微美全息科学院:虚拟现实中基于视觉的人机手势交互技术
交互性是虚拟现实的三大特性之一,虚拟现实的人机交互是指用户以便携、自然的方式通过交互设备与计算机所产生的虚拟世界对象进行的交互, 通过用户与虚拟环境之间的双向感知建立起一个更为自然、和谐的人机环境,是虚拟现实为用户提供体验、走向应用的核心环节。作为纳斯达克上市企业“微美全息US.WIMI”旗下研究机构“微美全息科学院”的科学家们对一种新型的虚拟现实交互技术-基于视觉的手势交互技术进行介绍。

图1.基于视觉的手势交互技术
1、基于视觉的手势交互技术
手势是人与人之间非语言交流的最重要方式,也是人与VR虚拟环境交互的重要方式之一。手势识别的准确性和快速性直接影响人机交互的准确性、流畅性和自然性。基于视觉的手势交互,用户无需穿戴设备,具有交互方便、自然和表达丰富的优点,符合人机自然交互的大趋势,适用范围广。基于视觉的手势交互作为人机交互的重要组成部分,对实现人与VR虚拟环境自然交互具有重要意义,有广泛的应用前景。
基于视觉的手势交互使用手势识别方法实现人机交互,从交互过程来看,主要包含4个步骤,如图2所示: 1) 数据采集:通过摄像头采集人体手部图像; 2) 手部检测与分割:检测输入图像是否有手,如果有手,则检测出手的具体位置,并将手部分割出来; 3) 手势识别:提取手部区域特征并将其种类按照一定方法识别出来; 4) 使用识别结果控制虚拟环境中的人或物:将识别结果发送给虚拟环境控制系统,从而控制虚拟人/物实现特定运动。其中,手势识别是整个手势交互过程的核心,而手部检测与分割则是手势识别的基础。
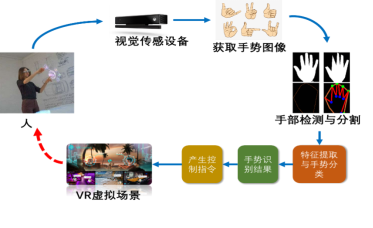
图2 基于视觉的人机交互流程
手势识别是手势交互的关键技术,直接影响手势交互的效果,在整个交互过程中占举足轻重的地位。下面对手势识别技术进行介绍。
1.1手部检测与分割
手部检测与分割是手势识别的基础。手部检测是检测图像数据是否有手,并找出手在图像中的具体位置。手部分割是将手部区域从图像中分割出来,便于后续操作,有利于减少计算量。手部检测与分割是手势识别的第一步,也是手势识别的基础。一般情况下表征物体有 3 种特性:边缘形状、纹理以及颜色。在一定距离时,手部的纹理表现较为平滑,对比性较差,因此利用纹理特征检测手部,优势不明显。对于手部检测,目前多用形状和颜色特征检测手部.因此,常见的手部检测方法大致分为以下几类:基于形状信息特征的方法、基于肤色信息的方法和基于运动信息的方法。
1.1.1 基于形状信息特征的方法
形状是描述图像内容的重要特征,手部的形状和其他物体的形状存在一定差异,因此可以利用形状的差异将手部从图像中提取出来,还可以基于形状信息使用图像训练集训练分类器检测手部,此类方法是基于分类的物体检测方法,它通常假设不同手势的外形不同,并且这种不同远大于不同人做同一种手势的不同。此类方法常使用方向梯度直方图(HOG)、 Haar 小波和尺度不变特征变换(SIFT)等特征。
1.1.2 基于肤色信息的方法
由于人体肤色与背景存在一定差异性,并且肤色具有天然的平移不变性及旋转不变性,不受拍摄视角、人体姿势等影响,因此,基于肤色信息的方法计算量较小,运算速度较快,是手部检测的常用方法,但容易受人种、光照、类肤色背景等影响。使用肤色信息检测手部,首先需选择色彩空间(RGB、 HSV、 YCbCr、 YUV 等)。为了增强肤色检测在不同光照条件下的鲁棒性,优先选取将亮度与色度分量分离的色彩空间(如 HSV、 YCbCr 等)。
1.1.3 基于运动信息的方法
运动信息可作为检测手部的一种方法,但使用运动信息检测手部时对手势者或背景常做一些假设,如手势者的动作不能太快,手势者相对背景静止或运动量很小、场景光照条件变化不大等。假设图像采集设备固定不动,则背景静止或变化很小,这种检测方式称为静态背景检测,这种情况主要有3 种检测方法:光流法、帧间差分法和背景差分法。
光流法可获取全面场景信息,不仅能获取手势信息,还可获取手势外的其他信息,如场景信息。在不知道图像中任何相关信息的情况下,光流法也可独立检测出运动目标,独立性较好,应用范围较广,但光流法较复杂,如果不使用加速技术,很难满足实时要求。帧间差分法较简单,计算速度较快,可在一定程度上消除外界因素影响,稳定性较好,但对运动目标的检测精度较低,提取目标物体边界不完整,对相邻帧间的间隔有较高要求。背景差分法较简单,运算速度较快,能较完整地检测运动目标,但该算法只能应用于摄像头固定的静态背景情况下,并且误检率较高,检测的运动区域常包含手部之外的区域(如手臂)。运动信息不仅能单独使用来检测手部,还可以与其他视觉信息结合检测手部区域。
1.2手势识别
手势识别是手势交互的关键技术,是对分割后的手部区域进行特征提取和手势分类的过程,也可以理解为将模型参数空间的点(或轨迹)分类到该空间的某个子集的过程。其中,静态手势(基于图像的手势)对应模型参数空间点,动态手势(基于视频的手势)对应模型参数空间的一条轨迹。手势识别方法大致分为以下几种:基于模板匹配的方法、基于机器学习的方法和隐马尔可夫模型方法等。
1.2.1基于模板匹配的方法
模板匹配法是最早出现、最简单的模式识别方法之一,多用于静态手势识别。该方法是将输入图像与模板(点、曲线或形状)进行匹配,根据匹配相似度进行分类,匹配度计算方法有:欧氏距离、Hausdorff 距离、夹角余弦等。轮廓边缘匹配、弹性图匹配等都属于模板匹配方法。模板匹配方法的优点是简单快速,不受光照、背景、姿态等影响,应用范围较广,但分类准确率不高,可识别手势种类有限,适用于小样本、外形等变化不大的情况。
1.2.2基于机器学习的方法
机器学习使用统计学方法解决不确定性问题,机器学习致力于研究计算机从数据中产生模型的算法,即“学习算法”。有了学习算法,就能基于数据产生模型,面对新情况时,就能使用此模型进行相应判断。机器学习发展迅速,是现阶段计算机应用领域的研究热点。许多基于表观的静态手势识别使用机器学习方法。目前常用的机器学习算法有支持向量机法、人工神经网络法、AdaBoost方法等。
支持向量机是一种二分类模型,它的基本模型是定义在特征空间上的最大间隔的线性分类器。支持向量机还可以利用核方法,将其扩展为非线性分类器。它的学习策略是间隔最大化,可形式化为求解凸二次规划问题,这样的凸二次规划问题具有全局最优解。
人工神经网络诞生于 20 世纪 40 年代初期,它是由具有适应性的简单单元组成的广泛并行互联的网络,它能够模拟生物神经系统对真实世界所作出的交互反应,具有较强的容错性、鲁棒性、高度并行性、自适应性、抗干扰性和移动学习能力等。随着深度学习热潮的到来,神经网络再次受到关注,被广泛应用于语音识别和图像分类等问题。神经网络种类繁多,手势识别率一般受手部检测模型优劣、训练样本多少等限制。
boosting 算法是将弱学习算法提升为强学习算法的统计学习方法。它通过反复修改训练数据的权值分布,构建一系列基本分类器(弱分类器),并将这些基本分类器线性组合构成一个强分类。boosting 算法要求提前预知弱分类器错误上限,难以应用于实际。将加权投票与在线分配问题结合,在boosting 框架下进行推广便得到 AdaBoost。
AdaBoost是 boosting家族的著名代表,在人体检测与识别等领域有着广泛的应用。AdaBoost 具有下列优点: AdaBoost 提供一种框架,在框架内可使用各种方法构建子分类器,可以使用简单的弱分类器,不用筛选特征,很少发生过拟合现象。AdaBoost 不需要弱分类器的先验知识,也不需要预先知道弱分类器的上限,最后得到的强分类器精度依赖于所有弱分类器的分类精度,可以深挖弱分类器的能力。AdaBoost 可根据弱分类器的反馈,自适应调整假定的错误率,执行效率很高,并且能显著提高学习精度。但在训练过程中,AdaBoost 致使难分类样本的权重呈指数增长,训练将会过于偏向这类困难样本,进而左右误差的计算和分类器的挑选,降低分类器精度。另外,AdaBoost 易受噪声干扰,执行效果依赖于弱分类器的选择,且弱分类器训练时间偏长。
1.2.3隐马尔可夫模型方法
隐马尔可夫模型(HMM)是关于时序的概率模型,描述由一个隐藏的马尔可夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测而产生观测随机序列的过程。隐马尔可夫模型非常适合描述序列模型,特别适合上下文相关的场合。隐马尔可夫模型是马尔可夫链的一个扩展,是结构简单的动态贝叶斯网络,是著名的有向图模型,作为基于概率统计的典型方法在语音识别、手势识别等领域有广泛应用。对于手势识别来说,隐马尔可夫模型比较适合连续手势识别,尤其适合复杂的涉及上下文的手势。隐马尔可夫模型训练和识别的计算量很大,尤其是在连续信号的分析中,状态的转换导致需要计算大量的概率密度,参数变多,使得样本训练及目标识别的速度变慢。为了解决此问题,一般手势识别系统中采用离散隐马尔可夫模型进行分析。
2. 结束语
基于视觉的手势交互是人与虚拟环境交互的重要方式,具有交互自然、方便的优点,对虚拟现实的沉浸式体验具有重要意义,虽然目前已经取得了一些阶段性研究成果,但是仍有许多问题亟待解决,如复杂背景下的手部检测、与其他交互方式的融合、功能集成等。基于视觉的手势交互具有重要的科学价值和广阔的应用前景,随着虚拟现实对沉浸式体验需求的不断增强,基于视觉的手势交互必将在虚拟现实中发挥重要作用。
微美全息科学院成立于2020年8月,致力于全息AI视觉探索科技未知,以人类愿景为驱动力,开展基础科学和创新性技术研究。全息科学创新中心致力于全息AI视觉探索科技未知, 吸引、集聚、整合全球相关资源和优势力量,推进以科技创新为核心的全面创新,开展基础科学和创新性技术研究。微美全息科学院计划在以下范畴拓展对未来世界的科学研究:
一、全息计算科学:脑机全息计算、量子全息计算、光电全息计算、中微子全息计算、生物全息计算、磁浮全息计算
二、全息通信科学:脑机全息通信、量子全息通信、暗物质全息通信、真空全息通信、光电全息通信、磁浮全息通信
三、微集成科学:脑机微集成、中微子微集成、生物微集成、光电微集成、量子微集成、磁浮微集成
四、全息云科学:脑机全息云、量子全息云、光电全息云
以下是微美全息科学院的部分科学家成员:
郭松睿,湖南大学计算机科学技术工学博士,曾在中科院科学计算国家重点实验室 合现实技术研修班 学习混合现实,增强现实技术,参与研发多个重点项目。
江涛,中国科学院沈阳自动化研究所博士,机器人学国家重点实验室,研究方向为微型仿生飞行器的气动/结构设计、控制与系统开发,在2018年获得 ICRCA-2018 机器人 EI 国际会议"最佳论文奖"。
杨军超,重庆邮电大学通信与信息工程学院信息与通信工程专业博士研究生,华盛顿大学电子工程学院联合培养博士,长期研究虚拟现实、5G多媒体传输优化、基于MEC的智能转码优化,以第一作者发表SCI/EI 论文 6 篇,中文核心 1 篇,申请专利 4 项。
李维娜 ,2017 年博士毕业于韩国忠北国立大学的信息和通信工程学院。2017 年 8 月去了新加坡的 Singapore-MIT Alliance for research and technology centre(SMART)从事压缩全息(compressive digital holography)的博士后工作,2018 年 11 月进入清华大学深圳国际研究生院的先进制造学部,在以前工作的基础上把数字全息(digital holography)拓展到机器学习(machinelearning)领域,特别是对 U 型网络(U-net)的改进和应用。在上述研究领域以第一作者发表高水平论文 5 篇,以第二作者发表的高水平论文2 篇。
曲晓峰,香港理工大学博士,现任清华大学深圳研究生院博士后,主要研究生物特征识别、机器视觉、模式识别,与绿米联创合作进行嵌入式产品算法、深度学习应用、图像与视频相关算法以及生物特征识别相关产品的开发。
危昔均,香港理工大学康复治疗科学系博士,南方医科大学深圳医院虚拟现实康复实验室负责人,主要研究基于虚拟现实技术的康复系统搭建及相关临床和基础研究。
单羽,昆士兰科技大学数字媒体研究中心(澳大利亚)博士,研究方向为虚拟现实娱乐产业与亚洲创意经济,曾参加多场虚拟现实产业的国际学术会议并发表主题演讲,发表多篇以“虚拟现实艺术”相关的学术论文,并参与国内多个虚拟现实娱乐产业领域的项目研究。
刘超,新加坡南洋理工大学博士,是深圳市南山区领航人才,深圳市海外高层次人才孔雀计划C类, Molecular Physics 2011年度最佳年轻作者提名,主要研究方向为人工智能预测过渡金属氢化物金属氢键键长与解离能和环式加成反应中量子力学/分子力学反应机理研究,曾参与过流程模拟软件的开发与研究。
张婷,美国西北大学博士后,香港大学博士,海外高层次人才孔雀计划C类,主要从事VR/MR关键技术研发应用和复杂服务系统优化等研究,发表全息专利5项。获全国"挑战杯"创业计划大赛 湖北省一等奖,华中科技大学一等奖。
姚卫,湖南大学计算机科学与技术工学博士,主要研究方向:忆阻神经网络及其动力学行为,应用于:图像处理、安全通信。基于VDCCTA具有长时记忆特性的忆阻器电路及其构成的神经网络。参与设计基于忆阻器的神经网络系统模型。基于忆阻器的仿生物神经元和突触连接的微电子电路设计,参与基于忆阻器的神经网络系统模型的设计与动力学行为的分析。
彭华军,博士,毕业于香港科技大学显示技术研究中心(CDR),从事硅基液晶器件、AMOLED材料与器件、TFT器件、显示光学等研发工作。彭博士一直从事信息显示领域前沿工作,涵盖电视图像色彩管理、AMOLED生产制造、微显示芯片设计与制造、投影与近眼显示光学等。彭博士在国际刊物上发表20篇文章。已申请近50项中国发明和美国发明专利,其中10项美国专利和20项中国发明专利获得授权。
陈能军,中国人民大学经济学博士、上海交通大学应用经济学博士后,广东省金融创新研究会副秘书长、广东省国际服务贸易学会理事。主要从事文化科技和产业经济的研究,近年来在版权产业领域研究方面有较好的建树。近年来先后主持、主研“5G时代的数字创意产业:全球价值链重构和中国路径”“深圳加快人工智能产业发展研究”“贸易强国视角下中国版权贸易发展战略研究”,“文化科技融合研究:基于版权交易与金融支持的双重视角”等省部级课题多项,并在《商业研究》《中国流通经济》《中国文化产业评论》等核心期刊发表论文多篇。
潘剑飞,香港理工大学博士学位,现为广东省高校“千百十工程”人才,深圳市海外高层次人才,深圳市高层次人才、深圳大学优秀学者。研究领域主要为自动化+VR 应用、先进数字化制造、 数字制造全息孪生工厂、机器人等。主持多项国家自然科学基金项目、广东省科技计划项目和广东省自然科学基金项目。
杜玙璠,北京交通大学光学工程博士,取得与显示产品相关专利20余项,发表期刊文章3篇,曾打造全球最高分辨率的8K*4K 的VR产品,并提出了采用光场显示技术,解决VR辐辏冲突问题;推出首款国产化率100%的单目AR眼镜,第一次联合提出基于未来空间信息的非接触式交互的操作系统概念(System On Display),在运营商体系进行虚拟现实数字产业合作。
伍朝志,深圳大学光机电工程与应用专业博士,研究方向主要为精密/微细电解加工,发表过多篇期刊论文和会议论文,获得三项相关专利,曾参与国家重点研发计划 、国家自然科学基金重大研究计划重点项目等。
微美全息科学院旨在促进计算机科学和全息、量子计算等相关领域面向实际行业场景和未来世界的前沿研究。建立产研合作平台,促进重大科技创新应用,打造产业、研究中心深度融合的生态圈。微美全息科学院秉承“让有人的地方就有科技”为使命,专注未来世界的全息科学研究,为全球人类科技进步添砖加瓦。
微美全息成立于2015年,纳斯达克股票代码:WiMi。
微美全息专注于全息云服务,主要聚集在车载AR全息HUD、3D全息脉冲LiDAR、头戴光场全息设备、全息半导体、全息云软件、全息汽车导航、元宇宙全息AR/VR设备、元宇宙全息云软件等专业领域,覆盖从全息车载AR技术、3D全息脉冲LiDAR技术、全息视觉半导体技术、全息软件开发、全息AR虚拟广告技术、全息AR虚拟娱乐技术、全息ARSDK支付、互动全息虚拟通讯、元宇宙全息AR技术,元宇宙虚拟云服务等全息AR技术的多个环节,是一家全息云综合技术方案提供商。





















评论