数仓大法好!跨境电商 Shopee 的实时数仓之路
本文讲述 Flink 在 Shopee 新加坡数据组 ( Shopee Singapore Data Team ) 的应用实践,主要内容包括:
- 实时数仓建设背景
- Flink 在实时数据数仓建设中结合 Druid、Hive 的应用场景
- 实时任务监控
- Streaming SQL 平台化
- Streaming Job 管理
- 未来规划优化方向
建设背景
Shopee 是东南亚与台湾领航电商平台,覆盖新加坡、马来西亚、菲律宾、台湾、印度尼西亚、泰国及越南七大市场,同时在中国深圳、上海和香港设立跨境业务办公室。
- Shopee 在2020年第一季的总订单量高达4.298亿,同比增长111.2%。
- 根据 App Annie, Shopee 在2020年第一季强势跻身全球购物类 App 下载量前三名。
- 同时斩获东南亚及台湾市场购物类 App 年度总下载量、平均月活数、安卓使用总时长三项冠军,并领跑东南亚两大头部市场,拿下印尼及越南年度购物类 App 下月活量双冠王。
其中包括订单商品、物流,支付,数字产品等各方面的业务。为了支持这些互联网化产品,应对越来的越多的业务挑战,于是我们进行了数据仓库的设计和架构建设。
数据仓库挑战
当前随着业务发展,数据规模的膨胀和商务智能团队对实时需求的不断增长,业务挑战越来越大:
- 业务维度 而言,业务需求越来越复杂,有需要明细数据查询,又有实时各种维度聚合报表,实时标签培训和查询需求。同时大量业务共享了一些业务逻辑,造成大量业务耦合度高,重复开发。
- 平台架构 而言,当前任务越来越多,管理调度,资源管理,数据质量异常监控等也越来越重要。实时化也越来急迫,目前大量业务还是离线任务形式,导致凌晨服务负载压力巨大,同时基于 T+1(天、小时级)架构业务无法满足精细化、实时化运营需要。
- 技术实现 而言,现在实时业务大量采用 Spark Structured Streaming 实现,严重依赖 HBase 做 Stateful 需求,开发复杂;在异常故障事故,Task 失败,缺乏 Exactly Once 特性支持,数据易丢失、重复。
为了解决上述问题,于是开始了 Flink 实时数仓的探索。
数据仓库架构
为了支持这些互联网化产品不断增长的的数据和复杂的业务,Shopee 构建如下图数据仓库架构,从下到上层来看:
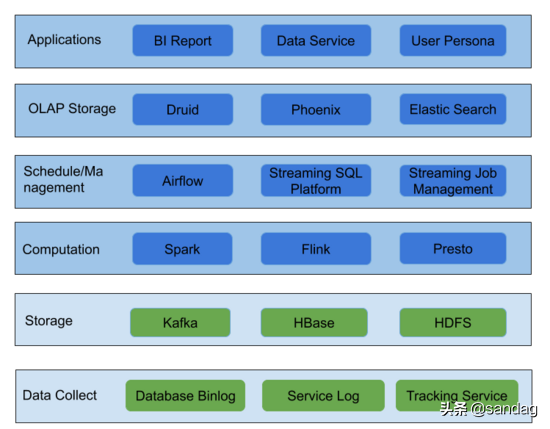
- 最底层是 数据收集层 ,这一层负责实时数据,包括 Binlog、Service Log, Tracking Service Log,经过 Real-time Ingestion 团队数据将会被收集到 Kafka 、Hbase 中。Auto-Ingestion 团队负责数据库数离线日常收集到 HDFS。
- 然后是 存储层 ,这层主要是 Kafka 保存实时消息,加上 HDFS 保存 Hive 数据存储等,HBase 保存维度数据。
- 在存储层上面是 Spark, Flink 计算引擎, Presto SQL 查询引擎 。
- 然后是 调度管理层 ,各种资源管理,任务管理,任务调度,管理各种 Spark,Flink 任务。
- 资源管理层上一层是 OLAP 数据存储层 ,Druid 用于存储时间序列数据,Phoenix(HBase)存储聚合报表数据、维度表数据、标签数据,Elastic Search 存储需要多维度字段索引的数据如广告数据、用户画像等。
- 最上层是 应用层 ,数据报表,数据业务服务,用户画像等。
Flink 实时数据数仓实践
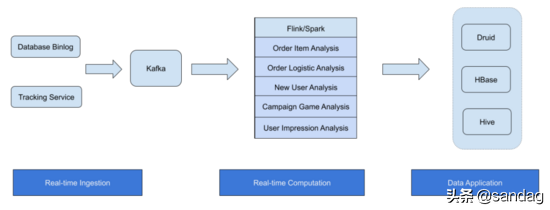
目前在 Shopee Data Team 主要从数据分库 Binlog 以及 Tracking Service 同步到 Kafka 集群中,通过 Flink/Spark 计算,包含实时订单商品销量优惠活动分析,订单物流分析、产品用户标新、用户印象行为分析,电商活动游戏运营分析等。最后的结果存到 Druid、 HBase、 HDFS 等,后面接入一些数据应用产品。目前已经有不少核心作业从 Spark Structured Streaming 迁移到 Flink Streaming 实现。
Flink 与 Druid 结合的实时数仓应用
在实时订单销量分析产品中,通过 Flink 处理订单流,将处理后的明细数据实时注入Druid,达到公司实时运营活动分析等用途。我们使用 T-1(天)的 Lambda 架构来实时和历史订单数据产品分析,Flink 只处理实时今天的订单数据,每日会定时将昨日的数据通过离线任务索引到 Druid 中覆盖修正实时数据的微小误差。整体的 Flink 实时处理流程如下图,从上中下看共三条流水线:
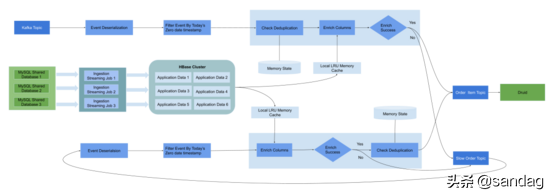
第一条流水线,通过 Kafka 接入 订单 Binlog 事件。
- 首先,解析反序列化订单事件,通过订单时间过滤无效订单,只保留今日订单。通过订单主键 KeyBy 进入ProcessWindowFunction,因为上游数据是 Binlog 会有重复订单事件,所以会通过 ValueState 来对订单进行去重。
- 然后,通过查询 HBase (Phoenix 表)进行Enrichment 维度字段,从 Phoenix 表中获取订单商品信息,分类,用户信息等。
- 最后,通过判断是否所有字段成功关联,如果所有字段都关联成功将会把消息打入下游kafka,并实时注入到 Druid;如果有字段关联失败将会把订单事件通过 Side Output 进入另一个 Slow Kafka Topic,以便处理异常订单。
第二条流水线比较复杂,通过多个实时任务将各分表 Slave Binlog 同步到 Hbase Phoenix 表,以便做成实时订单流的维度表。目前遇到比较多问题还是经常 Binlog 延迟等问题,以及数据热点问题。
第三条流基本与第一条类似,类似消息队列中的 dead message 异常处理。因为大量维度表依赖,不能保证 Phoenix 都在订单被处理前就被同步到 Phoenix 表,比如新订单商品,新用户,新店铺,新分类,新商品等。所以我们引入一条实时 backfill 处理流将会对第一条主流,处理失败的订单重复处理,直到所有字段都关联成功才会进入下游 Druid。
另外为了避免一些过期消息进入死循环,同样有个事件过滤窗口,保证只保留今日的订单事件在流水线中被处理。不同的是,因为需要区分付款订单和未付款订单事件类型(可能一个订单有两个状态事件,当用户下单时,会有一个下单事件,当用户完成支付会有一个支付完成事件),所以将订单是否被处理状态放在enrichment之后标记重复成功。
■ 订单事件状态维护
因为上游数据源是 Binlog,所以随着订单状态的更新,会有大量的订单重复事件。通过使用 Flink State 功能保存在内存中(FsSateBackend),以 ValueState 来标记订单是否被处理,通过设置 TTL,保证订单状态保存24小时过期,现在活动高峰期大概2G State,平均每个TaskManager大约100M State。Checkpoint interval 设置为10秒一次,HDFS 负载并不高。同时因为流使用了窗口和自定义 Trigger,导致 State 需要缓冲少量窗口数据。窗口的使用将会在 Enrihcment 流程优化部分详细说明。
■ Enrihcment 流程优化
在 Enrichment 步骤, 业务逻辑复杂,存在大量 IO,我们做了大量改进优化。
- 首先 ,从 HBase 表关联字段,通过增加 Local RLU Memeory Cache 层,减少 Hbase 的访问量,加速关联;对 HBase Row Key Salt Bucket 避免订单商品表访问热点问题。
- 第二 ,HBase 表直接访问层(Service)通过 Google Guice 管理依赖方便配置管理,内存 Cache 关联等。
- 第三 ,由于商品表和订单商品同步到 HBase 有一定延迟,导致大量的订单事件进入 Slow Kafka topic,所以通过设置窗口和自定义 Trigger 保证订单数量到一定数量或者窗口超时才触发窗口数据的处理,优化后能保证98%的订单在主流被成功处理。
- 最后 ,在订单关联订单商品时,考虑过使用 Interval Join 来做,但是由于一个订单有多条订单商品信息,加上上游是 Binlog 事件,以及其他维度表数据延迟问题,导致业务逻辑复杂,而且计算产出数据保存在 Druid 只能支持增量更新。所以选择了使用 HBase 存储来关联订单商品信息,附加慢消息处理流来解决数据延迟问题。
■ 数据质量保障和监控
目前将 Checkpoint 设置为 exactly once 模式,并开启了Kafka exactly once 生产者模式,通过 Two Phase Commit 功能保证数据的一致性,避免 task 失败,job 重启时导致数据丢失。监控方面,通过监控 Upstream Kafka Topic,以及 HBase 表写入更新状态,结合下游 Druid 数据延迟监控,做到 end-to-end 的 lag 指标监控。通过 Flink Metric Report 汇报 Hbase 访问性能指标,缓存大小,延迟订单数量等来对 Flink job 具体步骤性能分析。
Flink 与 Hive 结合的实时数仓应用
在订单物流实时分析业务,接入 Binlog event 实现支持点更新的物流分析,使用 Flink Retract Stream 功能来支持每当订单和物流有最新状态变化事件就触发下游数据更新。通过 Interval Join 订单流和物流流,并使用 Rocksdb State 与 Incremental Checkpoint 来维护最近七天的状态数据,从 Hbase 来增加用户维度信息等,维度字段 enrihcment 通过 Local LRU Memory Cache 层来优化查询,最后定时从 Hbase 导出到 HDFS。
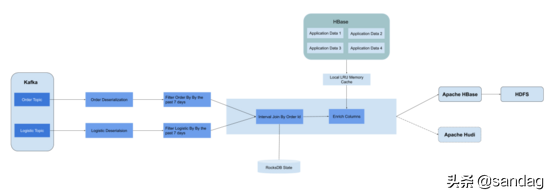
现在将 Flink 任务产生的订单物流事件保存 HBase 来支持记录级别的点更新,每小时从 HBase 导出到 HDFS 结果,通过 Presto 接入来做实时分析。HBase 导出到HDFS,通过对 Hbase Row Key Salt Bucket 避免热点问题,优化减小 Region Size(默认10G)来减少导出时间。但是数据现在延迟还是比较严重,在一个半小时左右,而且链路繁琐。将来考虑加入 Apache Hudi 组建接入 Presto,将延迟降到半小时内。
Streaming SQL 应用与管理
目前 Shopee 有大量的实时需求通过 SQL 实现,应用场景主要是应用层实时汇总数据报表、维度表更新等。业务通过 SDK 和一站式网站管理两种方式实现。一是以 SDK 形式提供支持,用户可以通过引入 JAR 依赖进行二次项目开发。二是制作了相关网站,通过以任务形式,用户创建任务编辑保存 SQL 来实现业务需求,目前支持如下:
- 任务列表、分组管理,支持重启,停止,禁用任务功能。
- 任务支持 crontab 规则定时执行调度模式和 Streaming 模式。
- JAR 资源管理,任务自定义 JAR 引用,以便重复使用 UDF 等。
- 通用 SQL 资源管理,任务引入共享 SQL 文件,避免重复 SQL 逻辑、重复定义 View 以及环境配置等。
- 用户分组权限管理。
- 集成 Garafna 做任务延迟报警。
下面是部分任务组织 UI 化形式:
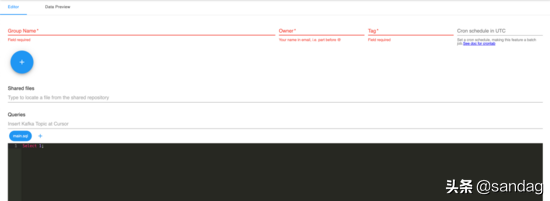
当前平台只支持 Spark SQL 实现 Stream SQL,使用 Hive 存储元数据,通过关联维度表 JOIN Apache Phoenix 等外部表和外部服务实现 enrichment 等功能。通过对比 Flink SQL 与 Spark SQL,发现 Spark SQL 不少缺点:
- Spark SQL 窗口函数种类少,没有 Flink 的支持灵活,导致大量聚合任务无法通过平台 SQL 化。
- Spark Stateful 状态控制差,没有 Flink Rocksdb State 增量状态支持。
- Spark 关联维度表时,以前在每次 micro-batch 中都需要加载全量维度表,现在已经改为 GET 方式,Lookup 性能方面已经有提升不少,但还是没有像 Flink 异步 Lookup 那样的异步功能,提高性能。
- 没有 Flink Snapshot 和 Two Phase Commit 功能的支持,导致任务重启,失败恢复会出现数据不一致,失去准确性。
Spark SQL 支持还是有很多局限性,目前正在做 Flink SQL 需求导入评估阶段,并计划在 Stream SQL Platform 接入 Flink SQL 的支持。来满足公司越来越复杂用户画像标签标注和简单实时业务 SQL 化,减少业务开发成本。同时需要引入更好的 UDF 管理方式,集成元数据服务简化开发。
Streaming Job 管理
Shopee Data Team 拥有大量的实时任务是通过 Jar 包发布的,目前在 Job 管理上通过网站页面化,来减少 Job 维护成本。目前支持环境管理,任务管理,任务应用配置管理,和任务监控报警。
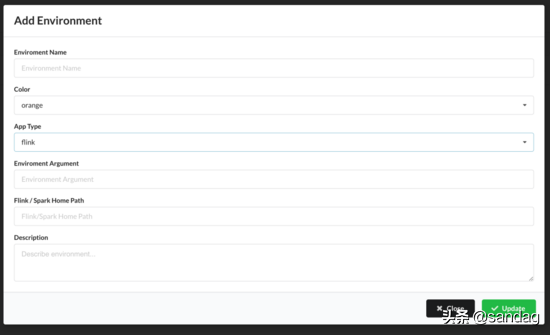
环境管理
目前可以配置 Flink / Spark Bin 路径来支持不同的 Flink/Spark 版本,来支持 Flink 升级带来的多版本问题,并支持一些颜色高亮来区分不同环境。
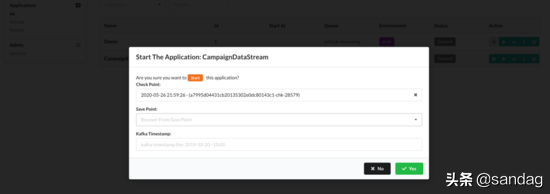
任务管理
现在支持实时任务的环境检索,状态检索,名字检索等。支持重启,禁用,配置任务参数等。任务支持从 checkpoint/savepoint 恢复,停止任务自动保存 savepoint,从 kafka timestamp 启动。
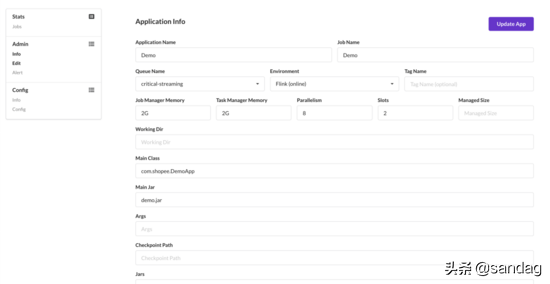
任务配置管理
同时实时任务也支持配置内存,CPU 等 Flink Job 运行参数、JAR 依赖配置等。目前支持预览,编辑更新等,通过 Jekins CICD 集成与人工干预结果,来完成 Job 的部署升级。
任务应用配置管理
任务应用配置是使用 HOCON 配置格式支持,目前支持共享配置集成,并通过配置名约定将 Checkpoint 路径自动绑定到配置中。网站支持预览模式,编辑模式,配置高亮等,将来会集成配置版本回滚等功能。
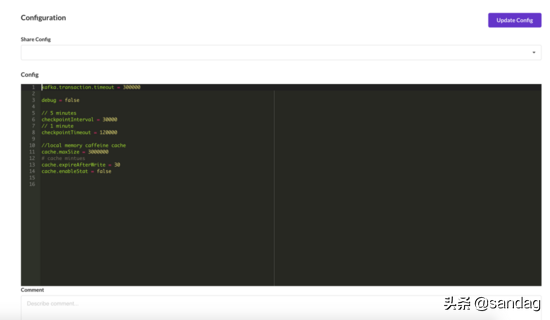
任务监控报警
对于任务监控方面,现在支持任务异常处理报警。异常处理支持自动挂起失败的任务,并从上次最新 checkpoint 恢复;通过 Flink REST API 检测 Flink Job 状态,来避免 Flink Job 异常造成的假活状态。出现任务重启,异常情况会通过邮件等方式给任务负责人发报警,未来打算在网站集成 Grafana/Promethus 等监控工具来完成任务监控自动化等。
未来规划
总体而言,Flink 在 Shopee 从 2019 年底开始调研,到项目落地不到半年时间,已经完成业务大量需求导入评估,对 Exactly Once,Kafka Exactly Once Semantics,Two Phase Commit,Interval Join,Rocksdb/FS State 一系列的功能进行了验证。在未来规划上:
- 首先,会尝试更多的实时任务 Flink SQL 化,进一步实现流批统一;
- 其次,会对目前大量 Spark structured Streaming Job 迁移到 Flink 实现,并对新业务进行 Flink 探索。
- 在 Streaming SQL Platform 也会加入 Flink SQL 支持,来解决当前平台遇到一些性能瓶颈和业务支持局限性。
作者简介:
黄良辉,2019 年加入 Shopee,在 Shoppe Data Team 负责实时数据业务和数据产品开发。





















评论