基于中国人群的基因组研究项目(WBBC)
来源:小桔灯网
作者:动力彩虹
了解人类基因组的结构是实现精准医疗的基本途径。在过去十年中,在解开复杂性状/疾病的遗传基础和人类进化史方面取得了巨大进展。对具有不同祖先的全球人群进行深入分析,可以提高对基因组变异与人类疾病之间关系的理解。然而,基因组研究在全球人口中存在着巨大的不平衡,欧洲血统的个体约占所有全基因组关联研究参与者的79%。同样,大部分全基因组测序(WGS)工作主要针对欧洲人群,如荷兰、英国和冰岛人群。即使在更大的基因组项目中,如由来自80多个不同研究的约155k名参与者组成的TOPMed(Trans-Omics for Precision Medicine)项目,也只有9%的样本是亚洲人后裔。因此,需要大规模的基因组数据来了解亚洲人群的遗传基础。最近,一些研究对包括日本人、韩国人和中国人在内的亚洲人群进行了排序和分析。新加坡SG10K试点项目报告了4810份全基因组测序样本,包括903名马来人、1127名印度人和2780名中国人,GenomeAsia 100K项目的试点研究提供了来自亚洲不同国家1267名个体的数据集。
尽管做出了上述努力,但中国人口在人类基因研究中的代表性仍然不足。中国作为人口最多的国家,是一个多民族国家,其中汉族占人口的90%。全国共有34个行政区划,包括省、市、特别行政区。研究团队之前的研究表明,即使有包含64976个人类单倍型的单倍型参考panel,中国人口的基因型填充也无法达到最高精度,仍然需要一个特定于人口的参考panel。对中国人口的遗传研究有可能使约20%的世界人口受益,并与世界其他地区进行比较。
近日,来自中国的研究团队在杂志Nature communications上发表了一篇题为“Genomic analyses of 10,376 individuals in the Westlake BioBank for Chinese (WBBC) pilot project”的文章。研究团队启动了中国西湖生物银行(WBBC)项目,以在大规模队列中描述基因组变异和群体结构,收集约100000个具有深层表型的样本。本文描述了中国34个行政区中的29个行政区10376个样本的WBBC试点项目的基因组发现。研究团队提供了一个基于中国人群的参考panel,可以显著改善中国人口的基因型填充性能,尤其是对于低频和罕见变异。通过分析WGS数据,研究团队发现SNX29、DNAH1和WDR1基因中存在选择特征,酒精代谢基因的衍生等位基因(ADH1A和ADH1B)大约出现在7000年前,在4000年前的东亚更为常见。遗传证据支持秦岭-淮河线和南岭山脉的相应地理边界,这将汉族划分为不同亚群,同时,研究团队发现北汉族比南汉族更同质。

图片来源:Nature Communications
主要内容
WBBC试点数据集和基因变体。
WBBC试点项目从中华人民共和国34个行政区划中的29个行政区划中抽取了10376人(图a)。研究团队在NovaSeq 6000平台上对4535人进行了WGS。在去除污染和重复样本后,保留了4480个人进行下游分析和统计。平均测序覆盖率为13.9×,覆盖99.77%的基因组。此外,6025名个体通过高密度Infinium Asian Screening Array(ASA)进行了基因分型,其中184名个体也进行了全基因组测序。 研究团队从10396万个原始变异体中筛选出81498995个变异体,包括74118191个单核苷酸变异体(SNV)和7380804个插入和缺失(INDEL)。将WBBC中确定的变体与其他现有数据库进行比较,有45696726个变体在1000基因组计划(1KG)、gnomAD 或UK10K 中不存在(图c),其中绝大多数为罕见变异。
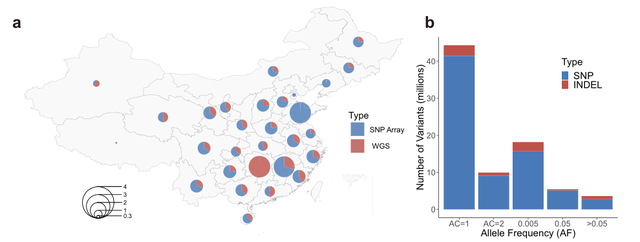
WBBC中样本统计数据。
图片来源:Nature Communications
变体注释和个体基因组。
为了描述这些变体的生物学特征,研究团队使用ANNOVAR工具对4480名个体的所有变体进行了注释。对于未在dbSNPBuild151中的变异,内含子区和基因间区的变异分别占38.31%和51.33%。只有0.98%的变体位于编码和剪接区域(图d)。错义变异体占编码区和剪接区变异体的54.22%,剪接变异体占变异体的29.69%(图e)。
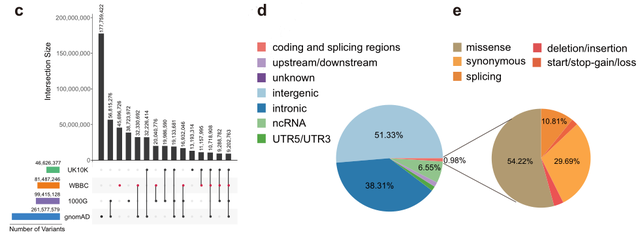
WBBC中变体的统计数据。
图片来源:Nature Communications
基因组单态密度评分分析。
单态密度评分(SDS)可用于推断最近的等位基因频率变化。研究团队试图通过基于4334名全基因组测序结果推断中国汉族人群SNV的最新等位基因频率变化。结果显示在染色体16p上的SNX29基因(图a)中发现了一个重要的选择标记,该基因编码sorting nexin-29蛋白,并在肾脏、淋巴结、卵巢和甲状腺组织中广泛表达。SNX29基因上30多个SNP表现出强烈的选择特征,这表明该基因组区域的选择显著富集。研究团队还确定了其他两个潜在选择信号,3号染色体上DNAH1和在4号染色体上WDR1(图a)。DNAH1基因的多态性显示出与中国男性不育的潜在关联,而WDR1基因的变异是中国人群痛风发生的危险因素。研究团队还确认了其他几个重要自然选择信号,酒精脱氢酶(ADH)基因簇,主要组织相容性复合体(MHC)区域和ALDH2(图a)。这三个选择特征区域也在日本人群中被发现。酒精代谢酶,如ADH基因(包括ADH1A、ADH1B、ADH4、ADH5和ADH6)和乙醛脱氢酶(ALDH2)基因,对酒精代谢途径和随后的酒精中毒保护作用有着有效的影响,这强烈表明了不同种族特定的酒精消费模式。
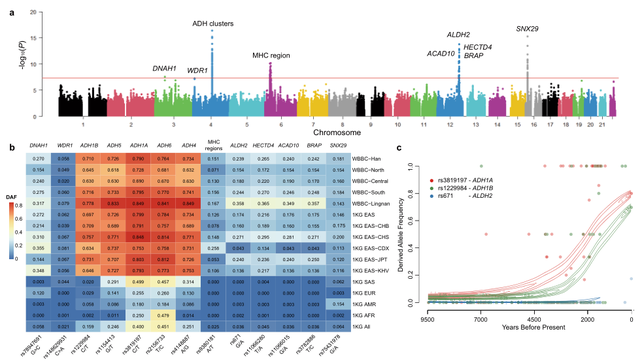
SDS分析中国汉族人群全基因组近期选择特征。
图片来源:Nature Communications
中国人口基因型填充参考panel。
研究团队评估了中国人群中WBBC、1KG、CONVERGE和两个组合panel(WBBC+EAS和WBBC+1KG)的基因型填充准确性。结果表明,WBBC的中国样本数几乎是1KG项目的15倍,大大改善了低频和罕见变异的填充(图a)。两个组合panel,WBBC+EAS和WBBC+1KG,具有最高的R平方(Rsq)和变体数量,其次是WBBC,1KG和CONVERGE(图a)。总体而言,研究团队采用Rsq和NR等位基因一致率来衡量五个panel的基因型填充准确性。结果证明了WBBC作为中国人口基因型填充参考panel的优越性。与1KG和CONVERGE相比,WBBC大大提高了精度,尤其是对于罕见和低频变异。
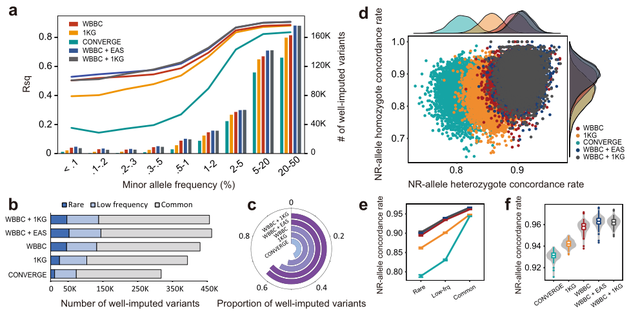
中国汉族人口五种panel的基因型填充性能。
图片来源:Nature Communications
遗传证据支持秦岭淮河线和南岭山脉。
为了探索中国人口结构,研究团队对中国34个行政区中29个行政区的2056名汉族个体和205名少数民族个体进行了PCA分析(图a)。汉族群体的遗传差异与秦岭淮河线和南岭山脉的地理边界相对应。根据PCA分析和中国传统地理边界,汉族可分为四个亚组:北方汉族(甘肃、河北、黑龙江、河南、内蒙古、吉林、辽宁、宁夏、青海、陕西、山东、山西和天津),中部汉族(安徽和江苏),南方汉族(重庆、福建、贵州、湖北、湖南、江西、四川、云南和浙江)和岭南汉族(广西、广东和海南)。
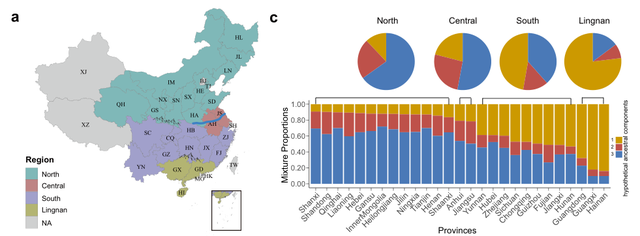
汉族人群的PCA分析。
图片来源:Nature Communications
中国汉族人口四个亚区的人口结构和人口历史。
Weir–Cockerham F ST是一种基于等位基因频率的指标,用于衡量由于遗传结构导致的群体分化。结果表明27个行政区划主要分为三组,并与地理位置相关。安徽省和江苏省是中国的中部地区,与北部省份聚集在一起,表明亲缘关系更为密切。其他两个群体,南方和岭南,与我们指定的地区保持一致。此外,等级分支表明,南方和北方之间的种群分化小于南方和岭南之间的种群分化。地理上最偏远的两个地区,北部和岭南,有最大的人口分化(图a)。接下来,研究团队做了IBD分析,IBD分析是一种基于单倍型的方法,用于揭示遗传结构和调查群体的共同祖先。IBD分析结果与FST聚类结果类似。
研究团队进一步研究了北方汉族和南方汉族遗传结构的同质性程度。结果表明,与南方汉族人相比,北方汉族人的群体分化和遗传漂移较小,并且彼此共享更多的IBD片段。这些结果表明,北方汉族人的遗传结构明显同质于南方汉族人。
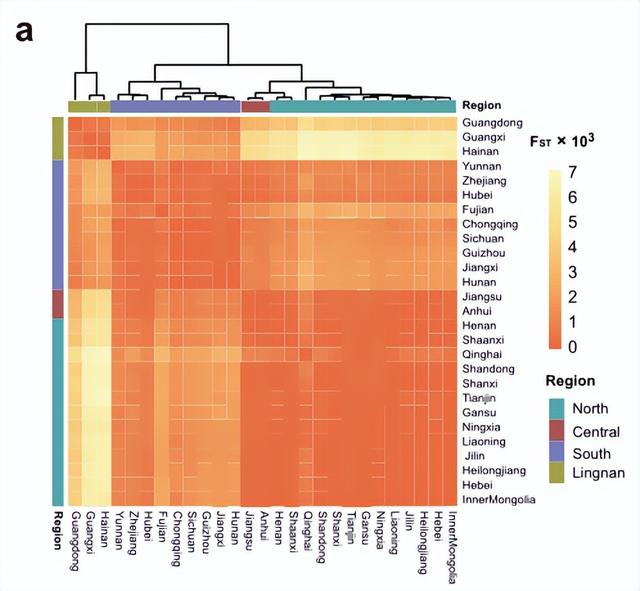
中国汉族人群的FST分析。
图片来源:Nature Communications
汉族人口四个亚区的近期正向选择特征
研究团队采用综合单倍型评分(iHS)检验来确定北部、中南部和岭南汉族人群中最近出现的正向选择性的自然特征。对前候选基因进行了GO分析和KEGG路径分析。GO分析的结果表明,四个亚区中乙醇代谢过程和乙醇氧化的正选择基因显著富集(补充表9),这与中国汉族人群全基因组SDS分析的选择特征相一致。研究团队还观察到,在南部和岭南汉族人群中,角质形成细胞分化、表皮细胞分化和皮肤发育(CTSL、COL7A1、PKP3、SEC24B、SLITRK6、WNT10A、KRT10、KRT12、KRT20和KRT23)的有趣富集,这在北部和中部汉族人群中并不存在。KEGG分析发现,汉族人群中有23条通路正在富集,包括酪氨酸代谢、视黄醇代谢和脂肪酸降解在四个亚区中被发现。
总结
研究团队启动了中国西湖生物银行(WBBC)试点项目,共有4535名全基因组测序(WGS)个体和5841名高密度基因型个体,并鉴定了8150万个SNP和INDEL。这项研究提供了一个特定人群的参考panel,可以显著改善中国人口的基因型填充性能,尤其是对于低频和罕见变异。研究团队描述了中国人群的大规模基因组变异,并为秦岭淮河线和南岭山脉的地理边界提供了全面的遗传学证据,将汉族人群分为四个亚组,这可能有助于中国人群关联研究的病例对照设计。同时,本研究还为东亚样本创建了一个用户友好的网站和高性能基因型插补服务器。在线资源对于单基因疾病的基因组变异筛选以及随后与群体遗传学领域复杂性状的关联具有重要意义。





















评论