ACL 2019最佳论文公布!中科院、华为等拿下最佳长论文
郭一璞 安妮 边策 发自 凹非寺
量子位 出品 | 公众号 QbitAI
ACL 2019最佳论文新鲜出炉了。
刚刚,自然语言处理领域的顶会ACL 2019公布最佳论文,本次共颁布了4个奖项,共有8个获奖名额,分别是:
- 最佳长论文
- 最佳短论文
- 最佳DEMO论文
- 5篇杰出论文奖
今年,华人一作团队拿下了最佳长论文、最佳短论文和2篇杰出论文,中科院、中国科学院大学、腾讯、华为诺亚方舟实验室、南京理工大学、香港理工大学等榜上有名。
今年的ACL 2019空前热闹。据ACL官方发布的数据显示,今年共收到2906篇投稿,相比于去年的1544篇投稿量增加了75%以上。
来看看今年的最佳论文讲了什么,各个国家、机构的战况又如何:

最佳长论文
最佳长论文获奖者是中国的研究人员,这篇论文名为:
Bridging the Gap between Training and Inference for Neural Machine Translation

△ 图片来自推特用户Aarne Talman
文章来自中科院计算所智能信息处理重点实验室、中国科学院大学Wen Zhang和Yang Feng、腾讯微信AI的Fandong Meng、伍斯特理工学院的Di You和华为诺亚方舟实验室的Qun Liu。
这篇文章研究了应该如何弥合神经机器翻译(NMT)训练和推理之间的差距。
神经机器翻译(NMT)是根据上下文内容预测下一个词的一种方式,推理过程遵循从头开始、按顺序生成整个序列。这就导致由于上下文都未标注产生的累积误差。
此外还有一个挑战是,单词级训练要求生成的序列与ground truth序列严格匹配,这就造成对不同但合理的翻译进行过度校正。
在这篇文章中,研究人员提出了一种解决上述问题的方法,称为过矫正恢复(Overcorrection Recovery,OR)。
简单来说,在训练过程中,不仅从ground truth序列中抽取上下文单词,而且从模型预测的序列中抽取上下文单词,并选择句子级最优的预测序列。
也就是说,在翻译过程中,模型不需要再逐词对比标准来确定损失函数了。
具体来看:

这种方法先从预测单词中选择oracle单词,然后将oracle单词和ground truth单词作为上下文的样例。
同时,oracle单词不仅通过逐字贪婪搜索来选择,还会通过句子级评估(例如BLEU)。在训练开始时,模型以比较大的概率选择上下文真实词,随着模型逐渐收敛,oracle词语被更频繁地选择为上下文。
研究人员在中文->英文和WMT’14英文->德语翻译任务上进行了实验,结果表明,这种新方法可以在多个数据集上实现提升。
他们在RNNsearch模型和Transformer模型上也验证了新方法。结果表明,新方法可以显著提高两种模型的性能。

论文地址:
https://arxiv.org/abs/1906.02448
最佳短论文

△ 来自推特用户Saif M.Mohammad
最佳短论文的一作也是华人,俄亥俄州立大学博士生蒋南江,二作则是该校助理教授Marie-Catherine de Marneffe。

△ 蒋南江,来自她的GitHub自我介绍
这篇论文的标题叫做《你知道佛罗伦萨挤满了游客吗?评估最先进的说话者承诺模型》。在文章开头,研究者们借佛罗伦萨的游客解释了两个问题:
“你知道佛罗伦萨挤满了游客吗?”
这个时候,你可以回答:“知道啊,挺挤的。”
“你觉得佛罗伦萨挤满了游客吗?”
换了两个字,问题就变了,成了一个主观的问题,可以回答“嗯,我这么觉得。”或者“不啊我不这么觉得。”
这里,就牵扯到一个推断说话者承诺(Inferring speaker commitment)的问题,此前的研究里,也将它叫做事件事实(event factuality),搞明白这个问题,对信息提取和问题回答至关重要。
这里,研究者找到了CommitmentBank数据集,画风大概是这样的:

借助这个数据集,研究者们评估了两个目前最高水平的模型,发现它们在否定句和非有效嵌入动词上表现更好,而且语言信息模型优于基于LSTM的模型,能够更成功地扩展到具有挑战性的自然数据。
也就是说,需要语言知识来捕获这些具有挑战性的自然数据。
不过,问题来了,虽然模型在否定句上表现不错,但它们无法推广到自然语言中的各种语言结构,例如条件语句、模态和负增长。
因此,研究者得出了针对这类语言模型的改进方向:为了进行强有力的语言理解,模型需要包含更多的语言预知,并能够推广到更广泛的语言结构。
这也是这篇文章的核心贡献。
Do you know that Florence is packed with visitors?
Evaluating state-of-the-art models of speaker commitment
论文地址:
https://linguistics.osu.edu/people/jiang.1879
最佳Demo论文

△ 来自推特用户Aarne Talman
今年的最佳Demo论文授予了Unbabel团队,他们提出了一个基于Pytorch的开源框架OpenKiwi,用于评估神经机器翻译质量。
Unbabel是一家2013年成立的创业公司,向客户提供人工智能驱动的人工翻译平台,主要专注于客服交流的翻译。其客户包括Booking.com、Facebook等公司。
OpenKiwi支持单词级和句子级质量评估系统的训练和测试,在WMT 2015-18质量评估比赛中获胜。在WMT 2018(英语-德语SMT和NMT)的两个数据集上进行基准测试,OpenKiwi在单词级任务中达到了性能,在句子级任务中接近于最先进的性能。

OpenKiwi的特征有:
训练QE模型和使用预训练模型评估MT的框架;
支持单词和句子级质量评估;
在Pytorch中有5个QE系统的实现:QUETCH、NuQE、predictor-estimator、APE-QE以及一个线性系统的堆栈集合[ 2,3 ]。
易于使用的API,可将其作为包导入其他项目或从命令行运行;
提供脚本在WMT 2018数据上运行预训练QE模型。
通过yaml配置文件轻松跟踪和重现实验。
OpenKiwi: An Open Source Framework for Quality Estimation
论文地址:
https://arxiv.org/abs/1902.08646
代码地址:
https://github.com/Unbabel/OpenKiwi
5篇杰出论文
1、Emotion-Cause Pair Extraction: A New Task to Emotion Analysis in Texts
https://arxiv.org/abs/1906.01267
作者:Rui Xia, Zixiang Ding(南京理工大学)
2、A Simple Theoretical Model of Importance for Summarization
https://www.aclweb.org/anthology/P19-1101
作者:Maxime Peyrard(EPFL)
3、Transferable Multi-Domain State Generator for Task-Oriented Dialogue Systems
https://arxiv.org/abs/1905.08743
作者:Chien-Sheng Wu, Andrea Madotto, Ehsan Hosseini-Asl, Caiming Xiong, Richard Socher and Pascale Fung(香港科技大学、Salesforce等)
4、We need to talk about standard splits
https://wellformedness.com/papers/gorman-bedrick-2019.pdf
作者:Kyle Gorman and Steven Bedrick (纽约城市大学、俄勒冈健康与科学大学等)
5、Zero-Shot Entity Linking by Reading Entity Descriptions
https://arxiv.org/abs/1906.07348
作者:Lajanugen Logeswaran, Ming-Wei Chang, Kenton Lee, Kristina Toutanova, Jacob Devlin and Honglak Lee(密歇根大学、谷歌等)
中美投稿最热情
据ACL官方发布的数据显示,今年共有61个国家的机构提交了论文,其中,美国机构投稿量略高于中国大陆机构投稿数量,英国和德国投稿量分别位于第三和第四。

△ 图片来自ACL官方统计数据
ACL官方数据统计:
http://acl2019pcblog.fileli.unipi.it/?p=152
增长的除了投稿数量,还有接收数量。ACL 2019接收了765篇论文,接受率为25.8%,相较于前两年的24%左右略有上升。
其中,长论文接收了447篇,短论文接收213篇,34篇demo论文被接收,还有71篇student workshop。
接收论文列表:
http://www.acl2019.org/EN/program/papers.xhtml
最近几年ACL的投稿数量也是逐年上升,不过论文接受并没有放宽要求,接收率和前几年差不多。

△ 来自ACL 2019官网
在所有研究领域中,比较热门、投稿量有信息提取和文本挖掘、机器学习和机器翻译,投稿量都超过了200。
就接收率来说,最难的领域是文档分析和句子级语义,接收率不到五分之一。

△ 来自ACL 2019官网
而在所有国家中,投稿最积极的是在中国和美国的学者,各自投了超过800篇论文,但是考虑到许多中国AI领域的学者都是在美国读书,许多篇论文一作虽然是美国高校,但都是中国人,所以中国人对ACL的热情是最高的。
不过接收率上,中国的论文比美国的论文低将近10个点。排除那些投稿较少的国家,将投稿量超过30的国家列出来比一比,会发现接收率最高的前五名分别是新加坡(34.8%)、以色列(34.1%)、英国(29.7%)、美国(28.8%)和德国(28.7%)。

△ 来自ACL 2019官网
在这700多篇论文中,获得最佳论文提名的共有32篇,其中17篇长论文,11篇段论文,还有4篇demo论文。
被提名的论文中,24篇一作来自各大高校和研究所,7篇一作来自产业界,另外一篇来自邢波团队的论文则是署了CMU和邢波创建的公司Petuum两家单位,是产学研结合之作。
从各国来看,一作机构为美国的有14篇,中国6篇(其中一篇两位共同一作分属日本和中国的高校),英国3篇,瑞士和日本各两篇,加拿大、印度、比利时、巴西、韩国、俄罗斯各1篇。
被提名论文数量大于等于两篇的机构中,只有两家公司,一家是Google,有4篇论文都被提名,其中2篇一作;另一家则是华为诺亚方舟实验室,有2篇论文被提名,1篇是一作。

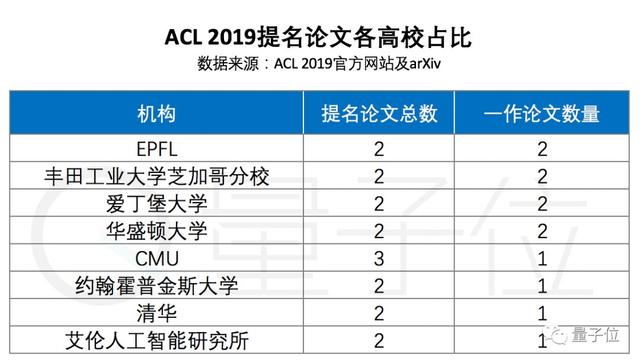
另外,在所有论文被提名的高校和研究机构中,洛桑联邦理工学院、华盛顿大学、爱丁堡大学、丰田工业大学芝加哥分校各有两篇一作论文被提名;CMU有3篇论文被提名,约翰霍普金斯大学、清华大学、艾伦人工智能研究所各有2篇论文被提名,每家也都有一作论文获得提名。
40%提名论文一作为华人
从论文作者角度分析,在这32篇提名论文中,13篇论文的第一作者是华人,占比40%。
这13篇华人一作的论文分别是:
1、Detecting Concealed Information in Text and Speech
作者:Shengli Hu(康奈尔大学)
https://www.aclweb.org/anthology/P19-1039
2、AMR Parsing as Sequence-to-Graph Transduction
作者:Sheng Zhang(约翰霍普金斯大学)等
https://arxiv.org/abs/1905.08704
3、Transferable Multi-Domain State Generator for Task-Oriented
作者:Chien-Sheng Wu(港科大), Andrea Madotto, Ehsan Hosseini-Asl等
https://arxiv.org/abs/1905.08743
4、A Modularized, Versatile, and Extensible Toolkit for Text Generation
作者:Zhiting Hu胡志挺(CMU), Haoran Shi, Bowen Tan等
https://www.aclweb.org/anthology/W18-2503
5、Emotion-Cause Pair Extraction: A New Task to Emotion Analysis in Texts
作者:Rui Xia(南京理工),Zixiang Ding
https://arxiv.org/abs/1906.01267
6、Visually Grounded Neural Syntax Acquisition
作者:Haoyue Shi(丰田工业大学芝加哥分校), Jiayuan Mao, Kevin Gimpel and Karen Livescu
https://arxiv.org/abs/1906.02890
7、An Imitation Learning Approach to Unsupervised Parsing
作者:Bowen Li(爱丁堡大学), Lili Mou, Frank Keller
https://arxiv.org/abs/1906.02276
8、Decomposable Neural Paraphrase Generation
作者:Zichao Li(华为诺亚方舟实验室), Xin Jiang, Lifeng Shang and Qun Liu
https://arxiv.org/abs/1906.09741
9、Robust Neural Machine Translation with Doubly Adversarial Inputs
作者:Yong Cheng(Google AI), Lu Jiang and Wolfgang Macherey
https://arxiv.org/abs/1906.02443
10、Bridging the Gap between Training and Inference for Neural Machine Translation
作者:Wen Zhang(中科院), Yang Feng, Fandong Meng, Di You and Qun Liu
https://arxiv.org/abs/1906.02448
11、Do you know that Florence is packed with visitors? Evaluating state-of-the-art models of speaker commitment
作者:Nanjiang Jiang(the ohio state uiversity)等
12、ConvLab: Multi-Domain End-to-End Dialog System Platform
作者:Sungjin Lee(微软研究院), Qi Zhu, Ryuichi Takanobu等
https://arxiv.org/abs/1904.08637
13、Persuasion for Good: Towards a Personalized Persuasive Dialogue System for Social Good
作者:Xuewei Wang(浙大), Weiyan Shi等
https://arxiv.org/abs/1906.06725
传送门
ACL提名论文名单:
http://www.acl2019.org/EN/nominations-for-acl-2019-best-paper-awards.xhtml
— 完 —
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。
量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态


















