NLP大火的prompt能用到其他领域吗?清华孙茂松组的 CPT 了解一下
机器之心报道
编辑:张倩
从 GPT-3 开始,一种新的范式开始引起大家的关注:prompt。这段时间,我们可以看到大量有关 prompt 的论文出现,但多数还是以 NLP 为主。那么,除了 NLP,prompt 还能用到其他领域吗?对此,清华大学计算机系副教授刘知远给出的答案是:当然可以。

图源:https://www.zhihu.com/question/487096135/answer/2143082483?utm

论文链接:https://arxiv.org/pdf/2109.11797.pdf
在细粒度图像区域,定位自然语言对于各种视觉语言任务至关重要,如机器人导航、视觉问答、视觉对话、视觉常识推理等。最近,预训练视觉语言模型(VL-PTM)在视觉定位任务上表现出了巨大的潜力。通常来讲,一般的跨模态表示首先以自监督的方式在大规模 image-caption 数据上进行预训练,然后进行微调以适应下游任务。VL-PTM 这种先预训练再微调的范式使得很多跨模态任务的 SOTA 被不断刷新。
但尽管如此,清华大学、新加坡国立大学的研究者还是注意到,VL-PTM 的预训练与微调的 objective form 之间存在显著差异。如下图 1 所示,在预训练期间,多数 VL-PTM 都是基于掩码语言建模目标进行优化,试图从跨模态上下文恢复 masked token。然而,在微调期间,下游任务通常通过将 unmasked token 表示归为语义标签来执行,这里通常会引入针对特定任务的参数。这种差异降低了 VL-PTM 对下游任务的适应能力。因此,激发 VL-PTM 在下游任务中的视觉定位能力需要大量标记数据。
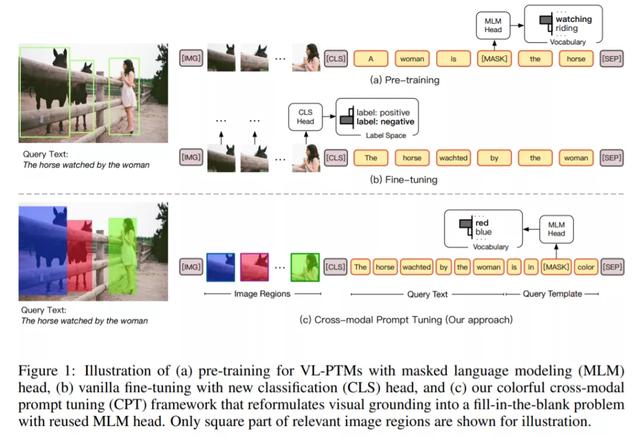
在这篇论文中,受到自然语言处理领域的预训练语言模型进展启发,研究者提出了一种调整 VL-PTM 的新范式——CPT( Cross-modal Prompt Tuning 或 Colorful Prompt Tuning)。其中的核心要点是:通过在图像和文字中添加基于色彩的共指标记(co-referential marker),视觉定位可以被重新表述成一个填空题,从而尽可能缩小预训练和微调之间的差异。
如图 1 所示,为了在图像数据中定位自然语言表达,CPT 由两部分构成:一是用色块对图像区域进行唯一标记的视觉 sub-prompt;二是将查询文本放入基于色彩的查询模板的一个文本 sub-prompt。针对目标图像区域的显式定位可以通过从查询模板中的 masked token 中恢复对应颜色文本来实现。
通过缩小预训练和微调之间的差距,本文提出的 prompt tuning 方法使得 VL-PTM 具备了强大的 few-shot 甚至 zero-shot 视觉定位能力。实验结果表明,prompted VL-PTMs 显著超越了它们的 fine-tuned 竞争对手。
本文的贡献主要体现在两个方面:
1. 提出了一种用于 VL-PTM 的跨模态 prompt tuning 新范式。研究者表示,据他们所知,这是 VL-PTM 跨模态 prompt tuning+ zero-shot、few-shot 视觉定位的首次尝试;
2. 进行了全面的实验,证明了所提方法的有效性。
CPT 框架细节
视觉定位的关键是建立图像区域和文本表达之间的联系。因此,一个优秀的跨模态 prompt tuning 框架应该充分利用图像和文本的共指标记,并尽可能缩小预训练和微调之间的差距。
为此,CPT 将视觉定位重新构建为一个填空问题。具体来说,CPT 框架由两部分构成:一是用色块对图像区域进行唯一标记的视觉 sub-prompt;二是将查询文本放入基于色彩的查询模板的一个文本 sub-prompt。有了 CPT,VL-PTM 可以直接通过用目标图像区域的彩色文本填充 masked token 来定位查询文本,目标图像区域的 objective form 与预训练相同。
视觉 sub-prompt
给定一个图像 I 以及它的区域候选 R = {v_1, v_2, . . . , v_n},视觉 sub-prompt 旨在用自然视觉标记对图像区域进行独特标记。有趣的是,研究者注意到,在文献中,彩色边界框被广泛用于对图像中的对象进行独特标记,以实现可视化。受此启发,研究者通过一组颜色 C 来关联图像区域和文本表达,其中每种颜色
![]()
是由它的视觉外观
![]()
(如 RGB (255, 0, 0))和颜色文本
![]()
(如:red)来定义的。然后他们用一种独特的颜色
![]()
标记图像中的每个区域候选 v_i,以此来定位,这会产生一组彩色图像候选Ψ(R; C),其中 Ψ(·) 表示视觉 sub-prompt。
在实验中,研究者发现,用实心块给目标着色比用边界框效果更好,因为纯色目标在现实世界的图像中更为常见(如红色 T 恤、蓝色车)。由于视觉 sub-prompt 被添加到原始图像中,因此 VL-PTM 的架构或参数不会发生变化。
文本 sub-prompt
文本 sub-prompt 旨在提示 VL-PTM 建立查询文本与被视觉 sub-prompt 标记的图像区域的联系。具体来说,此处用一个如下所示的模板 T (·) 将查询文本 q(如「the horse watched by the woman」)转换为填空查询:
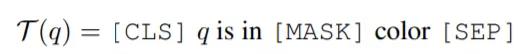
如此一来,VL-PTM 会被提示决定哪个区域的颜色更适合填充掩码(如红色或黄色),如下所示:
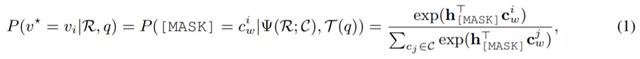
其中,v^* 表示目标区域,
![]()
是
![]()
在预训练 MLM head 中的嵌入。需要注意的是,这个过程并没有引入任何新的参数,而且还缩小了预训练和微调之间的差距,因此提高了 VL-PTM 微调的数据效率。
实验结果
在实验部分,研究者对 CPT 的能力进行了评估,设置了 zero-shot、few-shot 和全监督等多种情况,主要结果如下表 1 所示:
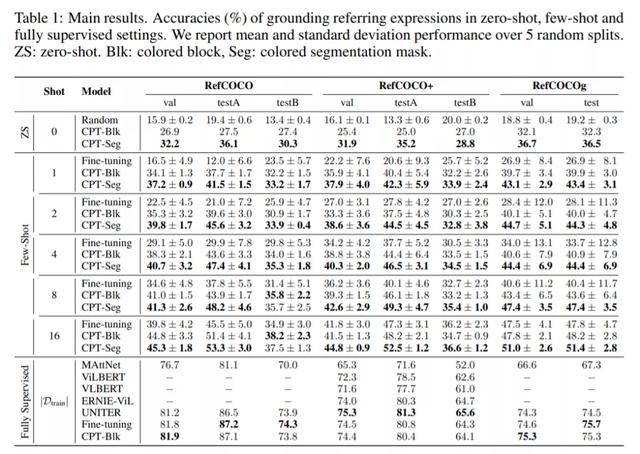
从表中可以看出:
1. 在 zero-shot 和 few-shot 设置中,CPT 的性能大大优于随机基线和强微调基线。例如,使用色块作为视觉 sub-prompt,在 RefCOCO one shot 中,CPT 绝对准确率提高了 17.3%,相对标准差平均降低了 73.8%。这表明 CPT 可以有效地提高 VL-PTM 微调的数据效率,并激发 VL-PTM 的视觉定位潜力。
2. 在视觉 sub-prompts 中用分割掩码给目标着色(CPT-Seg)获得了比块(CPT-Blk)更好的结果。这是因为适合物体轮廓的纯色在现实世界的图像中更常见,这使得 CPT-Seg 成为更自然的视觉 sub-prompt(尽管需要更强的注释来训练分割工具)。
3. 值得注意的是,CPT 实现的标准差明显小于微调。例如,在 RefCOCO 评估中,CPT-Blk one-shot 相对标准差平均降低了 73.8%。这表明,来自预训练的连贯微调方法可以带来更稳定的 few-shot 训练,这是评估 few-shot 学习模型的关键因素。
4. 在 RefCOCO + 评估中,CPT-Blk 在 shot 数为 16 时比微调表现略差。原因是 RefCOCO + 有更多的基于颜色的表达(比如穿红色衬衫、戴蓝色帽子的人),这会干扰基于颜色的 CPT。然而,这个问题可以通过在全监督场景中使用更多的微调实例来缓解,在这种场景中,模型能够学习如何更好地区分查询文本和 promp 模板中的颜色。
5. 在全监督的设置下,CPT 实现了与强微调 VL-PTM 相当的性能。这表明,即使在全监督的场景中,CPT 也是 VL-PTM 的一种有竞争力的调优方法。
综上所述,与普通的微调方法相比,CPT 在 zero-shot、few-shot 和全监督的视觉定位任务中都实现了与之相当或更优越、更稳定的性能。
更多细节请参见论文。





















评论