DAC2019低功耗目标检测系统设计挑战赛:GPU、FPGA双冠军方案解读
机器之心发布
作者:张晓帆
2019 年 6 月 5 日,由电子自动化设计顶级会议 DAC 主办的第二届「低功耗目标检测系统设计挑战赛」于拉斯维加斯落下帷幕(机器之心曾于去年报道了第一届比赛)。本届比赛旨在为终端设备设计高精度且高能效的物体检测系统,共吸引了来自全球多个知名研究机构共 110 支队伍参加(其中 GPU 组 52 支,FPGA 组 58 支),竞争非常激烈。来自美国伊利诺伊大学(UIUC)的团队脱颖而出,包揽了 GPU 组和 FPGA 组双冠军。
本次比赛内容传承了上届精髓,包含极具挑战性的软硬件协同设计任务:参赛队伍需要设计高精度算法完成小物体检测、被遮蔽物体检测、相似目标区分等任务,也需要充分考虑算法被部署在目标平台后的检测速度及功耗等硬件因素。本次比赛由 Nvidia、Xilinx 和 DJI 赞助,参赛者可选择 Nvidia TX2 GPU 或 Xilinx Ultra96 FPGA 作为目标平台,使用 DJI 提供的由无人机采集的图片作训练数据。机器之心邀请了荣获双冠军的 UIUC 博士生张晓帆对比赛获奖设计作深度解读。
在本届比赛,UIUC 的 C3SR AI 研究中心联合了 IBM、Inspirit IoT, Inc(英睿物联网)和新加坡 ADSC 的研究人员组成两支队伍(iSmart3-SkyNet 和 iSmart3),共同参与了 GPU 组和 FPGA 组竞赛。在两个组别中,我们均采用了自主设计的 DNN 模型 SkyNet。得益于全新设计的精简网络结构,我们在两项赛事都获得了冠军。本次参赛人员包括了:
- iSmart3-SkyNet (GPU): Xiaofan Zhang*, Haoming Lu*, Jiachen Li, Cong Hao, Yuchen Fan, Yuhong Li, Sitao Huang, Bowen Cheng, Yunchao Wei, Thomas Huang, Jinjun Xiong, Honghui Shi, Wen-mei Hwu, and Deming Chen.
- iSmart3 (FPGA): Cong Hao*, Xiaofan Zhang*, Yuhong Li, Yao Chen, Xingheng Liu, Sitao Huang, Kyle Rupnow, Jinjun Xiong, Wen-mei Hwu, and Deming Chen.
(* equal contributors)

图 1: DAC 2019 大会正、副主席为 UIUC 团队颁发低功耗目标检测系统设计挑战赛冠军奖状(左起为大会主席 Robert Aitken、博后研究员郝聪、博士生张晓帆、 陈德铭教授、C3SR AI 研究中心主任熊瑾珺及胡文美教授和大会副主席李卓)
主流做法?还是另辟蹊径?
我们在研究去年比赛 GPU 及 FPGA 组前 3 名的获奖设计后发现,他们都采用了自顶向下的 DNN 设计思路(图 2):即首先选取符合任务需求的原始 DNN 模型(如经常出现在物体检测比赛中的 YOLO 和 SSD 网络模型),然后进行算法与硬件层面的优化,压缩 DNN 并让其部署在硬件资源稀缺的终端设备中。
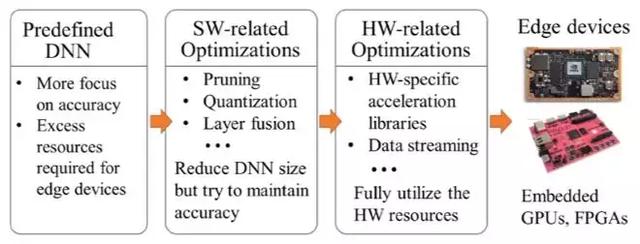
图 2: 被广泛采用的自顶向下 DNN 设计流程,可通过网络压缩及软硬件层面优化,把 DNN 部署至资源受限的终端设备
我们还总结了去年获奖设计所采用的原始 DNN 模型及优化方案(表 1)。所有 GPU 获奖队伍均选取 YOLO 作为其原始网络模型,而他们所获得的最终结果也非常接近(检测精度 IoU 接近 0.7,在 TX2 GPU 上的吞吐率约为 25 FPS)。而在 FPGA 方面,由于可用硬件资源更加稀缺,参赛队伍采用的压缩策略也更为激进,出现大量网络剪枝和超低比特量化方案(如 BNN),但在 IoU 和 FPS 这两种性能指标上仍不及同年的 GPU 设计。
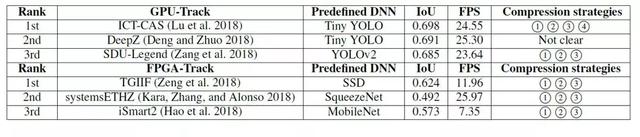
表 1: 2018 年低功耗目标检测系统设计挑战赛前 3 名设计方案分析。所有设计均采用自顶向下的 DNN 设计方法,选取已有网络(predefined DNN)进行模型压缩(Compression)以适应目标硬件平台。这些设计采用的方法有 1input resizing、2 网络剪枝、3 低精度数据量化和 4TensorRT。
我们尝试进一步提高检测精度与吞吐率,如在相同的 GPU 上突破 0.7 IoU 或大幅提高 FPS。鉴于 YOLO 已被多支队伍使用,我们选取了另一个热门的检测网络 SSD 作为原始网络,并分别使用 VGG16 和 MobileNet 为主干网络作物体检测。遗憾的是,这两个版本的 SSD 网络只能取得 0.70 和 0.66 的 IoU,而吞吐率在桌面型 GPU(1080Ti)上也仅能达到 15 和 24 FPS。要继续使用自顶向下的 DNN 设计方案,我们还需做大量网络压缩及优化工作,才有机会把设计部署在 TX2 GPU 或 Ultra96 FPGA 上。至此,我们发现在使用自顶向下的设计思路时,将无可避免地遇到两个困难,严重阻碍了在终端设备上部署高精度、高吞吐率的 DNN。这两个困难包括了:
- 不同的 DNN 压缩方案可提升 DNN 部署时的硬件性能,但提升性能的同时,容易引起极大的推理精度差异
- 根据已知任务,难以简单通过原始 DNN 确定推理精度范围
对于第一点,其根本原因是不同的 DNN 参数设置对推理精度和部署后的硬件性能有着不同的敏感度。我们在今年 ICML 的研讨会论文中提及的几个例子就反映了这个问题(见图 3)[1]。第一个例子如图 3 左图所示,我们对 AlexNet 的权值参数与特征图作量化压缩并画出了网络推理精度的下降趋势。在这个例子中,原有未压缩的网络均采用 32 比特浮点表示(Float32);而压缩后的网络将由 5 位数字标识(如 8-8218),对应着不同网络层所使用的量化比特位宽:第一位数字表示特征图使用的量化比特位宽,第二、三位数字表示首层卷积和剩余卷积层权值参数采用的量化位宽,而最后两位数字表示前两层全连接层和最后一层全连接层权值参数采用的量化位宽。尽管采用相近的网络压缩比,压缩特征图会比压缩权值参数带来更多的推理精度损失。第二个例子如图 3 右图所示:在 DNN 设计上引入了一个不影响推理精度的细微改变(如输入缩放因子从 0.9 修改至 0.88),就可节省大量硬件资源,从而能换来可观的硬件性能提升。上述例子都说明了 DNN 不同的参数设置对推理精度和部署后硬件性能有着不同的敏感度。要避免敏感度不同而带来的设计困难,我们在使用自顶向下的 DNN 设计方案时,就必须首先深入理解 DNN 的不同配置在软、硬件层面可能会造成的影响。
而第二点对使用自顶向下方案造成的困扰是:我们很难针对某一特定应用挑选出所谓「最合适」的原始 DNN,并由此推断 DNN 在压缩、优化并部署后的推理精度范围。想要找到合适的原始 DNN,网络设计者难免要做大量调研工作并在目标数据集上评估多种 DNN。并且,初期表现最好的原始 DNN 在经历多次压缩后,其推理精度也无法保证一定高于由其他 DNN 压缩而成的网络。
鉴于上述提及的困难,我们认为通过自顶向下设计的 DNN 在部署到相同硬件平台时,将难以大幅度领先去年的获奖模型。为此,我们决定另辟蹊径,探索全新的 DNN 设计方案。
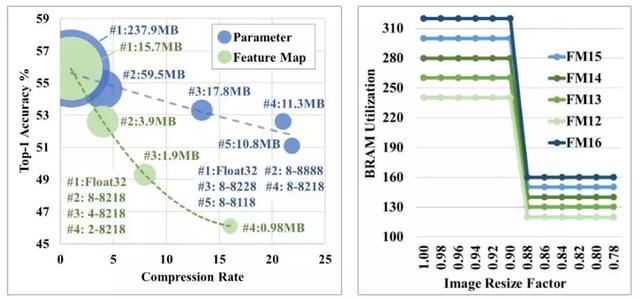
图 3: 左图:对 AlexNet 的权值参数(parameter)和特征图(feature map)作不同比特位宽量化时,相似的压缩比例会引起巨大的推理精度差异(压缩后的网络模型均在 ImageNet 上充分训练);右图:对指定 DNN 的特征图采用 12~16 比特位宽量化以及输入缩放时对应的片上存储器资源开销。在部署该 DNN 到 FPGA 时,把缩放因子从 0.90 降低至 0.88 就能大幅度节省硬件资源,但网络推理精度几乎不变 [1]。
新思路:自底相上的 DNN 设计方案
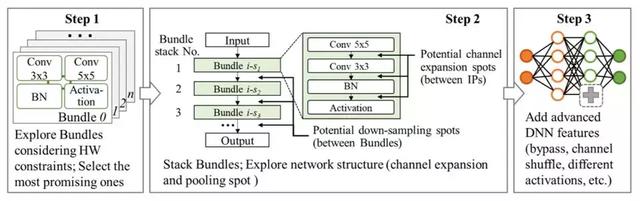
图 4: 我们提出了一种自底向上的 DNN 设计方案,并使用此方案设计了参赛模型 SkyNet。该方案不需要依赖任何原始 DNN,只需 3 步即可生成目标 DNN:1)选择 Bundle,2)搜索网络结构,3)手动增加网络特性。
我们最终采用的是一种自底向上的 DNN 设计方案,目的是生成一种能充分理解硬件资源限制且能被高效部署在终端设备的 DNN 模型(图 4)。此方法的第一步是生成并选出最合适的 DNN 基本搭建单元,「Bundle」。通过枚举 DNN 里常用模块(如不同的卷积层、池化层和激活函数),我们组合成多个拥有不同特性的 Bundle(如不同的计算延时、硬件资源开销和推理精度特性)。随后,我们依据已知的硬件资源开始评估每一个 Bundle 的硬件性能,筛选掉对硬件资源需求过高的 Bundle。为了获取 Bundle 在目标数据集的推理精度信息,我们分别堆叠每一款 Bundle,搭建其对应的简易 DNN 并在目标数据集上作短时间训练。这些 Bundle 中硬件性能达标且精度表现最好的会被选中,并被输出至下一步的网络结构搜索。
在自底向上设计方案的第二步,我们会进行网络结构搜索,以生成符合延时目标、资源消耗合理且推理精度高的 DNN。由于方案的第一步已经进行了部分的搜索任务(Bundle 筛选),第二步的搜索任务将不会过于复杂。为了进一步加速网络结构搜索过程,我们还收窄了生成网络的设计空间,只保留三个设计变量。它们分别是 Bundle 堆叠的层数、降采样次数及插入位置和通道数扩展因子。较小的设计空间有利于加快搜索算法的收敛并可以生成结构更加规整的 DNN。这种结构规整的 DNN 也更易于在硬件资源稀缺的终端设备上部署并高效运行。而在方案的最后一步,我们为生成的 DNN 加入额外特性以更好地适应目标任务。更详细的自底向上设计方案介绍及网络结构搜索算法介绍可参考论文 [2] 和 [3]。
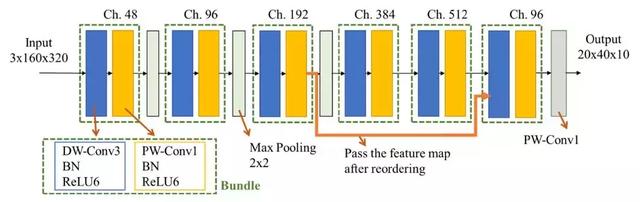
图 5: SkyNet 网络结构
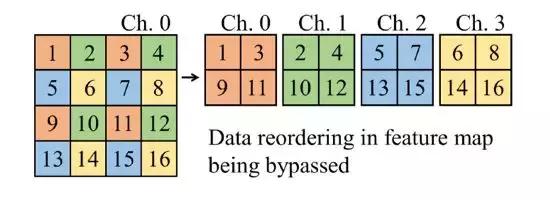
图 6: 特征图重排列方案
轻量化检测网络 SkyNet
依照自底向上的设计方案,我们设计出 SkyNet 作为参赛模型(图 5)。在设计过程中,被选中的 Bundle 包含了 DW-CONV3x3,CONV1x1,BN 和 ReLU6 这 4 个主要元素。在网络搜索算法堆叠 Bundle 并生成初始 DNN 后,我们对初始网络作了细微的修改,增加了一条用于传送特征图的旁路(bypass,图 5 的橙色连线)。设置旁路的原因在于,我们发现数据集里有 91% 的被测物与输入图片大小之比少于 9%,有 31% 的被测物与输入图片大小之比少于 1%(如图 7 例子)[2]。也就是说,这项比赛任务属于小物体检测任务。所以,我们添加了用于传送浅层特征图到深层卷积的旁路(把第三个 Bundle 的输出直接输入至最后一个 Bundle),减少小物体特征在经过池化层后丢失的机会。由于旁路跨越了池化层,旁路传输的特征图与原输入特征图尺寸并不相同。我们采用特征图重排列(reordering,图 6)去解决这个问题:重新排列经过旁路的特征图,减少其宽和高的同时增加其通道数,并混合不同通道的特征。对比使用池化层,重排列的优势是能在匹配旁路与原输入特征图尺寸的同时,不丢失特征数据。

图 7: 比赛需要检测的小物体实例
SkyNet 终端部署结果
在本次比赛中,我们的 GPU(iSmart3-SkyNet)和 FPGA(iSmart3)设计均使用 SkyNet 作为主干网络,并使用精简过的 YOLO 后端(移除物体分类输出,仅保留 2 个 anchors)作 Bounding box 回归计算。在数据类型的选择上,得益于精简的网络设计,我们在 GPU 的部署上无需再做优化并直接使用 32 比特浮点数据作网络推理。而在 FPGA 上,我们使用 9 比特和 11 比特的定点数据类型来表示特征图和网络权值参数。更多有关 FPGA 上部署的设计细节可参阅我们在 DAC 2019 上发表的论文 [3]。经组委会测试,我们设计的物体检测精度(IoU)为 0.731(GPU)和 0.716(FPGA),吞吐率为 67.33 FPS(GPU)和 25.05 FPS(FPGA)。
作为对比,我们归纳了最近两届比赛结果并在图 8 列出 GPU 及 FPGA 前三名获奖设计的推理精度与吞吐率。在使用相同硬件设备(TX2 GPU)的前提下,iSmart3-SkyNet 提交的设计相比其余 GPU 参赛队伍,有着大幅度吞吐率提升(比第二名提高 2.3 倍)。我们在精度及最终总得分上也超越其他对手。而在 FPGA 方面,由于本届比赛更换了硬件平台(从 Pynq-Z1 更换成资源更丰富的 Ultra96),获奖设计都比往届取得更好的推理精度和吞吐率。iSmart3 提交的 FPGA 设计在精度上大幅度超越 FPGA 组的第二名设计(提高了 10.5% IoU),在吞吐率方面也达到了实时处理要求。值得一提的是,我们的设计部署在 Ultra96 FPGA 时(峰值运算性能不及 TX2 GPU 四分之一),获得的精度和吞吐率依然非常接近本届 GPU 组亚冠与季军设计。更详细的对比可参阅表 2 和 3。
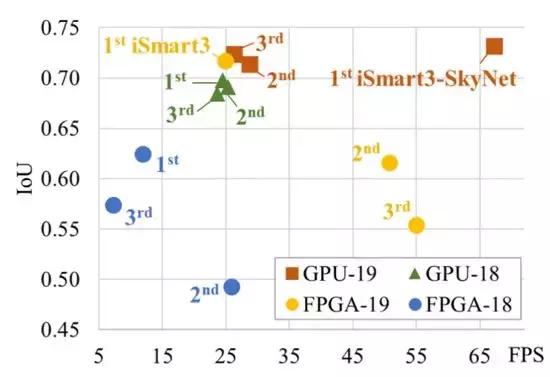
图 8: 近两年 DAC 低功耗目标检测系统设计挑战赛结果对比(IoU vs. FPS)
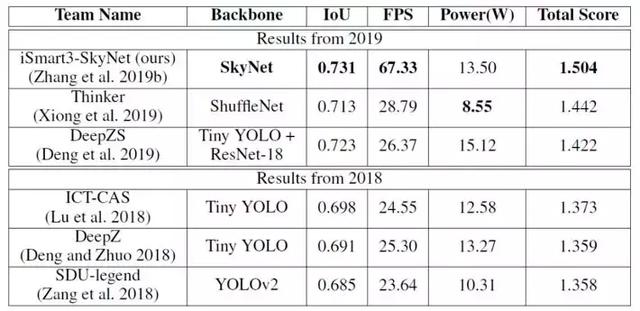
表 2: 近两届比赛 GPU 前三名设计及在 TX2 上部署性能对比
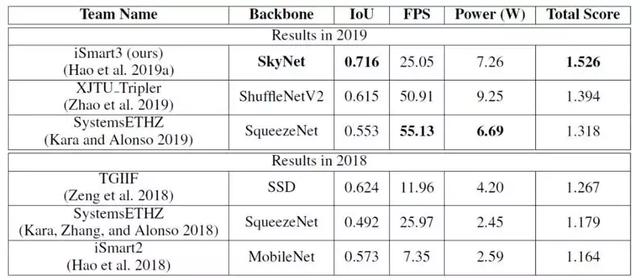
表 3: 近两届比赛 FPGA 前三名设计及在 Pynq-Z1 (2018 年) 和 Ultra96(2019 年)上部署性能对比
相关论文整理
为了参与本次比赛,我们先后准备了三篇论文,分别叙述了自底向上 DNN 设计方法的创作动机 [1],SkyNet 的设计思路 [2] 和用于终端设备的 FPGA/DNN 协同设计策略 [3]。其中,论文 [1] 获得了本年 ICML ODML-CDNNR 研讨会的最佳海报论文奖,论文 [3] 被电子设计自动化顶会 IEEE/ACM Design Automation Conference 全文收录并被机器之心报道 [4]。
[1] Xiaofan Zhang, Cong Hao, Yuhong Li, Yao Chen, Jinjun Xiong, Wen-mei Hwu, Deming Chen. A Bi-Directional Co-Design Approach to Enable Deep Learning on IoT Devices, ICML Workshop on ODML-CDNNR, Long Beach, CA, June 2019.
https://arxiv.org/abs/1905.08369
[2] Xiaofan Zhang, Yuhong Li, Cong Hao, Kyle Rupnow, Jinjun Xiong, Wen-mei Hwu, Deming Chen. SkyNet: A Champion Model for DAC-SDC on Low Power Object Detection, arXiv preprint: 1906.10327, June. 2019.
https://arxiv.org/abs/1906.10327
[3] Cong Hao*, Xiaofan Zhang*, Yuhong Li, Sitao Huang, Jinjun Xiong, Kyle Rupnow, Wen-mei Hwu, Deming Chen, FPGA/DNN Co-Design: An Efficient Design Methodology for IoT Intelligence on the Edge, IEEE/ACM Design Automation Conference (DAC), Las Vegas, NV, June 2019. (*equal contributors)
https://arxiv.org/abs/1904.04421
[4]《UIUC 联合 IBM、Inspirit IoT 推出最新 DNN/FPGA 协同设计方案,助力物联网终端设备 AI 应用》机器之心.
若需获取更多相关资料,可登陆作者个人主页:https://zhangxf218.wixsite.com/mysite





















评论