深兰科技在KDD Cup摘冠,海量数据挖掘实现再进化
深兰科技在KDD Cup摘冠,海量数据挖掘实现再进化
8月6日,KDD Cup 2019 AutoML Track挑战赛揭晓成绩,来自中国的人工智能企业——深兰科技战胜了新加坡国立大学、阿里巴巴集团、清华大学、海康威视、微软亚洲研究院等顶尖学府及机构,斩获了该项赛事的第一名。

截图来源:https://www.kdd.org/kdd2019/docs/Winners_AutoML_4Paradigm.pdf
KDD Cup有"大数据奥运会"之称,备受全球数据挖掘技术团队的欢迎,既是一争高下的舞台,也是创新性数据挖掘技术方案诞生的摇篮。

在夺得AutoML Track挑战赛头名后,深兰科技的技术团队也分享了相关技术细节并将此次参赛方案的代码开源。根据此次挑战赛的具体要求来看,深兰科技面临的主要挑战包括:第一,整个处理、运行过程中时间和内存的严格限制;第二,给定数据特征的挖掘和生成难度;第三,系统和模型的最终完美融合。
为了解决这些已知和未知挑战,此次深兰科技在参赛过程中创新了很多数据处理和挖掘的方法论。其一,在时间和内存的严格限制下,采用预处理、峰值监听等方式避免超出风险;其二,在数据特征生成等关键环节,反复试错并论证最佳的技术方案,最终将数据特征生成的时间从几个小时缩短到几秒,充分实现提效。
其中的第二点,即数据特征生成中的自动特征工程这一环节,深兰科技可谓给出了一个值得行业借鉴的解决方案,并取得了非常惊人的成果。
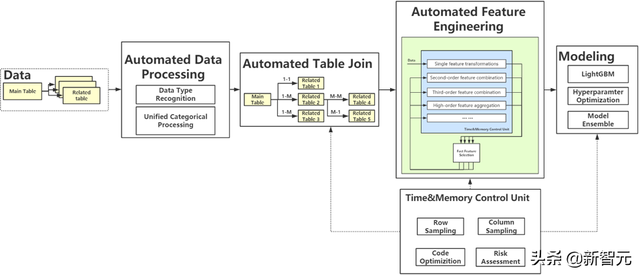
深兰科技参赛的AutoML框架
从实际应用场景和案例来看,目前在数据挖掘备受热捧的金融、工业、医疗等行业,这样的技术处理方法论具备非常强大的实战能力,能够突破现有瓶颈,并为数据挖掘提供更好的价值实现途径。
深兰科技夺冠背后,行业面临海量数据的发掘窘境
互联网和科技巨头跻身的领域,比如电商、金融等,往往是数据挖掘最先起势的地方,因为这里有海量的用户数据,而互联网巨头们对于挖掘数据价值的需求非常旺盛。近几年,国内的BAT,国外的亚马逊、Facebook等巨头都不谋而合地发力数据挖掘。
涉及到具体的应用行业和领域,数据挖掘的发展亦是风生水起。根据今年赛迪顾问发布的《中国大数据产业白皮书及百强榜单》,2021年,金融行业的大数据产业规模预计会接近1000亿元,增长率保持在27%以上;工业领域的大数据产业规模预计会超过800亿元,增长率则超过30%;健康医疗领域的大数据产业规模预计会超过500亿元,增长率接近40%。
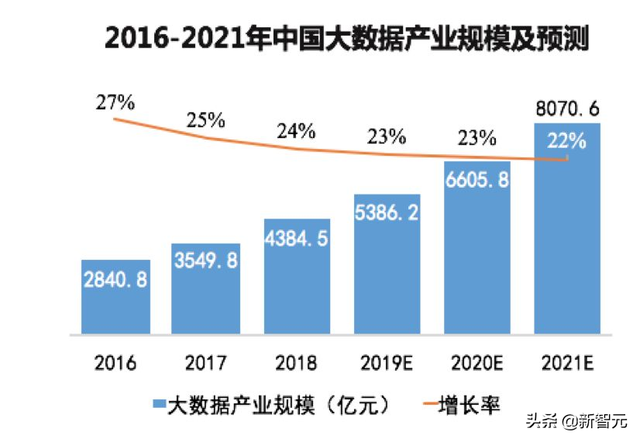
尽管近几年这些行业和领域在数据挖掘上的场景不断实现拓展,比如金融行业的金融监管、金融反欺诈;工业领域的边缘智能、流程优化;医疗领域的公共卫生、临床科研等等。但这些场景下的数据挖掘技术在应用时,普遍会面临一些共同的挑战,比如对海量数据的及时处理和输出、数据特征的实时关联和分析……
在实际应用中,这些挑战可以表现为产品和流程方面的瓶颈,比如某些金融产品缺乏用户期望的数据分析功能,或是某些工厂面临很高的数据处理和分析成本。
不论是金融业,还是工业,很多平台和企业其实都很难去用好海量的数据,要么是不具备筛选数据的能力,要么是不具备深度处理数据的能力,造成了有数据而不会用,有数据而用不好的尴尬处境。这么一来会造成一个结果:低效运行的环节依然低效,关键环节的效率提升遭遇天花板。
究其原因,这些领域中存在的技术短板,或者说未进化的技术,才是数据挖掘变成"数据挖绝"的罪魁祸首。基于这样的行业和应用现状,技术必须要在关键节点实现再进化,才可以显著改善这些问题。
深兰科技AutoML强势赋能,海量数据挖掘不再难
深兰科技的技术方法论,在解决数据挖掘所面临的海量数据问题时,往往会有比较直接的效果。
先看金融业。在深兰科技自研的AutoML模型下,凭借预先设定的条件和计算方式,平台能够快速从海量数据中筛选出有价值的数据,并对其进行特征的生产,继而分析、组合等,最终输出一个合适的股价数据。
对于证券平台而言,这个模型成熟后可以植入到产品中,提高用户的使用体验,增强自身的差异化竞争力。
再看工业领域,对于工厂或生产线来说,AutoML模型的数据特征快速生成能力,一方面可以依据生产环节或零部件生产线对海量数据进行预分类,比如电器的内部和外部,电器的开关、门、内胆等等;另一方面可以用实现设定的算法,对这些数据进行效用性筛选,比如某些环节的数据特征杂乱,不太统一,这可能意味着这一生产环节存在被优化的潜力。
最后再看医疗领域,在AutoML模型下,基于医生设定的前提条件,海量数据全部或部分可以在短时间内先被进行特征生成,然后医生可以判断这些数据特征之间的关系,提前判定患者的情况,根据不同时期患者数据特征的对比,医生或许还能实现更早期的诊断,帮助患者早发现早治疗。
从以上场景的实际应用分析来看,深兰科技的AutoML模型在海量数据特征生成效率上极具优势,有利于产品的创新、流程的综合优化、疾病的提前预知等等。这意味着,在深兰科技的AutoML模型下,多场景下的海量数据挖掘难题会得到明显的缓解,更多的创新产品也会不断涌现出来。
深兰科技打头阵,数据挖掘将实现持续再进化
我们有理由相信,随着深兰科技AutoML模型的不断进化,海量数据的深度应用将逐渐走向常态化。
对于当前对海量数据挖掘比较依赖的应用场景,这样的技术一来可以提升整个行业或领域的运营、生产、维护等方面的效率,利于供需匹配、用户体验的不断升级,二来可带动行业或领域形成以海量数据挖掘为中心的生态体系,向大数据时代进一步靠拢。
所以说,深兰科技此次带来的自研AutoML,是技术层面的一次进步,也是对海量数据挖掘应用的一次关键升级。换言之,这是一次数据挖掘的再进化,具体体现为三点:其一,基础设施再进化,即数据挖掘技术走向公益化和公开化;其二,应用领域再进化,即催生更多可供挖掘数据的细分应用场景;其三,数据价值再进化,即数据挖掘量级提升所带来的综合价值提升。
目前深兰科技的AutoML已经在一些应用场景有很好的表现,比如在上海建青实验学校落地的教育"一手通",其后台采集的数据再经过AutoML系统自动建模可以分析出学生的兴趣爱好,随后进行个性化教学。而深兰科技在智能驾驶、AIoT等技术方面也有非常强大的团队和实验室。

学生通过手脉识别系统借阅图书
可以预见,这一数据挖掘的技术方案还会不断进化,其发展空间不可估量,未来应用数据挖掘的场景和领域,无疑将在效率和生态上实现大跃进,而海量数据挖掘技术也会成为众多行业或领域的核心工具。


















评论