应用实践 | 海量数据,秒级分析!Flink+Doris 构建实时数仓方案
编者荐语:随着领创集团的快速发展,为了满足十亿级数据量的实时报表统计与决策分析,领创集团选择了 Flink + Doris 的实时数仓方案。本篇文章详尽了介绍了此方案的实践过程。
以下文章来源于领创集团Advance Group, 作者苏浩
原文链接:海量数据!秒级分析!Flink+Doris构建实时数仓方案
业务背景
Advance Intelligence Group(领创集团)成立于 2016 年,是一家以 AI 技术驱动的科技集团,致力于通过科技创新的本地化应用,改造和重塑金融和零售行业,以多元化的业务布局打造一个服务于消费者、企业和商户的生态圈。集团旗下包含企业业务和消费者业务两大板块,企业业务包含 ADVANCE.AI 和 Ginee,分别为银行、金融、金融科技、零售和电商行业客户提供基于 AI 技术的数字身份验证、风险管理产品和全渠道电商服务解决方案;消费者业务 Atome Financial 包括亚洲领先的先享后付平台 Atome 和数字金融服务。
2021 年 9 月,领创集团宣布完成超 4 亿美元 D 轮融资,融资完成后领创集团估值已超 20 亿美元,成为新加坡最大的独立科技创业公司之一。业务覆盖新加坡、印度尼西亚、中国大陆、印度、越南等 17 个国家与地区,服务了 15 万以上的商户和 2000 万消费者。
随着集团业务的快速发展,为满足十亿级数据量的实时报表统计与决策分析,我们选择基于 Apache Flink + Apache Doris 构建了实时数仓的系统方案。
Doris 基本原理
Apache Doris 基本架构非常简单,只有 FE(Frontend)、BE(Backend) 两种角色,不依赖任何外部组件,对部署和运维非常友好。架构图如下:

FE(Frontend)以 Java 语言为主。
主要功能职责:
- 接收用户连接请求(MySQL 协议层)
- 元数据存储与管理
- 查询语句的解析与执行计划下发
- 集群管控
FE 主要有有两种角色,一个是 Follower,还有一个 Observer,Leader 是经过选举推选出的特殊 Follower。Follower 主要是用来达到元数据的高可用,保证单节点宕机的情况下,元数据能够实时地在线恢复,而不影响整个服务。
BE(Backend) 以 C++ 语言为主。
主要功能职责:
- 数据存储与管理
- 查询计划的执行
技术架构
整体数据链路如下图:
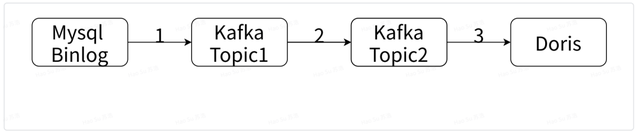
- 通过 FlinkCDC 采集 MySQL Binlog 到 Kafka 中的 Topic1
- 开发 Flink 任务消费上述 Binlog 生成相关主题的宽表,写入 Topic2
- 配置 Doris Routine Load 任务,将 Topic2 的数据导入 Doris
应用实践
关于步骤1和步骤2的实践,“基于 Flink-CDC 数据同步⽅案” 的文章中已有说明,本文将对步骤3展开详细的说明。
建表
因业务数据经常伴随有 UPDATE,DELETE 等操作,为了保持实时数仓的数据粒度与业务库一致,所以选择 Doris Unique 模型(数据模型在下文有重点介绍)具体建表语句如下:
CREATE TABLE IF NOT EXISTS table_1(key1 varchar(32),key2 varchar(32),key3 varchar(32),value1 int,value2 varchar(128),value3 Decimal(20, 6),data_deal_datetime DateTime COMMENT '数据处理时间',data_status INT COMMENT '数据是否删除,1表示正常,-1表示数据已经删除') ENGINE=OLAPUNIQUE KEY(`key1`,`key2`,`key3`)COMMENT "xxx"DISTRIBUTED BY HASH(`key2`) BUCKETS 32PROPERTIES ("storage_type"="column","replication_num" = "3","function_column.sequence_type" = 'DateTime');
可以看到,表结构中有两个字段分别是 data_deal_datetime,data_status。
- data_deal_datetime 主要是相同 key 情况下数据覆盖的判断依据
- data_status 用来兼容业务库对数据的删除操作
数据导入任务
Doris 提供了主动拉取 Kafka 数据的功能,配置如下:
CREATE ROUTINE LOAD database.table1 ON table1COLUMNS(key1,key2,key3,value1,value2,value3,data_deal_datetime,data_status),ORDER BY data_deal_datetimePROPERTIES("desired_concurrent_number"="3","max_batch_interval" = "10","max_batch_rows" = "500000","max_batch_size" = "209715200","format" = "json","json_root" = "$.data","jsonpaths"="[\"$.key1\",\"$.key2\",\"$.key3\",\"$.value1\",\"$.value2\", \"$.value3\",\"$.data_deal_datetime\",\"$.data_status\"]")FROM KAFKA("kafka_broker_list"="broker1_ip:port1,broker2_ip:port2,broker3_ip:port3","kafka_topic"="topic_name","property.group.id"="group_id","property.kafka_default_offsets"="OFFSET_BEGINNING");
导入语句中:
- ORDER BY data_deal_datetime 表示根据 data_deal_datetime 字段去覆盖 key 相同的数据
- desired_concurrent_number 表示期望的并发度。
max_batch_interval/max_batch_rows/max_batch_size 这 3 个参数分别表示:
- 每个子任务最大执行时间。
- 每个子任务最多读取的行数。
- 每个子任务最多读取的字节数。
任务监控与报警
Doris routine load 如果遇到脏数据会导致任务暂停,所以需要定时监控数据导入任务的状态并且自动恢复失败任务。并且将错误信息发至指定的 lark 群。具体脚本如下:
import pymysql #导入 pymysqlimport requests,json#打开数据库连接db= pymysql.connect(host="host",user="user", password="passwd",db="database",port=port)# 使用cursor()方法获取操作游标cur = db.cursor()#1.查询操作# 编写sql 查询语句 sql = "show routine load"cur.execute(sql) #执行sql语句results = cur.fetchall() #获取查询的所有记录for row in results : name = row[1] state = row[7] if state != 'RUNNING': err_log_urls = row[16] reason_state_changed = row[15] msg = "doris 数据导入任务异常:\n name=%s \n state=%s \n reason_state_changed=%s \n err_log_urls=%s \n即将自动恢复,请检查错误信息" % (name, state,reason_state_changed, err_log_urls) payload_message = { "msg_type": "text", "content": { "text": msg }} url = 'lark 报警url' s = json.dumps(payload_message) r = requests.post(url, data=s) cur.execute("resume routine load for " + name)cur.close()db.close()
现在线上配置的监控 1 分钟执行一次,如果遇到任务暂停,会自动恢复导入任务,但是导致任务失败的脏数据会跳过,此时需要人工排查失败原因,修复后重新触发该条数据的导入。
数据模型
Doris 内部表中,主要有 3 种数据模型,分别是 Aggregate 、Unique 、Duplicate。在介绍数据模型之前,先解释一下 Column:在 Doris 中,Column 可以分为两大类:Key 和 Value。从业务角度看,Key 和 Value 分别对应维度列和指标列。
Aggregate
简单来说,Aggregate 模型就是预聚合模型,类似于 MOLAP,通过提前定义 Key 列及 Value 列的聚合方式,在数据导入的时候已经将 Key 列相同的数据按照 value 列的聚合方式聚合在一起,即最终表里 Key 相同的数据只保留一条,Value 按照相应的规则计算。下面举例说明。
表结构如下:
CREATE TABLE tmp_table_1 ( user_id varchar(64) COMMENT "用户id", channel varchar(64) COMMENT "用户来源渠道", city_code varchar(64) COMMENT "用户所在城市编码", last_visit_date DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间", total_cost BIGINT SUM DEFAULT "0" COMMENT "用户总消费" )ENGINE=OLAPAGGREGATE KEY(user_id, channel, city_code)DISTRIBUTED BY HASH(user_id) BUCKETS 6 PROPERTIES("storage_type"="column","replication_num" = "1"):
表结构中,Key 列分别是 user_id、channel、city_code ,Value 列是 last_visit_date、total_cost,他们的聚合方式分别为 REPLACE、SUM。
现在,向该表中插入一批数据:
insert into tmp_table_1 values('suh_001','JD','001','2022-01-01 00:00:01','57');insert into tmp_table_1 values('suh_001','JD','001','2022-02-01 00:00:01','76');insert into tmp_table_1 values('suh_001','JD','001','2022-03-01 00:00:01','107');
按照我们的理解,现在 tmp_table_1 中虽然我们插入了 3 条数据,但是这 3 条数据的 Key 都是一致的,那么最终表中应该只有一条数据,并且 last_visit_date 的值应为"2022-03-01 00:00:01",total_cost 的值应为 240。下面我们验证一下:
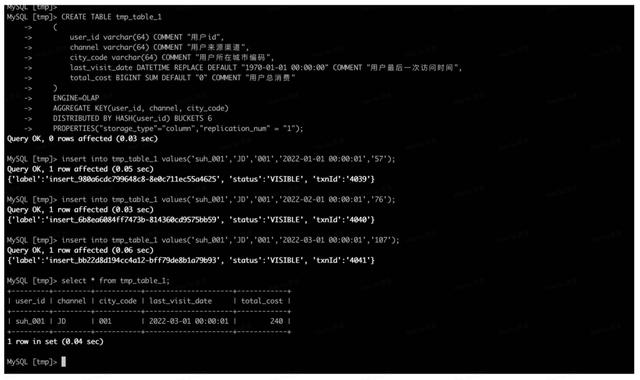
可以看到,结果与我们预期⼀致。
Unique 模型
正如本次建设的实时数仓那样,我们更加关注的是如何保证主键的唯⼀性,即如何获得 Primary Key 唯⼀性约束。⼤家可以参考上⾯建表的例⼦,在这⾥不再举例说明。
Duplicate 模型
在某些多维分析场景下,数据既没有主键,也没有聚合需求。因此引⼊ Duplicate 数据模型来满⾜这类需求。举例说明。
表结构如下:
CREATE TABLE tmp_table_2 ( user_id varchar(64) COMMENT "用户id", channel varchar(64) COMMENT "用户来源渠道", city_code varchar(64) COMMENT "用户所在城市编码", visit_date DATETIME COMMENT "用户登陆时间",cost BIGINT COMMENT "用户消费金额" )ENGINE=OLAPDUPLICATE KEY(user_id, channel, city_code)DISTRIBUTED BY HASH(user_id) BUCKETS 6 PROPERTIES("storage_type"="column","replication_num" = "1");
插入数据:
insert into tmp_table_2 values('suh_001','JD','001','2022-01-01 00:00:01','57');insert into tmp_table_2 values('suh_001','JD','001','2022-02-01 00:00:01','76');insert into tmp_table_2 values('suh_001','JD','001','2022-03-01 00:00:01','107');
因为此时数据是 Duplicate 模型,不会进行任何处理,查询应该能查到 3 条数据
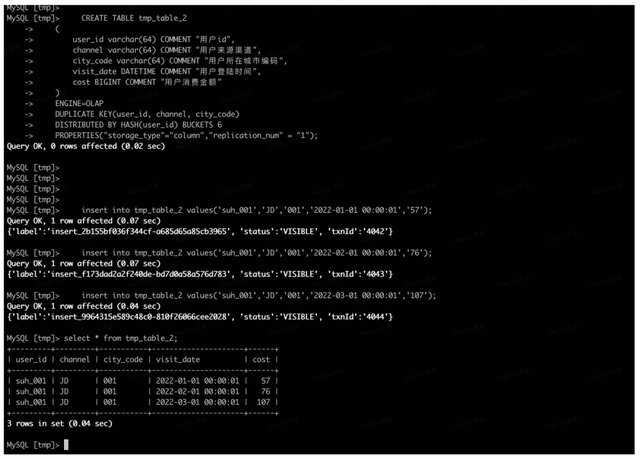
数据模型的选择建议
因为数据模型在建表时就已经确定,且无法修改。所以,选择一个合适的数据模型非常重要。
Aggregate 模型可以通过预聚合,极大地降低聚合查询时所需扫描的数据量和查询的计算量,非常适合有固定模式的报表类查询场景。但是该模型对 count(*) 查询很不友好。同时因为固定了 Value 列上的聚合方式,在进行其他类型的聚合查询时,需要考虑语意正确性。
Unique 模型针对需要唯一主键约束的场景,可以保证主键唯一性约束,但是无法利用 ROLLUP 等预聚合带来的查询优势。
Duplicate 适合任意维度的 Ad-hoc 查询,虽然同样无法利用预聚合的特性,但是不受聚合模型的约束,可以发挥列存模型的优势。
总结
Flink + Doris 构建的实时数仓上线后,报表接口相应速度得到了明显提高,单表 10 亿级聚合查询响应速度 TP95 为 0.79 秒,TP99 为 5.03 秒。到目前为止,整套数仓体系已平稳运行 8 个多月。

SelectDB 是一家开源技术公司,致力于为 Apache Doris 社区提供一个由全职工程师、产品经理和支持工程师组成的团队,繁荣开源社区生态,打造实时分析型数据库领域的国际工业界标准。基于 Apache Doris 研发的新一代云原生实时数仓 SelectDB,运行于多家云上,为用户和客户提供开箱即用的能力。





















评论