果能保持这样的速度,其性能将提高2.2倍。(Arm的意思是计算总吞吐量,而不是单线程性能,因为随着核心数量的增加,时钟速度会下降。)
Arm确实谈到了明年即将推出的Neoverse平台,该平台将面向繁重的数据中心任务,如网络功能虚拟化数据平面和服务器,以及具有少量内核的边缘设备,如下所示:

Neoverse意味着一个新的转折,也意味着在与英特尔的战争中开辟一个新的战线。Arm集团将承担台积电、三星,以及联华电子(台湾另一家在新加坡和中国大陆运营晶圆厂)的7nm工艺。Globalfoundries是AMD和IBM的晶圆厂组合,它之所以不在这份名单上,是因为该公司在去年8月加大了7nm的研发力度,并试图利用改进后的14nm技术,在其他类型的芯片上赚钱。
Neoverse计划要求服务器处理器最终扩展到128个核心。我们猜测,Arm将使用多芯片模块方法,利用Cortex-A72模块首先在芯片上获得48个内核,然后在2019年首先使用“Ares”将chiplet或芯片块放入8个内核,然后在2020年用“Zeus”实现每块12核,然后在2021年用“Poseidon”实现每块16核,并且迁移到5nm芯片蚀刻。数据平面应用中使用的变体最终有多达256个核心,这确实很有趣。
考虑到这一点,我们可以看到Arm核心架构类似于IBM的“Nimbus”和“Cumulus”Power9芯片变体,它具有IBM所谓的模块化执行片,每片提供两个线程。这使IBM能够制造一个12核芯片,每个核心有8个线程;或者制造一个24核芯片,每个核心有4个线程;如果愿意的话,它甚至可以制造一个48核芯片,每个核心有两个线程。所有这些芯片都具有本质上相同的晶体管,只需稍微修改一下芯片的组织方式。事实上,这可能就是相同的Neoverse Arm芯片如何在服务器配置中执行64个核心,在数据平面配置中执行128个核心。我们还假设Arm会咬紧牙关,将要求之外的内容添加到内核中,而到目前为止,这都是留给许可方去做的。
Neoverse的很多用于服务器的晶体管预算都用在了缓存上,在高端的L3和L2缓存中,缓存将达到128 MB。上图中引用的1 TB/秒是将芯片块链接在一起的8×8网格的带宽。这可以用于单片设计或chiplet 设计。这个数字不是衡量将所有内核、I/O和内存连接在一起的互连的标准。这应该远远超过1 TB/秒。在互连总线上的所有这些元素中,24核的Power9芯片为7 TB/秒。
目前尚不清楚Neoverse设计中8个内存通道的内存带宽是多少,但它可能大约为120 GB/秒,具体取决于支持DDR4的内存速度;DDR5内存会更高,如果Arm拥有缓冲的DDR5内存,则会更高。HBM变体的内存带宽可能相当高。 NEC的“Aurora”矢量处理器的6级HBM2内存可以达到1.2 TB /秒,因此8级可能高达1.4 TB /秒。
Neoverse服务器架构将支持本地100 GB/秒以太网、PCI-Express(大概是4.0版本,因为3.0的带宽只有原来的一半,现在已经有点老了)和CCIX端口(假设每个方向每个通道运行25 GB/秒,与Power 9上IBM的BlueLink端口和NVLink端口相同)用于紧密耦合非易失性内存和加速器。CCIX协议提供跨处理器和加速器的缓存一致性,也可以运行在PCI-Express 4.0之上,因此非常有用。
对于边缘计算应用,Neoverse架构将缩小成4个没有高速缓存的核心,1个带有20 Gb/秒带宽的DDR4内存通道,但将包括集成的10 Gb /秒以太网端口以及4G和5G蜂窝无线电。
我们假设在这两个极端之间会有变体,这也是我们假设Arm芯片制造许可方会做差异化的地方。
Henry公布了有关Neoverse架构如何在各种场景中使用的更精确的描述。下图是针对服务器的一个示例:
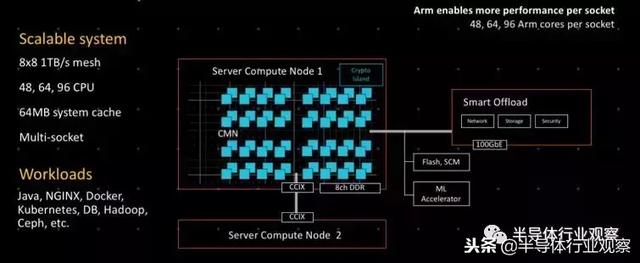
你可以看到在64 MB的片上缓存的情况下,核心数量将如何扩展图表中展示的几代Cosmos、Ares和Zeus,以及CCIX将如何用于紧耦合服务器。目前尚不清楚CCIX是否会被用来进行NUMA互连,但由于它是一个缓存一致性协议,并且运行速度为25 Gb/s,所以没有理由不能以这种方式使用CCIX,也没有理由不能从理论上使用CCIX来制造有2个、4个,甚至8个插口的机器(如果芯片有足够的CCIX端口,可以用相对较少的跳线进行拓扑的话)。在某种程度上,我们认为,DDR内存通道必须扩展到8个以上,而这可能发生在顶级的Poseidon设计上。
下图展示了如何对Neoverse进行调整,以支持网络、存储和安全加速器:

该架构将内核上的互连网格缩小为2×4和2×4网格,在16个核和24个核之间,大约有16 MB的片上缓存,有两个DDR内存通道和更少的以太网、PCI-Express和CCIX端口。
Neoverse边缘设置瞄准了这两者之间的差距:
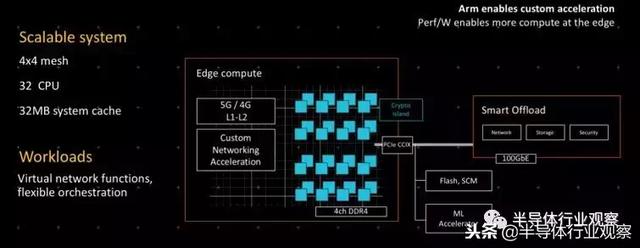
它基本上嵌入了带有4G和5G无线电的服务器处理器的一半,可以选择添加机器学习加速器和卸载引擎,用于网络、存储和PCI-Express或CCIX上的安全性。
顺便说一句,Neoverse架构有增加片上FPGA的空间,对于那些喜欢Xilinx并希望比CCIX提供更紧密耦合的客户而言,这可能是个好消息。(当然,Xilinx是CCIX的先锋。)
综上所述,部署Arm服务器芯片可能会容易得多,人们对长期的路线图更有信心,该路线图显示了持续的性能增长、多家晶圆厂合作伙伴,以及对稳步发展的坚定承诺。这就是Arm集团如何实现在服务器上分享25%份额的梦想,使之与它在其他数据中心设备中的现有份额相当。Neoverse给了Arm更好的机会。