一文了解存算一体芯片

来源:来自「智前沿」,作者:王绍迪,谢谢。
摩尔定律趋于失效,应运而生的新型计算架构如存算一体芯片,受到广泛关注。智前沿特刊发AI芯片企业知存科技CEO王绍迪文章,对端侧智能存算一体芯片做全面回顾和展望。
端侧智能存算一体芯片概述
摘要:现代电子设备朝着智能化、轻量化、便携化快速发展,但是智能大数据处理挑战与冯诺依曼计算架构瓶颈成为当前电子信息领域的关键矛盾之一;同时,器件尺寸微缩(摩尔定律失效)带来的功耗与可靠性问题进一步加剧了该矛盾的快速恶化。近年来以数据为中心的新型计算架构,例如存算一体芯片技术,受到人们的广泛关注,尤其在端侧智能场景。但是,基于端侧设备在资源、时延、成本、功耗等诸多因素的考虑,业界对存算一体芯片提出了苛刻的要求。因此,存算一体介质与计算范式尤为重要。同时,器件-芯片-算法-应用跨层协同对存算一体芯片的产业化应用与生态构建非常关键。本文对端侧智能存算一体芯片的需求、现状、主流方向、应用前景与挑战等做一个简单的概述。我们有理由相信,在高能效低成本智能存算一体芯片的硬件支撑下,随着5G通信与物联网(IoT)技术的成熟,智能万物互联(AIoT)时代即将来临。
自第四次信息革命以来,现代电子设备朝着智能化、轻量化、便携化快速发展。尤其近年来,随着以深度学习神经网络为代表的人工智能算法的深入研究与普及,智能电子设备与相关应用场景已随处可见,例如人脸识别、语音识别、智能家居、安防监控、无人驾驶等。同时,随着5G通信与物联网(IoT)技术的成熟,可以预见,智能万物互联(AIoT)时代即将来临。如图1所示,在未来AIoT场景中,设备将主要分为三类:云端、边缘端与终端[1],其中边缘终端设备将呈现爆发式增长。众所周知,人工智能的三大要素是算力、数据与算法。互联网与5G通信的应用普及解决了大数据问题,深度学习神经网络的快速发展解决了算法问题,英伟达GPU/谷歌TPU等高性能硬件的大规模产业化解决了云端算力问题。但是,资源受限的边缘终端设备的算力问题目前仍然是缺失的一环,且因其对时延、功耗、成本、安全性等特殊要求(尤其考虑细分场景的特殊需求),将成为AIoT大规模产业化应用的核心关键。因此,在通往AIoT的道路上,需要解决的核心挑战是高能效、低成本、长待机的端侧智能芯片。
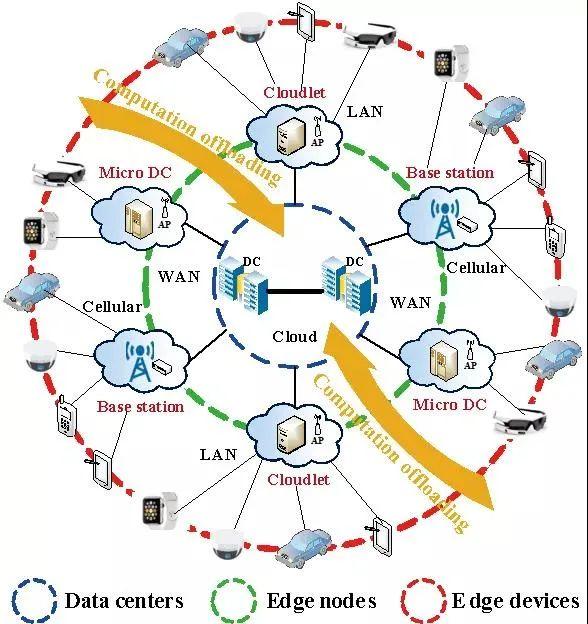
图1、未来AIoT场景示意图,包括三层:运算数据中心,边缘端与终端[1]。
冯诺依曼计算架构瓶颈与大数据智能处理挑战
随着大数据、物联网、人工智能等应用的快速兴起,数据以爆发式的速度快速增长。相关研究报告指出,全世界每天产生的数据量约为字节,且该体量仍然以每40个月翻倍的速度在持续增长[2]。海量数据的高效存储、迁移与处理成为当前电子信息领域的重大挑战之一。但是,受限于经典的冯诺依曼计算架构[3,4],数据存储与处理是分离的,存储器与处理器之间通过数据总线进行数据传输, 如图2(a)所示。在面向大数据分析等应用场景中,这种计算架构已成为高性能低功耗计算系统的主要瓶颈之一。一方面,数据总线的有限带宽严重制约了处理器的性能与效率,同时,存储器与处理器之间存在严重性能不匹配问题,如图2(b)所示。不管处理器运行的再快、性能再好,数据依然存储在存储器里,每次执行运算时,需要把数据从存储器经过数据总线搬移到处理器当中,数据处理完之后再搬回到存储器当中。这就好比一个沙漏,沙漏两端分别代表存储器和处理器,沙子代表数据,连接沙漏两端的狭窄通道代表数据总线。因此存储器带宽在很大程度上限制了处理器的性能发挥,这称为存储墙挑战。与此同时,摩尔定律正逐渐失效,依靠器件尺寸微缩来继续提高芯片性能的技术路径在功耗与可靠性方面都面临巨大挑战。因此,传统冯诺依曼计算架构难以满足智能大数据应用场景快、准、智的响应需求。另一方面,数据在存储器与处理器之间的频繁迁移带来严重的传输功耗问题,称为功耗墙挑战。英伟达的研究报告指出,数据迁移所需的功耗甚至远大于实际数据处理的功耗。例如,相关研究报告指出,在22纳米工艺节点下,一比特浮点运算所需要的数据传输功耗是数据处理功耗的约200倍[5]。在电子信息领域,存储墙与功耗墙问题并称为冯诺依曼计算架构瓶颈。因此,智能大数据处理的挑战实质是由硬件设施的处理能力与所处理问题的数据规模之间的矛盾引起的。构建高效的硬件设施与计算架构,尤其是在资源受限的AIoT边缘终端设备,来应对智能大数据应用背景下的冯诺依曼计算架构瓶颈具有重要的科学意义与应用前景。
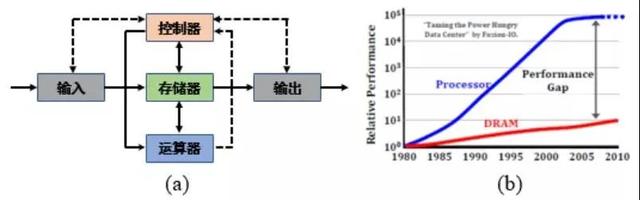
图2 (a)冯诺依曼计算架构示意图;(b)存储器与处理器之间的性能鸿沟。
为了打破冯诺依曼计算架构瓶颈,降低数据搬移带来的开销,一种最直接的做法是增加数据总线带宽或者时钟频率,但必将带来更大的功耗与硬件成本开销,且其扩展性也严重受限。目前业界采用的主流方案是通过高速接口、光互联、3D堆叠、增加片上缓存等方式来实现高速高带宽数据通信,同时使存储器尽量靠近处理器,减小数据传输的距离。光互联技术还处于研发中试阶段,而3D堆叠技术与增加片上缓存等方法已经广泛用于实际产品当中。国内外很多高效与企业都在研发与应用这种技术,如谷歌、英特尔、AMD、英伟达、寒武纪科技等。例如,利用3D堆叠技术,在处理器芯片上集成大容量内存,可以把数据带宽从几十GB/s提升到几百GB/s;基于3D堆叠DRAM技术,IBM于2015年发布了一款面向百亿亿次超级计算系统[6];国内百度昆仑与英国Graphcore公司在芯片产品上集成了200MB-400MB的片上缓存,来提高性能。值得注意的是,上述方案不可避免地会带来功耗与成本开销,难以应用于边缘终端能耗与成本均受限的AIoT设备,且其并没有改变数据存储与数据处理分离的问题,因此只能在一定程度上缓解,但是并不能从根本上解决冯诺依曼计算架构瓶颈。
存算一体基本原理与国内外发展现状
存算一体芯片技术,旨在把传统以计算为中心的架构转变为以数据为中心的架构,其直接利用存储器进行数据处理,从而把数据存储与计算融合在同一个芯片当中,可以彻底消除冯诺依曼计算架构瓶颈,特别适用于深度学习神经网络这种大数据量大规模并行的应用场景。需要说明的是,目前在学术界和产业界有不少类似的英文概念,例如Computing-in-Memory、In-Memory-Computing、Logic-in-Memory、In-Memory-Processing、Processing-in-Memory等,而且不同研究领域(器件、电路、体系架构、数据库软件等)的称呼也不统一,相应的中文翻译也不尽相同,例如内存处理、存内处理、内存计算、存算融合、存内计算、存算一体等。此外,在广义上,近存计算也被归纳为存算一体的技术路径之一。
存算一体的基本概念最早可以追溯到上个世纪七十年代,斯坦福研究所的Kautz等人最早于1969年就提出了存算一体计算机的概念[7,8]。后续相当多的研究工作在芯片电路、计算架构、操作系统、系统应用等层面展开。例如,加州大学伯克利分校的Patterson等人成功把处理器集成在DRAM内存芯片当中,实现一种智能存算一体计算架构[9]。但是受限于芯片设计复杂度与制造成本问题,以及缺少杀手级大数据应用进行驱动,早期的存算一体仅仅停留在研究阶段,并未得到实际应用。近年来,随着数据量不断增大以及内存芯片技术的提高,存算一体的概念重新得到人们的关注,并开始应用于商业级DRAM主存当中。尤其在2015年左右,随着物联网、人工智能等大数据应用的兴起,技术得到国内外学术界与产业界的广泛研究与应用。在2017年微处理器顶级年会(Micro 2017)上,包括英伟达、英特尔、微软、三星、苏黎世联邦理工学院与加州大学圣塔芭芭拉分校等都推出了他们的存算一体系统原型[10-12]。
尤其是,近年来非易失性存储器技术,例如闪存(Flash)、忆阻器(阻变存储器 RRAM)、相变存储器(PCM)与自旋磁存储器(MRAM)等[13-17],为存算一体芯片的高效实施带来了新的曙光。这些非易失性存储器的电阻式存储原理可以提供固有的计算能力,因此可以在同一个物理单元地址同时集成数据存储与数据处理功能。此外,非易失性可以让数据直接存储在片上系统中,实现即时开机/关机,而不需要额外的片外存储器。惠普实验室的Williams教授团队在2010年就提出并验证利用忆阻器实现简单布尔逻辑功能[18]。随后,一大批相关研究工作不断涌现。2016年,美国加州大学圣塔芭芭拉分校(UCSB)的谢源教授团队提出利用RRAM构建基于存算一体架构的深度学习神经网络(简称为PRIME[19]),受到业界的广泛关注。测试结果表明,相比基于冯诺依曼计算架构的传统方案,PRIME可以实现功耗降低约20倍、速度提高约50倍[20]。这种方案可以高效地实现向量-矩阵乘法运算,在深度学习神经网络加速器领域具有巨大的应用前景。国际上杜克大学、普渡大学、斯坦福大学、马萨诸塞大学、新加坡南洋理工大学、惠普、英特尔、镁光等都开展了相关研究工作,并发布了相关测试芯片原型[21-24]。我国在这方面的研究也取得了一系列创新成果,如中科院微电子所刘明教授团队、北京大学黄如教授与康晋锋教授团队、清华大学杨华中教授与吴华强教授团队、中科院上海微系统所宋志棠教授团队、华中科技大学缪向水教授团队等等,都发布了相关器件/芯片原型,并通过图像/语音识别等应用进行了测试验证[25-27]。PCM具有与RRAM类似的多比特特性,可以基于类似的原理实现向量-矩阵乘法运算。对于MRAM而言,由于其二值存储物理特性,难以实现基于交叉点阵列的向量-矩阵乘法运算,因此基于MRAM的存算一体通常采用布尔逻辑的计算范式[28-30]。但由于技术/工艺的成熟度等问题,迄今基于相变存储器、阻变存储器与自旋存储器的存算一体芯片尚未实现产业化。与此同时,基于Nor Flash的存算一体芯片技术近期受到产业界的格外关注,自2016年UCSB发布第一个样片以来,多家初创企业在进行研发,例如美国的Mythic, Syntiant,国内的知存科技等,并受到国内外主流半导体企业与资本的产业投资,包括Lam Research、Applied Materials、Intel、Micron、ARM、Bosch、Amazon、Microsoft、Softbank、Walden、中芯国际等等。相比较而言,Nor Flash在技术/工艺成熟度与成本方面在端侧AIoT领域具有优势,三大公司均宣布在2019年末实现量产。
端侧智能应用特征与存算一体芯片需求
随着AIoT的快速发展,用户对时延、带宽、功耗、隐私/安全性等特殊应用需求,如图3(a)所示,驱动边缘端侧智能应用场景的爆发。首先,时延是用户体验最直观的感受,而且是某些应用场景的必需要求,例如自动驾驶、实时交互游戏、AR/VR等。考虑到实时产生的数据量、实际传输带宽以及端侧设备的能耗,不可能所有运算都依赖云端来完成。例如,根据英特尔的估计,每辆自动驾驶汽车每天产生的数据量高达400GB[1];再例如,每个高清安防监控摄像头每天产生的数据量高达40GB-200GB。如果所有车辆甚至所有摄像头产生的数据都发送到云端进行处理,那不仅仅是用户体验,即使对传输网络与云端设备都将是一个灾难。而且,通常边缘数据的半衰期都比较低,如此巨大的数据量,实际上真正有意义的数据可能非常少,所以并没有意义把全部数据发送到云端去处理。此外,同类设备产生的大部分数据通常具有极高的相同模式化特征,借助边缘端/终端有限的处理能力,即可以过滤掉大部分无用数据,从而大幅度提高用户体验与开销。增强用户体验的另一个参数是待机时间,这对便携式可穿戴设备尤为关键。例如,智能眼镜与耳机,至少要保证满负荷待机时间在一天以上。因此终端设备的功耗/能效是一个极大的挑战。其次,用户对隐私/安全性要求越来越高,并不愿意把数据送到云端处理,促使本地处理成为终端设备的必备能力。例如,随着语音识别、人脸识别应用的普及,越来越多的人开始关心隐私泄露的问题,即使智能家居已经普及,但很多用户选择关闭语音处理功能。最后,在无网环境场景下,边缘终端处理将成为必需。相应地,不同于云端芯片,对于端侧智能芯片,其对成本、功耗的要求最高,而对通用性、算力、速度的要求次之,如图3(b)所示。因此,依靠器件尺寸微缩来继续提高芯片性能的传统技术路径在功耗与成本方面都面临巨大挑战;而依赖器件与架构创新的技术路径越来越受重视。2018年,美国DARPA“电子复兴计划”明确提出不再依赖摩尔定律的等比例微缩道路,旨在寻求超越传统冯诺依曼计算架构的创新,利用新材料、新器件特性和集成技术,减少数据处理电路中移动数据的需求,研究新的计算拓扑架构用于数据存储与处理,带来计算性能的显著提高。业界普遍认为,存算一体芯片技术将为实现此目标提供可行的技术路径之一。
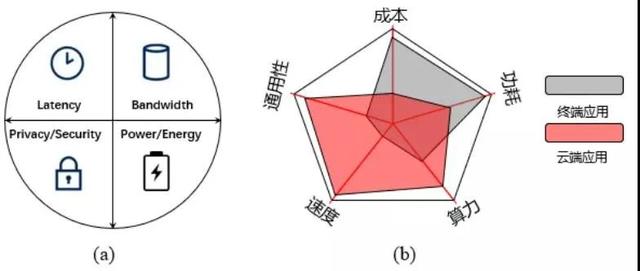
图3、(a)边缘端侧智能应用场景的需求特征;Adapted from Gartner, 2019;(b)云端与端侧智能芯片不同的性能需求。
存算一体芯片主流研究方向
根据存储器介质的不同,目前存算一体芯片的主流研发集中在传统易失性存储器,如SRAM、DRAM,以及非易失性存储器,如RRAM,PCM,MRAM与闪存等,其中比较成熟的是以SRAM和MRAM为代表的通用近存计算架构。值得注意的是,本章将主要讨论基于存算一体芯片的深度学习神经网络加速器实现。在此类应用中,95%以上的运算为向量矩阵乘法(MAC),因此存算一体主要用来加速这部分运算。
(1) 通用近存计算架构
如图4所示,这种方案通常采用同构众核的架构,每个存储计算核(MPU)包含计算引擎(Processing Engine, PE)、缓存(Cache)、控制(CTRL)与输入输出(Inout/Output, I/O)等,这里缓存可以是SRAM、MRAM或类似的高速随机存储器。各个MPU之间通过片上网络(Network-on-Chip, NoC)进行连接。每个MPU访问各自的缓存,可以实现高性能并行运算。典型案例包括英国Graphcore公司,其测试芯片集成了200-400MB的SRAM缓存以及美国Gyrfalcon Technology公司,其测试芯片集成了40MB 嵌入式MRAM缓存。
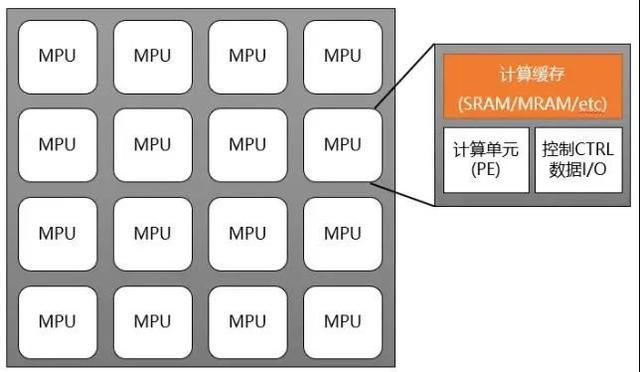
图4、基于高速缓存的通用近存计算架构。
(2) SRAM存算一体
由于SRAM是二值存储器,二值MAC运算等效于XNOR累加运算,可以用于二值神经网络运算。如图5(a)和图5(b)为两种典型设计方案,其核心思想网络权重存储于SRAM单元中,激励信号从额外字线给入,最终利用外围电路实现XNOR累加运算,结果通过计算器或模拟电流输出,具体实现可以参考[31,32]。这种方案的主要难点是实现大阵列运算的同时保证运算精度。
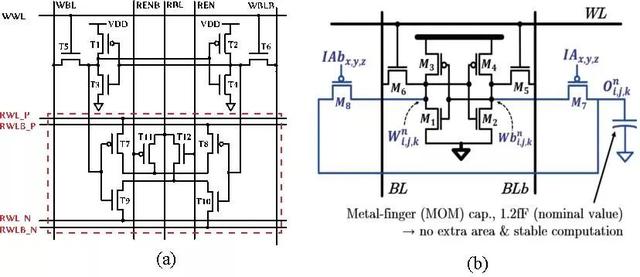
图5、SRAM存算一体单元设计;(a)12管设计[31];(b)8管设计[32]。
(3) DRAM存算一体
基于DRAM的存算一体设计主要利用DRAM单元之间的电荷共享机制[33,34]。如图6所示为一种典型实现方案[33],当多行单元同时被选通时,不同单元之间因为存储数据的不同会产生电荷交换共享,从而实现逻辑运算。这种方案的问题之一是计算操作对数据是破坏性的,即每次执行运算时,DRAM存储单元存储的数据会破坏,需要每次运算后进行刷新,带来较大的功耗问题;另一个难点是实现大阵列运算的同时保证运算精度。
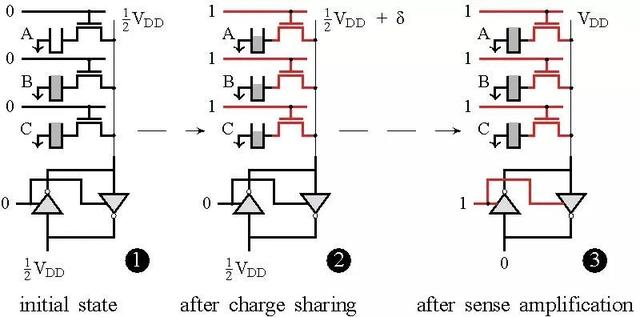
图6、基于DRAM的典型存算一体设计原理[33]。
(4) RRAM/PCM/Flash多值存算一体
基于RRAM/PCM/Flah的多值存算一体方案的基本原理是利用存储单元的多值特性,通过器件本征的物理电气行为(例如基尔霍夫定律与欧姆定律)来实现多值MAC运算[13,21-25],如图7所示。每个存储单元可以看作一个可变电导/电阻,用来存储网络权重,当在每一行施加电流/电压(激励)时,每一列即可得到MAC运算的电压/电流值。实际芯片中,根据不同存储介质的物理原理和操作方法的不同,具体实现方式会有差异。由于RRAM/PCM/Flash本身是非易失性存储器,可以直接存储网络权重,因此不需要片外存储器,减小芯片成本;同时,非易失性可以保证数据掉电不丢失,从而实现即时开机/关机操作,减小静态功耗,延长待机时间,非常适用于功耗受限的边缘终端设备。目前,基于RRAM/PCM的存算一体技术在学术界是非常热的一个研究方向,遗憾的是,因为RRAM/PCM成熟度等问题,目前尚未产业化,但未来具有非常大的潜力;基于Flash的存算一体技术相对较成熟,受到产业界广泛关注,预计于2019年末量产。
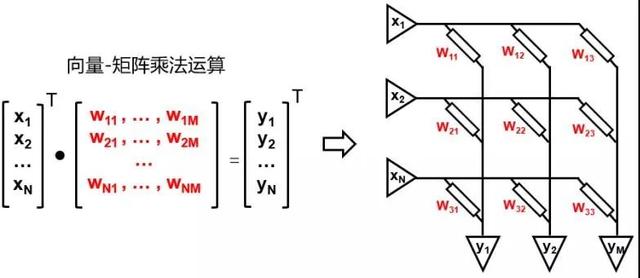
图7、基于RRAM/PCM/Flah的MAC运算基本原理[13]。
(5) RRAM/PCM/MRAM二值存算一体
基于RRAM/PCM/MRAM的二值存算一体主要有两种方案。第一种方案是利用辅助外围电路,跟上述SRAM存算一体类似,如图8(a)所示为一种典型的可重构存算一体实现方案[35],其可以在存储应用与存算一体应用之间进行切换。由于RRAM/PCM/MRAM非易失性电阻式存储原理,其具有不同的电路实现方式,具体参考[35-37]。第二种方案是直接利用存储单元实现布尔逻辑计算[28,38-40],如图8(b)所示,这种方案直接利用存储单元的输入输出操作进行逻辑运算,根据不同存储器存储单元的结构与操作方法不同,可以有不同的实现方式,具体可以参考[28,38-40]。
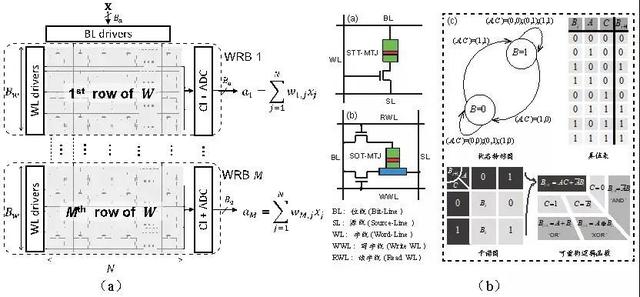
图8、基于RRAM/PCM/MRAM的存算一体基本原理;(a)利用外围电路方案[35];(b)利用存储单元方案[40]。
应用前景与挑战
存算一体芯片技术,尤其是非易失性存算一体芯片技术,因其高算力、低功耗、低成本等优势,未来在AIoT领域具有非常大的应用前景。存算一体芯片大规模产业化的挑战主要来自两方面:(1)技术层面;存算一体芯片涉及器件-芯片-算法-应用等多层次的跨层协同,如图9所示。例如,细分应用场景的不同性能需求决定了神经网络算法与芯片的设计,算法依赖神经网络框架、编译、驱动、映射等工具与芯片架构的协同,芯片架构又依赖器件、电路与代工厂工艺。这些对存算一体芯片的研发与制备都是相当大的一个挑战,尤其需要代工厂的支持。特别是基于新型存储介质的存算一体技术,器件物理原理、行为特性、集成工艺都不尽相同,需要跨层协同来实现性能(精度、功耗、时延等)与成本的最优。
(2)产业生态层面;作为一种新兴技术,想要得到大规模普及,离不开产业生态的建设,需要得到芯片厂商、软件工具厂商、应用集成厂商等的大力协同、研发、推广与应用,实现性能与场景结合与落地,尤其在面对传统芯片已经占据目前大部分已有应用场景的前提下,如何突破新市场、吸引新用户是快速产业化落地的关键。英伟达GPU的成功给了我们很好的启示与借鉴。一方面需要优化工具与服务,方便用户使用;另一方面需要尽量避免竞争,基于存算一体芯片的优势,开拓新应用、新场景、新市场,创造传统芯片无法覆盖的新型应用市场。
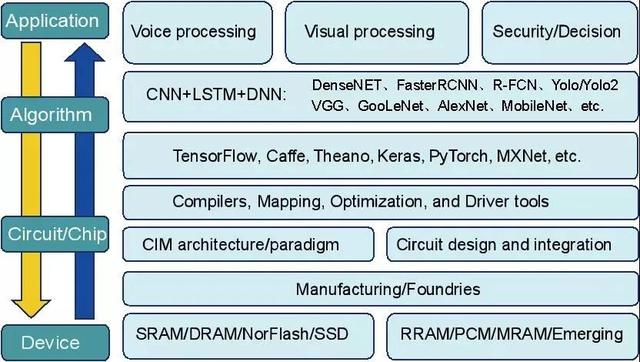
图9、存算一体器件-芯片-算法-应用跨层协同示意图。
参考文献
[1] L. Lin, X. Liao, H. Jin, and P. Li, “Computation Offloading Toward Edge Computing,” Proceedings of the IEEE (Early Access), Jul. 2019.
[2] C. L. Chen, and C. Zhang, “Data-intensive applications, challenges, techniques and technologies: a survey on Big Data,” Information Sciences, vol. 275, pp. 314-347, Aug. 2014.
[3] W. Wulf, and S. McKee, “Hitting the Memory Wall: Implications of the Obvious,” ACM Computer Architechture News, vol. 23, no. 1, pp. 20-24, Dec. 1994.
[4] M. Zidan, J. Strachan, and W. Lu, “The Future of Electronics Based on Memristive Systems,” Nature Electronics, vol. 1, no. 1, pp. 22-29, Jan. 2018.
[5] R. Alshahrani, “The Path to Exascale Computing,” in ACM/IEEE ICPDPTA., pp. 123-126, 2015.
[6] R. Nair, S. Antao, C. Bertolli, et al., “Active Memory Cube: A Processing-in-Memory Architecture for Exascale Systems,” IBM Journal of Research and Development, vol. 59, no. 2, pp. 17:1-17:14, Apr. 2015.
[7] W. Kautz, “Cellular Logic-in-Memory Arrays,” IEEE Transactions on Computers, vol. C-18, no. 8, pp. 719-727, Aug. 1969.
[8] H. Stone, “A Logic-in-Memory Computer,” IEEE Transactions on Computers, vol. C-19, no. 1, pp. 73-78, Jan. 1970.
[9] D. Patterson, T. Anderson, N. Cardwell, R. Fromm, K. Keeton, R. Thomas, and K. Yelick, “A Case for Intelligent RAM,” IEEE Micro, vol. 17, no. 2, pp. 34-44, Apr. 1997.
[10] S. Li, D. Niu, K. T. Malladi, B. Brennan, and Y. Xie, “DRISA: A DRAM-based Reconfigurable In-Situ Accelerator,” in IEEE/ACM International Symposium on Microarchitecture (MICRO), pp. 288-301, Apr. 2017.
[11] V. Seshadri, D. Lee, T. Mullins, H. Hassan, A. Boroumand, J. Kim, M. A. Kozuch, O. Mutlu, P. Gibbons, and T. Mowry, “Ambit: In-Memory Accelerator for Bulk Bitwise Operations Using Commodity DRAM Technology,” in IEEE/ACM International Symposium on Microarchitecture (MICRO), pp. 273-287, Oct. 2017.
[12] S. R. Agrawal, S. Idicula, A. Raghavan, E. Vlachos, V. Varadarajan, and E. Sedlar, “A Many-Core Architecture for In-Memory Data Processing,” in IEEE/ACM International Symposium on Microarchitecture (MICRO), pp. 245-258, Oct. 2017.
[13] X. Guo, F. Bayat, M. Bavandpour, M. Klachko, M. Mahmoodi, M. Prezioso, K. Likharev, and D. Strukov, “Fast, Energy-Efficient, Robust, and Reproducible Mixed-Signal Neuromorphic Classifier Based on Embedded NOR Flash Memory Technology,” in IEEE International Electron Devices Meeting (IEDM), pp. 6.5.1-6.5.4, Dec. 2017.
[14] H. Wong, and S. Salahuddin, “Memory Leads the Way to Better Computing,” Nature Nanotechnology, vol. 10, no. 3, pp. 191-194, Mar. 2015.
[15] L. Wang et al., “Voltage-Controlled Magnetic Tunnel Junctions for Processing-In-Memory Implementation,” IEEE Electron Device Letters, vol. 39, no. 3, pp. 440-443, March 2018.
[16] W. Kang, Y. Zhang, Z. Wang, J. O. Klein, C. Chappert, D. R. Ravolosona, G. Wang, Y. Zhang, and W. Zhao, “Spintronics, Emerging Ultra-Low Power Circuits and Systems Beyond MOS Technology,” ACM Journal on Emerging Technologies in Computing Systems (JETC), vol. 12, no. 2, pp. 1-42, Sep. 2015.
[17] A. Chen, “A Review of Emerging Non-Volatile Memory (NVM) Technologies and Applications,” Solid-State Electronics, vol. 125, pp. 25-38, Nov. 2016.
[18] J. Borghetti, G. Snider, P. Kuekes, J. Yang, D. Stewart, and R. Williams, “Memristive Switches Enable Stateful Logic Operations via Material Implication,” Nature, vol. 464, no. 7290, pp. 873-876, Apr. 2010.
[19] P. Chi, S. Li, C. Xu, T. Zhang, J. Zhao, Y. Liu, Y. Wang, and Y. Xie, “PRIME: A Novel Processing-in-Memory Architecture for Neural Network Computation in ReRAM-based Main Memory,” ACM SIGARCH Computer Architecture News, vol. 44, no. 3, pp. 27-39, Jun. 2016.
[20] F. Su, W. Chen, L. Xia, C. Lo, T. Tang, Z. Wang, K. Hsu, M. Cheng, J. Li, Y. Xie, Y. Wang, M. Chang, H. Yang, and Y. Liu, “A 462GOPs/J RRAM-Based Nonvolatile Intelligent Processor for Energy Harvesting IoE System Featuring Nonvolatile Logics and Processing-in-Memory,” in Symposium on VLSI Technology, pp. C260-C261, Jun. 2017.
[21] Q. Xia, and J. Yang, “Memristive Crossbar Arrays for Brain-Inspired Computing,” Nature Materials, vol. 18, pp. 309-323, Apr. 2019.
[22] J. Yang, D. Strukov, and D. Stewart, “Memristive Devices for Computing,” Nature Nanotechnology, vol. 8, no. 13, pp. 13-24, Dec. 2012.
[23] M. Prezioso, F. Bayat, B. Hoskins, G. Adam, K. Likharev, and D. Strukov, “Training and Operation of an Integrated Neuromorphic Network Based on Metal-Oxide Memristors,” Nature, vol. 521, pp. 61-64, May 2015.
[24] S. Yu, “Neuro-Inspired Computing With Emerging Nonvolatile Memory,” Proceedings of the IEEE, vol. 106, no. 2, pp. 260-285, Feb. 2018.
[25] H. Wu, X. Wang, B. Gao, N. Deng, Z. Lu, B. Haukness, G. Bronner, and H. Qian, “Resistive Random Access Memory for Future Information Processing System,” Proceedings of the IEEE, vol. 105, no. 9, pp. 1770–1789, Sep. 2017.
[26] P. Huang, J. Kang, Y. Zhao, S. Chen, R. Han, Z. Zhou, Z. Chen, W. Ma, M. Li, L. Liu, and X. Liu, “Reconfigurable Nonvolatile Logic Operations in Resistance Switching Crossbar Array for Large-Scale Circuits,” Advanced Materials, vol. 28, no. 44, pp. 9758-9764, Nov. 2016.
[27] Y. Zhou, Y. Li, N. Duan, Z. Wang, K. Lu, M. Jin, L. Cheng, S. Hu, T. Chang, H. Sun, K. Xue, and X. Miao, “Boolean and Sequential Logic in a One-Memristor-One-Resistor (1M1R) Structure for In-Memory Computing,” Advanced Electronic Materials, vol. 4, no. 9, pp. 1800229(1-9), Jun. 2018.
[28] H. Zhang, W. Kang, K. Cao, B. Wu, Y. Zhang, and W. Zhao, “Spintronic Processing Unit in Spin Transfer Torque Magnetic Random Access Memory,” IEEE Transactions on Electron Devices, vol. 66, no. 4, pp. 2017 – 2022, Apr. 2019.
[29] H. Zhang, W. Kang, L. Wang, K. L. Wang, and W. Zhao, “Stateful Reconfigurable Logic via a Single-Voltage-Gated Spin Hall-Effect Driven Magnetic Tunnel Junction in a Spintronic Memory,” IEEE Transactions on Electron Devices, vol. 64, no. 10, pp. 4295-4301, Oct. 2017.
[30] W. Kang, H. Wang, Z. Wang,Y. Zhang, and W. Zhao, “In-Memory Processing Paradigm for Bitwise Logic Operations in STT-MRAM,” IEEE Transactions on Magnetics, vol. 53, no. 11, pp. 1-4, Nov. 2017.
[31] Z. Jiang, S. Yin, J. Seo, and M. Seok, “XNOR-SRAM In-Bitcell Computing SRAM Macro based on Resistive Computing Mechanism,” in Proceedings of the on Great Lakes Symposium on VLSI, pp. 417-422, May 2019.
[32] H. Valavi, P. Ramadge, E. Nestler, and N. Verma, “A 64-Tile 2.4-Mb In-Memory-Computing CNN Accelerator Employing Charge-Domain Compute,” IEEE Journal of Solid-State Circuits, vol. 54, no. 6, pp. 1789-1799, Jun. 2019.
[33] V. Seshadri, D. Lee, T. Mullins, H. Hassan, A. Boroumand, J. Kim, M. Kozuch, O. Mutlu, P. Gibbons, and T. Mowry, “Ambit: In-Memory Accelerator for Bulk Bitwise Operations Using Commodity Dram Technology,” in Proceedings of the 50th Annual IEEE/ACM International Symposium on Microarchitecture, pp. 273–287, Oct. 2017.
[34] S. Li, D. Niu, K. Malladi, H. Zheng, B. Brennan, and Y. Xie, “Drisa: A Dram-Based Reconfigurable in-Situ Accelerator,” in Proceedings of the 50th Annual IEEE/ACM International Symposium on Microarchitecture, pp. 288–301, Oct. 2017.
[35] A. Patil, H. Hua, S. Gonugondla, M. Kang, and N. Shanbhag, “An MRAM-based Deep In-Memory Architecture for Deep Neural Networks,” in IEEE International Symposium on Circuits and Systems (ISCAS), pp. 1-5, May 2019.
[36] S. Li, C. Xu, Q. Zou, J. Zhao, Y. Lu, and Y. Xie, “Pinatubo: A Processing-in-Memory Architecture for Bulk Bitwise Operations in Emerging Non-Volatile Memories,” in ACM/EDAC/IEEE Design Automation Conference (DAC), pp. 1-6, Jun. 2016
[37] S. Angizi, Z. He, and D. Fan, “PIMA-Logic: A Novel Processing-in-Memory Architecture for Highly Flexible and Energy-Efficient Logic Computation,” in Proceedings of the 55th Annual Design Automation Conference (DAC), Jun. 2018.
[38] Z. Wang, Y. Su, Y. Li, Y. Zhou, T. Chu, K. Chang, T. Chang, T. Tsai, S. Sze, and X. Miao, “Functional Complete Boolean Logic in 1T1R Resistive Random Access Memory,” IEEE Electron Device Letters, vol. 38, no. 2, pp. 179 – 182, Feb. 2017
[39] N. Wald, and S. Kvatinsky, “Design Methodology for Stateful Memristive Logic Gates,” in IEEE International Conference on the Science of Electrical Engineering (ICSEE), pp. 1-5, Nov. 2016.
[40] H. Zhang, W. Kang, B. Wu, P. Ouyang, E. Deng, Y. Zhang, and W. Zhao, “Spintronic Processing Unit Within Voltage-Gated Spin Hall Effect MRAMs,” IEEE Transactions on Nanotechnology, vol. 18, pp. 473 – 483, May 2019.
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2276期内容,欢迎关注。
★芯片“备胎”计划
★定增市场井喷!439亿重金砸入A股半导体
★日本芯片厂商Top 10榜单:期待第三个亮点
存储|射频|CMOS|设备|FPGA|晶圆|苹果|海思|半导体股价






















评论