最新!2022年IEEE VLSI 研讨会技术和电路亮点解析
2022 年 IEEE VLSI 技术和电路研讨会是首屈一指的国际会议,记录了微纳米集成电子学的步伐、进展和演变,计划于 2022 年 6 月 12 日至 17日举行。今年的研讨会也恰逢固态晶体管发明 75 周年。
研讨会的总体主题是“未来关键基础设施的技术和电路”,整合了先进技术开发、创新电路设计以及它们所支持的应用,作为我们全球社会向智能连接设备、基础设施和系统新时代过渡的一部分,这些设备、基础设施和系统改变了人类相互交流的方式。
以下是一些针对这一主题的重点论文:
技术和电路亮点
今年之前的两个单独的技术和电路专题讨论会合并为一个专题讨论会。以下是一些突出的论文,它们代表了技术和电路方面的共同进步:
超越 CMOS 机器学习
“用于语音识别并行数据处理的 HZO/Si FeFET 储层计算新方案的实验演示”——东京大学(论文 C25-1)
东京大学的研究人员提出了一种在并行数据处理器中使用铁电门 MOSFET (FeFET) 进行存储计算的新颖办法,它用于语音识别。存储计算是一种机器学习技术,它为边缘 AI 应用程序提供高效的在线学习,因为它只包含一层读书权重的训练。他们证明了 FeFET 的极化动力学可以在内存操作中执行计算。基本机器学习任务,如短期记忆 (STM)和奇偶校验 (PC) 任务已通过使用虚拟节点成功执行。
从单个 FeFET 的漏极电流的时间响应中提取。在这份报告的语音识别实验中,它们达到了高于 95.9% 的准确率。

量子计算
“可扩展的 1.4μW 低温CMOS SP4T 多路复用器,在 10mK下工作,实现高保真超导量子比特测量”——KU Leuven(论文 JCS1-2)
鲁汶大学的研究人员报告了一种超低功耗低温 CMOS单极四掷(SP4T)射频多路复用器在10mK基温下的电性能。他们首次使用多路复用器对超导量子比特进行基准测试,获得了高于 35μs 的量子比特相干时间以及 99.93% 的平均单量子比特门保真度,超过了基于表面码的量子纠错所需的阈值。这项工作展示了超导量子比特在基础温度下与超低功耗低温 CMOS 器件的可操作性,为先进的共集成方案铺平了道路。

存内计算(1)
“基于 8 位 20.7 TOPS/W 多级单元 ReRAM 的计算引擎”——密歇根大学(论文 JFS4-1)
密歇根大学的研究人员与应用材料公司合作报告称,具有多级单元电阻 RAM (ReRAM) 的内存模拟计算有望为机器学习和科学计算提供高密度和高效的计算。作者展示了一个 SoC 原型,该原型由四个基于 ReRAM 的独立内存计算块和一个 RISC-V 主机组成。使用128 MNIST数据集测得的原始和归一化峰值效率分别为20.7和662 TOPS/W,报告的计算密度为8.4 TOPS/mm2,分类准确率为96.8%

存内计算(2)
“一个40nm 模拟输入无 ADC 内存计算 RRAM 宏,其中子阵列之间具有脉宽调制”——佐治亚理工学院(论文 JFS4-2)
存内计算 (CIM) 已成为传统数字实现的有吸引力的替代方案,适用于广泛的乘法和累加 (MAC) 操作,适用于深度神经网络 (DNN) 应用。佐治亚理工学院提出了一种基于 RRAM 的无 ADC 内存计算(CIM) 宏电路,该宏由 1T1R 位单元组成。大多数CIM 宏电路采用 ADC,由于量化和噪声,ADC 会造成性能限制和精度损失。这项工作提出了一种无 ADC 存储器方案,该方案使用模拟信号处理和直接数字化,可将传感电路的面积开销减少0.5 倍,并将吞吐量提高 6.9 倍。所提出的方案还实现了11.6 倍的能效提升和 4.3 倍的计算效率提升。

技术亮点
先进的 CMOS技术(1)
“Intel 4 CMOS 技术采用先进的 FinFET 晶体管,针对高密度和高性能计算进行了优化”——英特尔(论文 T1-1)
摩尔定律继续快速发展:英特尔推出了一种新的先进CMOS FinFET 技术Intel 4,该技术通过提供 2 倍的高性能逻辑库面积缩放和Intel 7 的等功率性能增益超过 20% 来扩展摩尔定律。高性能库提供 50nm 栅极间距、30nm 鳍片间距和 30nm 最小金属间距。
该节点为 N/PMOS 提供 8VT (4NVT + 4PVT),范围为 190mV/180mV,使设计人员能够在功率和速度要求之间进行选择。EUV 光刻技术广泛用于简化工艺流程并提高产量。互连堆栈具有 16 个金属层,在关键的较低层具有增强的铜冶金,以提供改进的电迁移和更低的线路电阻。

先进的 CMOS技术(2)
“通过使用埋入式电源轨进行路由的晶圆两侧连接的可扩展 FinFET” – imec(论文 T1-2)
近年来,imec开发了埋入式电源轨(BPR)技术,将电源轨推到晶体管下方,具有降低IR压降和增加布线密度的双重好处,因为信号路由和电源路由不再有布线冲突。在这里,imec 报告了具有新颖路由方案的缩放 finFET,该方案可通过 BPR 从晶圆两侧进行电源连接。在通过优化的预清洁同时保持良好的接触界面的单个金属化步骤中执行通孔图案化后的正面与 p/n S/D-epi 和 BPR 的接触。
在晶圆翻转、键合和极薄化之后,高度缩放的 323nm 深纳米硅通孔 (nTSV) 着陆在 BPR 上,具有严格的覆盖控制和不变的 BPR 电阻。通过将供电网络移至背面,它提供了更少的动态和静态 IR 压降,该动态和静态 IR 压降是根据 2nm 设计规则为低功耗 64 位CPU 生成的片上功率热图预测的。P/NMOS表现出相似甚至更胜一筹,添加背面处理和额外退火后的 ION-IOFF 以提高 VT 恢复、迁移率和 BTI。

MRAM技术
“具有双自旋扭矩磁隧道结的可靠亚纳秒MRAM”——IBM(论文 T1-4)
自旋扭矩转移磁阻随机存取存储器 (STT-MRAM) 技术已显示出比闪存或 SRAM 的能量改进的地方,并且现在已进入量产阶段。
然而,STT-MRAM 位单元器件的可靠性和速度仍然是需要改进的因素。在本文中,IBM 通过使用双自旋扭矩磁隧道结 (DS-MTJ) 在两个终端 STT-MRAM 器件中展示了亚纳秒切换的两种改进。通过 ≤250 ps 的写入脉冲和在 -40°C 至 85°C 的温度范围内的紧密分布,可实现写入操作中的更低的错误率。为了建立可靠性,在 1E10 次写入周期后并没有出现性能下降。将此双端 DS-MTJ STT-MRAM 器件与最近发布的三端自旋轨道扭矩 (SOT) MRAM 器件进行比较,结果表明,开关电流密度降低了 10 倍,同类功耗降低了 3-10 倍。

DRAM技术
“垂直环沟道 (CAA) IGZO FET 小于 50nm CD、读取电流高达 32.8μA/μm (Vth +1V)、表现良好的热稳定性 120°C 、适用于低延迟、高密度2T0C 3D DRAM” – 华为(论文 T2-3)
华为首次报道了高性能DRAM的发展情况。他们展示了一个垂直环沟道 (CAA) IGZO FET,可按比例缩小到小于 50×50nm2 的有源面积。凭借优化的 IGZO 厚度 (~3nm) 和高 K电介质 (HfOx),在通道长度为 55nm 和临界值为50nm的 IGZO CAA FET 中,在 Vth +1V 时实现了 32.8μA/μm 的高电流密度和 92mV/dec 的亚阈值摆幅。温度变化测试和从 -40°C 到 120°C 的正偏压温度应力 (PBTS) 也证明了良好的热稳定性和可靠性。他们的研究结果表明,CAA IGZO FET 是未来超过 1α 节点的高密度、高性能 3D DRAM 的理想选择。

PCM技术
“基于Ge2Sb2Te5的低复位电流密度(~3 MA/cm2)和低电阻漂移(~0.002在105ºC)的超晶格相变存储器的首次演示”-斯坦福大学(论文T4-1)
相变存储器 (PCM) 为需要高密度存储的各种应用提供可编程和非易失性存储器。斯坦福大学展示了 PCM 存储器结构的进展,他们在其中研究了降低复位电流密度 (Jreset)和电阻漂移系数 (v) 的超晶格 PCM (SL-PCM) 异质结构。然而,他们尚未与众所周知的相变材料 Ge2Sb2Te5 (GST) 进行研究,超晶格界面和混合层的影响也仍然未知。在这里,首次使用基于 GST/Sb2Te3 的超晶格,它们在蘑菇形PCM 中同时实现 Jreset ≈ 3-4 MA/cm2 和7 个电阻状态 (v ≈ 0.002),底部电极直径低至 110nm。即使在 106 次循环和高温(105ºC) 后,低 复位电流密度和电阻漂移系数也分别保持不变。他们还发现超晶格 PCM中的复位电流密度和电阻漂移系数都随着超晶格接口数量的增加而减少。

图像传感器技术
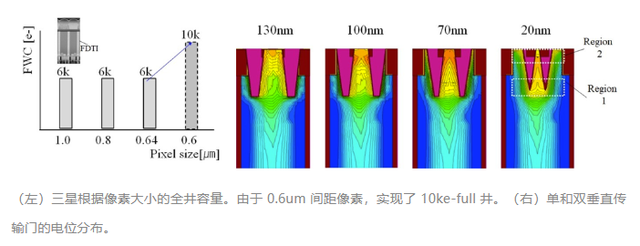
“采用双垂直传输门技术,用于高分辨率 CMOS 图像传感器的 0.6µm 小像素,全阱容量为 10000e-”——三星(论文 T8-4)
CMOS 像素竞赛仍在继续:三星使用双垂直传输门 (D-VTG) 技术开发了使用 0.6µm 像素的 200Mp 图像传感器原型,全阱容量 (FWC) 为 10000e。D-VTG 的 FWC 比单垂直传输门 (S-VTG) 增加了 60%,并通过增加 TG 电压的可控性来提高传输能力。它们还通过 VTG的间隙、深度和锥度斜率优化光电子传输。
有线和光学系统(1)
“面向无接收器系统的硅槽波导上的低电容超薄 InGaAs 膜光电探测器”——东京大学(论文 T15-4)
东京大学提出了一种由超薄 InGaAs 膜和硅槽波导组成的 Si/III-V 混合波导光电探测器,可实现低电容和高响应度,同时提高了高速数据中心和骨干链路的速度。硅槽波导中的强光约束增强了InGaAs膜中的光吸收。结果,他们成功地展示了 1A/W 的高响应度和 1.9fF 的足够小的电容,以实现无接收器 (TIA-less) 系统。

有线和光学系统(2)
“用于 2μm 波长光电集成电路的IV 类波导光电探测器和调制器在 300mm硅基板上的首次单片集成”——新加坡大学(论文 T15-2)
随着 1310 和 1550nm 单模光纤的发展接近理论极限,单一通路的 2μm 光谱窗口可解决通信容量紧缩问题。新加坡大学报告了第一次在 300 毫米硅衬底上单片集成IV类波导光电探测器 (PD) 和调制器,用于 2 μm波长应用,该应用具有硅 CMOS 与批量制造路线的兼容性。他们的波导 PD 和电吸收调制器 (EAM) 采用Ge0.92Sn0.08/Ge 多量子阱 (MQW) 作为有源层。他们利用 Ge 缓冲层作为 Ge-on-Si 波导和光栅耦合器,以便将光分别耦合到 EAM 和 PD 以进行直接调制和检测。其波导 PD 中的扩展耦合路径使具有相同吸收层的表面照明模式的光学响应度提高了 35 倍,在所有基于 GeSn 的 2μm PD 中具有最高的 525mA/W 响应度,具有 6GHz 的高 3dB 带宽。此外,他们首次展示了 2μm 完全集成收发器的可行性,并在同一硅衬底上成功运行 PD 和EAM。

先进材料
“晶圆级双辅助半自动干式转移和高性能单层 CVD WS2 晶体管的制造”——台积电(T1-5 论文)。
台积电报告了一种晶体管技术,该技术采用了一种新型的晶圆级半自动干式转移工艺,用于单层 (1L) CVD WS2,该工艺利用半金属 Bi 和二维半导体 WS2之间的弱耦合界面开发。单层 2D 半导体已显示出作为未来晶体管技术的最终尺寸沟道材料的巨大潜力,因为在原子级沟道厚度下保持良好的载流子迁移率以及在较短沟道长度 (LCH) 下更好的静电控制(LCH< 10nm) 比体半导体。这种新的单层转移方法在晶圆级进行了演示。此工艺中的 n-FET 在 VDS = 1V、接触电阻 <0.73kΩ∙μm 和 135nm 栅极长度时实现高达 250µA/µm 的高导通电流。

图像传感器技术
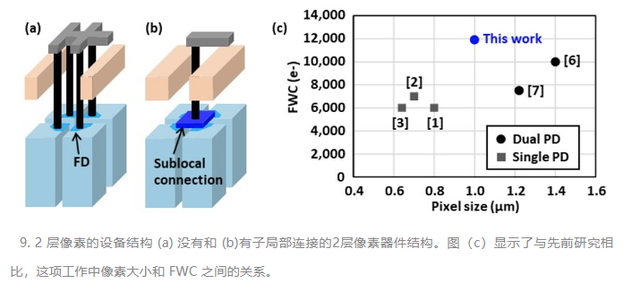
“具有氧化物基的全沟槽隔离的 2 层晶体管像素堆叠 CMOS 图像传感器,可实现大全阱容量和高量子效率”——索尼(论文 T1-3)
索尼展示了具有大全阱容量 (FWC) 和高量子效率 (QE) 的 2 层晶体管像素堆叠CMOS 图像传感器 (CIS) 的开发。光电二极管(PD)和像素晶体管通过三维顺序集成工艺在不同的硅层上制造,以增加 PD 数量,并引入连接多个浮动扩散的局部连接,以提高转换增益和随机噪声。首次使用氧化硅代替传统的多晶硅作为全沟槽隔离(FTIs)的嵌入材料,以防止光被FTIs吸收,530nm波长的QE提高了19%。他们展示了具有 12000e-FWC 的 1.0μm 双 PD CIS,以前只能通过更大的像素尺寸来实现。
电路亮点
机器学习
“一个 17-95.6 TOPS/W 深度学习推理加速器,具有每矢量缩放 4 位量化,适用于 5nm的变压器,”——英伟达(论文 C2-1)
用于自然语言处理或机器视觉的专用机器学习处理器正在成为边缘设备和数据中心的主力军。英伟达的研究人员展示了他们最新的 5nm CMOS 深度学习加速器原型。在加速器中,高精度计算和高功耗之间存在基本联系。另一方面,低准确率的计算往往会导致错误的分类和用户的不满。作者提出了一种新方法来应对这一挑战,通过采用数据相关向量缩放来执行 4b的算术任务,精度损失仅为 0.7%,功率效率为 95.6 TOPS/W。

英伟达提出的深度学习推理加速器框图,支持矢量缩放量化。
DRAM
“采用片上错误控制方案来增强 RAS 特性的 16GB 1024GB/s HBM3 DRAM ” - 三星(论文 C15-1)
三星展示了他们的第三代 10nm DRAM,其性能得到了改进,旨在提高系统可靠性、可用性和可维护性 (RAS),以用于汽车、工业和数据中心应用。他们在“高带宽存储器-3” (HBM3) DRAM 中实现了这一目标,通过专注于改进纠错,利用新的片上纠错(ECC) 方案来纠正 16 位字错误和 2 个单比特同时出错。在同一 DRAM 裸片上本地纠正每个错误,而不是访问 DRAM 堆栈中的其他裸片,从而改善延迟并将引脚数据速率从上一代的 5Gb/s/pin 提高到 8.0Gb/s/pin 和总内存每个内存立方体的带宽为 1024GB/s。这在 16GB DRAM 模块中得到了证明。
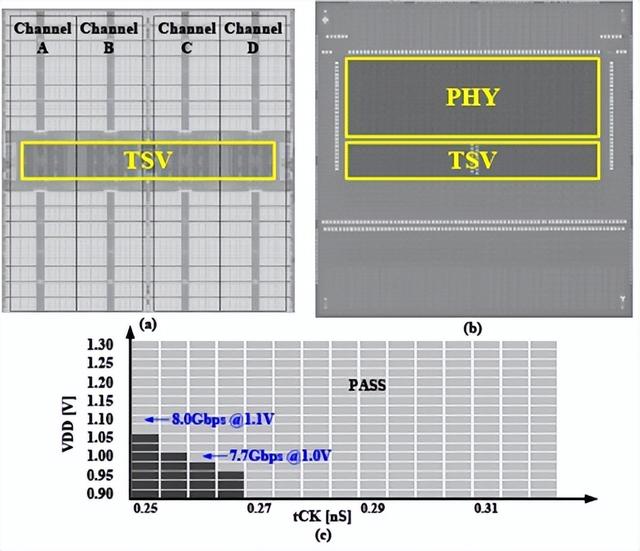
三星 HBM3 芯片的 (a) core-die 和 (b) buffer-die 的显微照片,(c) 用shmoo 测量的 tCK值。
SRAM
“基于Intel 4 CMOS 技术的高效能高带宽 6T SRAM 设计”——英特尔(论文 C24-1)
来自英特尔的作者展示了采用英特尔的 4nm 级 CMOS 技术的节能 SRAM。面向高吞吐量应用的节能计算的驱动力为片上存储器带来了更高容量和带宽的挑战。传统的 6T SRAM 满足低面积要求,而 8T 位单元提供较低的动态功率,但两者都不能满足。本文介绍了一种优化的 6T SRAM 设计,其位单元面积为 0.03µm2,功耗与 8T 相似,动态功耗比传统 6T 设计降低 5.6 倍。

SRAM内存
“在 7nm SoC 中使用顺序访问模式协同优化 SRAM 电路,实现 AR 应用的58%的内存耗能降低” – Meta(论文 C24-3)
AR 应用要求具有边缘智能的传感器具有超低功耗。在本文中,Meta Reality Labs 团队描述了嵌入在原型肌电图 (EMG) 腕带中用于 AR 眼镜手势识别任务的 7nm SOC 中 SRAM 的低功耗设计。他们提出了特定的顺序操作,而不是随机访问,用于针对传感模式优化的存储器设计,其中电路操作的数量被最小化以进行连续的存储器读取和写入。与传统内存设计基准相比,该设计的读取功耗降低了 52%,写入功耗降低了 58%。

系统级封装电源管理
“具有封装嵌入式电感器的全集成稳压器,用于异构 3D-TSV 堆叠系统级封装,具有 22nm CMOS 有源硅中介层,具有自调整、数控导通时间不连续导通模式 (DCM) 操作”——英特尔(论文) C22-1)
英特尔报告了其先进的系统级封装 (SiP) 电源管理,在 22nm 有源硅中介层上提供了异构小芯片与 3D-TSV 堆叠系统级封装 (SiP) 设计的集成。作者将电感器嵌入封装基板中,与 3D-TSV 直接连接,以平铺形式直接连接到中介层芯片上的完全集成稳压器。单个瓦片的电源效率在 10mA – 300mA 范围内保持平稳,通过在相邻瓦片上选择性组合稳压器可实现高达1A 的功率效率。这为具有不同功率要求的各种计算、内存和通信小芯片提供了灵活且经济高效的集成。

英特尔的 10 片完全集成 DCM 稳压器测试设置,带有各种基于 TSV 的电感器,用于功率/效率/面积权衡。
数字处理器的电源管理
“用于动态电压缩放移动应用的具有高电流密度的 3nm GAAFET 模拟辅助数字 LDO”——三星(论文 C21-4)
具有许多处理内核的高级CMOS 节点中的移动 SoC 的计算需求正在增加,从而增加了电源管理的压力。三星的作者展示了他们的模拟辅助数字 LDO 解决方案,采用 3nm 栅极环绕 FET (GAAFET) 技术,提供高电流密度功率传输。该设计具有主动电源噪声消除和 CPU 内核的快速瞬态负载检测功能。。该设计可在 <1mA 至 1.4A 负载范围内实现精确调节,并且在 1ns 内实现 1A 动态负载的电源压降仅为 38mV。

三星提出的用于移动 SoC应用的混合 LDO 结构。
有线收发器
“用于 200+Gb/s 串行链路的 4nm FinFET CMOS 中基于 72GS/s、8 位 DAC 的有线发送器”——IBM 研究院,美国(论文 C3-2)
IBM 报告了一种用于超高速串行电气链路的发射器,可满足数据中心不断增加的网络带宽的需求。他们的方法基于具有72GS/s 操作和源串联终止 (SST) 拓扑的 8 位 DAC。以前基于 SST 设计的研究没有超过 56GBaud,而这项研究推到了 72GBaud。他们的 4nm FinFET CMOS IC 展示了 216Gb/s PAM8 和 212Gb/s QAM64 OFDM 操作,功耗为 288mW。

IBM 在(a) 144Gb/s PAM4 (b) 180Gb/s PAM6 和 (c) 216Gb/s PAM8 中使用 FFE8 测量的 72GS/s TX 眼图
5G收发器(1)
“超紧凑型双向 T/R 折叠式 25.8-39.2GHz 相控阵收发器前端,具有嵌入式 TX 功率检测/自校准路径,支持 64/256/512QAM 在 28/39GHz 频段,用于 65nm CMOS 技术中的 5G” -清华大学(论文 C11-4)
清华大学的研究人员展示了一种面积高效的 5G 双向发射器和接收器,可在 28-39GHz 的宽频率范围内兼容,以兼容全球采用的不同频段。基于宽带变压器的发射器和接收器引入了快速切换、衰减和移相技术来实现宽带波束成形。该作品支持 28-39GHz 的 64/256/512QAM,具有 19.2dB RX 增益和 >12.8dBm TX 功率。他们的面积比之前的工作减少了 25% 以上。

5G收发器(2)
“一种 39GHz CMOS 双向 Doherty 相控阵波束形成器,使用 Shared-LUT DPD 和用于 5G 基站的元件间失配补偿技术”——东京工业大学(论文 C11-2)
东京工业大学报告了一种基于相控阵波束形成器的 5G 收发器,该波束形成器采用Doherty 低噪声功率放大器。他们研究了数字和模拟校正的改进,以提高单个天线上 TX 功率输出的均匀性。他们提出的方法对每个天线使用共享数字校正以及单独的相位和增益校正,将发射误差矢量幅度 (EVM) 提高了 9.1%,将发射到接收的 EVM 提高了 11.8%。它们在64 QAM 调制下每秒最多显示 3.5G 符号,并且该芯片还支持 21-Gb/s 单载波数据流。

东京工业大学的 39-GHz 双向 Doherty 相控阵波束形成器,具有元件间失配补偿。
成像和激光雷达
“1200x84像素30fps 64cc固态激光雷达RX,带HV/LV晶体管混合有源抑制SPAD阵列和背景数字PT补偿”——东芝(论文 C9-2)
最近,固态超大规模集成电路接收器和紧凑型发射器推动了激光雷达的尺寸和成本降低。东芝展示了一款基于 CMOS-SPAD 的激光雷达接收器,该接收器嵌入在手掌大小的 64cc 体积系统中。1200x84 传感器嵌入了优化的有源抑制 SPAD 像素,具有深沟槽绝缘 (DTI)。一代高SPAD 的工作电压会增加许多片外组件的成本:这项工作嵌入了片上数字背景低压控制回路,以补偿 SPAD 工艺和温度温度漂移,从而减少系统材料清单。LIDAR 系统将 CMOS接收器与微型扫描镜、28 通道 ADC 和 FPGA 相结合,它在高达 90ºC 的系统温度下,在 30FPS 的 110kLux 明亮环境光下演示室外 3D 点云生成。

(a) 东芝手掌大小的概念验证 LiDAR 及其框图。(b) 25°C 和 (c) 90°C 时的 3D 点云数据,建议的 DSCC 关闭,和 (d) DSCC 打开。
成像和激光雷达
“用于在高环境光条件下进行远程 3D 深度测量的混合间接 ToF图像传感器” – Toppan(论文 C5-2)
用于 3D 深度相机和激光雷达的高分辨率间接飞行时间 (ToF) 图像传感器通常会权衡距离范围或精度。Toppan公司与 Brookman Technology公司 和静冈大学的研究人员合作,提出了一种用于间接 ToF的新时序方案,打破了这种权衡,实现了长距离和高精度。该传感器技术适用于包括户外使用在内的广泛应用,因此他们提出了一种干扰抑制技术,允许多个摄像头同时在同一视场中工作。他们展示了 VGA 传感器中的技术,可实现 30m 范围的成像,同时在高达 100Lux 的环境光下保持 <15cm 的精度。

图 5. Toppan 的混合 TOF:白天(100k lux)和晚上(< 1 lux)1-20 m 范围内的室外深度图。
模数转换器
“在 4nm CMOS 中具有自举采样器和 AB 类缓冲器的 8 位 56GS/s 64x 时间交错ADC”——IBM 研究院,瑞士(论文 C19-1)
瑞士 IBM Research 报告了采用先进 4nm CMOS 的 56GS/s ADC,分辨率为 8b。用于高速串行链路的基于ADC的现代接收机依赖于时间交织,以达到112Gb/s及以上的所需速度。这项工作将 64 个 ADC 通道与用于通道间偏移、增益和偏斜校正的模拟前景校准交错。有一种新型的 AB 类输入缓冲器和自举跟踪保持采样器,它不需要高电源电压,可在与 4nm 技术节点兼容的 0.8V 单一低电源电压下运行,但仍保持 0.8V 峰峰值输入摆幅。该设计在大于 27GHz 带宽的 47fF/阶跃能量效率下实现了符合最新技术水平的性能。

IBM 采用 4nm CMOS 技术制造的 56 GS/s 8 位异步 SAR ADC 的芯片显微照片和布局细节。16x4 交错式 ADC 在一阶交错器中使用了一种新型的bootstrapping技术和一个 AB 类跟随器。



















评论