中文文本标注工具调研以及BRAT安装使用
背景:最近的工作需要对文本先进行标注,然后才可以做接下来的文本分类工作。其中主要内容是对一段文本打标签,标记该文本描述了一个我们预定义的种类标签。
原来文本数量少的时候可以手工标注,随着文本数量的增多,需要借助标注工具,调研了目前常用的几种:
1,BRAT
https://github.com/nlplab/brat
首先是业内常用的BRAT,官网地址:http://brat.nlplab.org/ ,这是很早以前出现的一个工具,基于web的文本标注工具,主要用于对文本的结构化标注,用BRAT生成的标注结果能够把无结构化的原始文本结构化,供计算机处理。利用该工具可以方便的获得各项NLP任务需要的标注语料。面向unix-like系统
最大的特点是在标注实体的同时可以进行关系的标注。而且是一个server服务端,搭建好后可以多人访问,也适合多人协同标注。据说可以通过tomcat搭建,博主没自己试验过。

经过调研比较,我们最终选定还是用brat进行标注,接下来介绍如何使用brat,其他的标注工具调研在后面有介绍。
1,安装brat
1.1如果你是win10系列,那么你可能需要一个unix-like环境,比如
通过虚拟机virtualBox,Ubuntu18.04, https://blog.csdn.net/zcooa/article/details/80615743
或者通过在win上安装cgwin来实现 cgwin https://blog.csdn.net/heshushun/article/details/78664384
1.2如果你在osx或者linux系统上就可以直接按照下面安装
博主是放在一个服务器server上安装,然后通过访问ip的方式来完成标注工作。
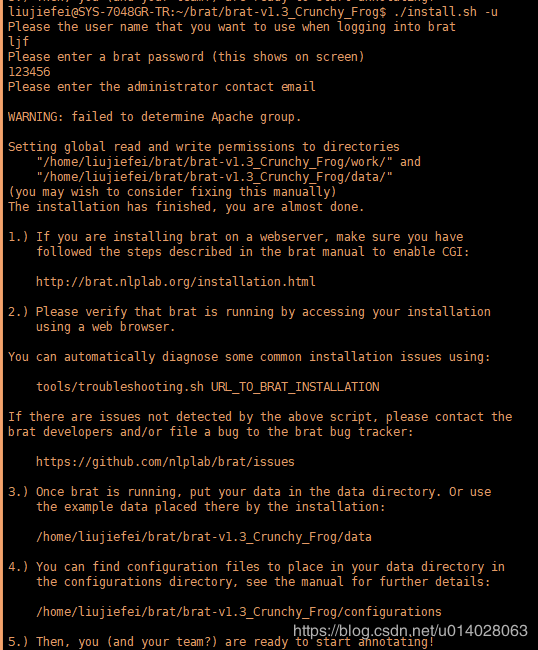
先下载,http://brat.nlplab.org/installation.html,brat-v1.3_Crunchy_Frog.tar.gz这个文件
然后解压,运行即可
tar -xf brat-v1.3_Crunchy_Frog.tar
cd brat-v1.3_Crunchy_Frog
./install.sh –u
这里会提示你输入username,可以自己设置,将来标注的时候,支持多人标注。
python standalone.py #(不可用python3)
2,使用brat
以上操作在Xshell中完成,此时brat服务已经启动,如果你的服务器有图形界面,或者ubuntu中,那么你可以直接用自带的浏览器访问 127.0.0.1:8001
我这里没有图形界面,所以命令行访问firefox
![]()
然后会打开一个窗口,这个功能需要xmanager软件,会提示你安装的,

,继续访问127.0.0.1:8001就可以了
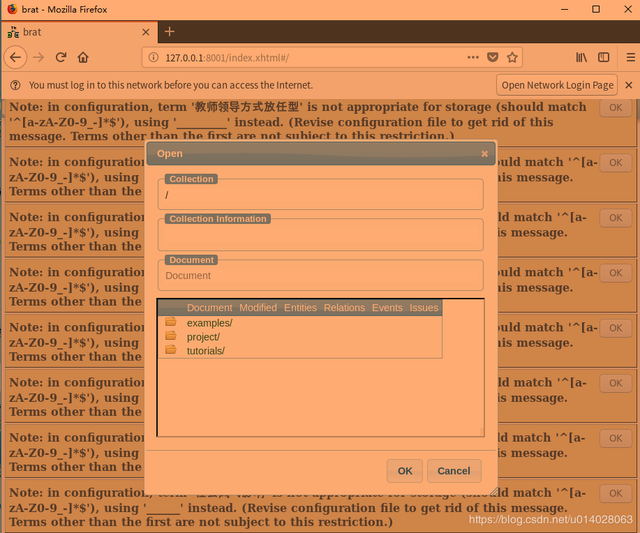
3,安装完成后,做中文标注
3.1支持中文
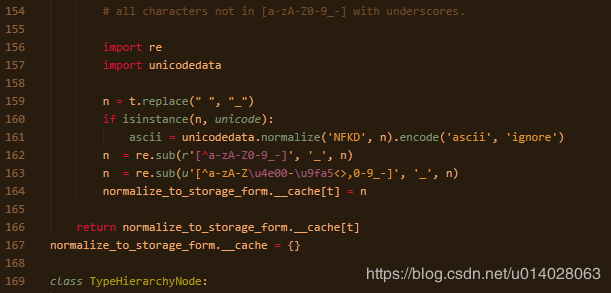
brat本身是不支持中文的,如果在配置文件里定义中文会报错,解决办法是./server/src/projectconfig.py文件的第163行,加上中文支持即可:
n = re.sub(u'[^a-zA-Z\u4e00-\u9fa5<>,0-9_-]', '_', n)
3.2 增加用户(这个一般不需要)
官方文档:If you want to add additional users, you can edit the config.py file, which contains further instructions.
找到config.py 对应的行,增加:
USER_PASSWORD = { 'admn': 'admin', 'test': 'test', # (add USERNAME:PASSWORD pairs below this line.) }
重新启动后,使用test就可以登录了
注意:当前用户只能针对自己的标注进行修改,并不能修改其他人进行的标注
3.3 导入collection
导入文件的时候,必须要文件符合:文件名.xxx和文件名.ann 一一对应的格式即可
直接将包含txt数据集的文件夹放置到安装文件下一个data的目录下,然后使用命令:
find 文件夹名称 -name '*.txt'|sed -e 's|\.txt|.ann|g'|xargs touch
其意思是对每个txt文件都创建一个空的标引文件.ann,因为BRAT是要求的collection中,每个txt文件是必须有一个对应的.ann文件的,方便放置标引内容,这个ann文件的格式也挺规范
将要标注的文件导入项目中data/路径下即可,可以查看其中examples文件下以及tutorials文件下帮助文档。
3.4具体标注配置
brat通过配置文件来决定对语料的标注可以满足何种任务,包括四个文件
annotation.conf: annotation type configuration
visual.conf: annotation display configuration
tools.conf: annotation tool configuration
kb_shortcuts.conf: keyboard shortcut tool configuration
一般只需要修改annotation.conf即可,该文件用于对标注的数据结构进行配置,典型的配置如下:
每个文件需要包含四类模块:entities、relations、events、attributes。各个模块都可以定义为空,其中
entities用来定义标注的实体名称,其格式为每行一个实体类型,比如:人名、地名、英雄名、技能名等,可以采用tab来增加二级标注,如下面的实体标注中技能下的二级标注战斗技能等。

relations用来定义实体间的关系,格式为每行定义一种关系,第一列为关系类型,随后是用逗号分隔的ArgN:实体名,用来表示关系的各个相关者。比如例子中,同盟关系是存在于英雄之间
events用来定义事件,每行定义一类事件,第一列为事件名,随后是用逗号分隔的Participant:实体名,用来表示事件的各个参与者。比如例子中,1v1事件需要多个英雄参加
attributes用来定义属性,每行一个属性,第一列为属性名,随后是用逗号分隔的Arg:<模块类型>, Value:属性值,注意属性值可以有多个,比如例子中,定义了实体类型可以有攻击力,值从1-3
[entities]
英雄
北欧英雄
希腊英雄
技能
战斗技能
生活技能
采矿
种地
种白菜
种大米
[relations]
同盟Arg1:英雄, Arg2:英雄
拥有Arg1:英雄, Arg2:技能
[events]
1v1Participant1:英雄, Participant2:英雄
[attributes]
攻击力Arg:<ENTITY>, Value:1|2|3|4|5
选中要标注的文本,会弹出窗口,选中标注label,然后完成标注
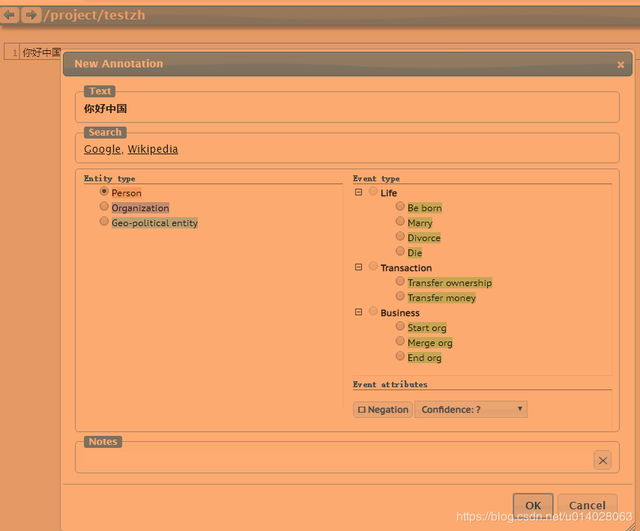
标注完成后,鼠标移动到上面,点击data
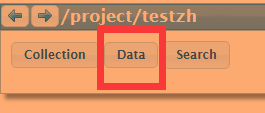
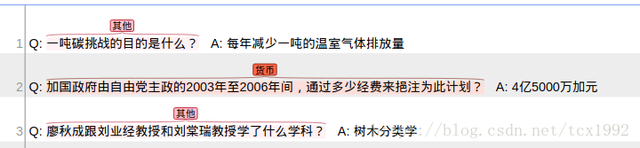
点击OK将标注信息作为ann导出,如下:
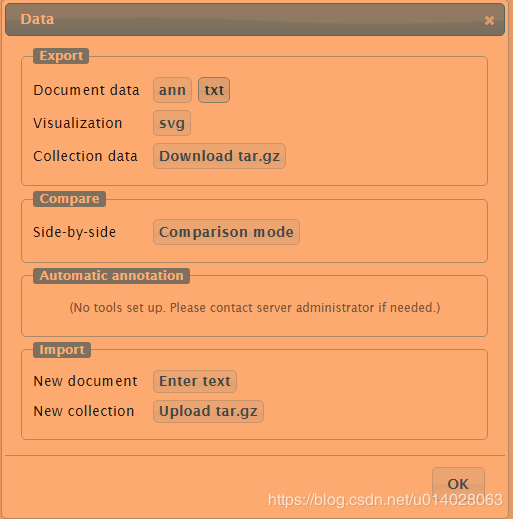
1 T2 OTH 3 15 一吨碳挑战的目的是什么?
2 T1 NUM,MNY 37 75 加国政府由自由党主政的2003年至2006年间,通过多少经费来挹注为此计划?
3 T3 OTH 92 114 廖秋成跟刘业经教授和刘棠瑞教授学了什么学科?
踩坑记录:
1,如果导入文本编码格式不是utf-8,就无法正常导入。导入文本名称为英文.txt
2,如果要标注中文标签,直接在annotation.conf中写入中文标签,会出现报错信息

最终解决方案是在annotation.conf中用label1,label2来表示,然后在视觉配置visual.conf中对应修改
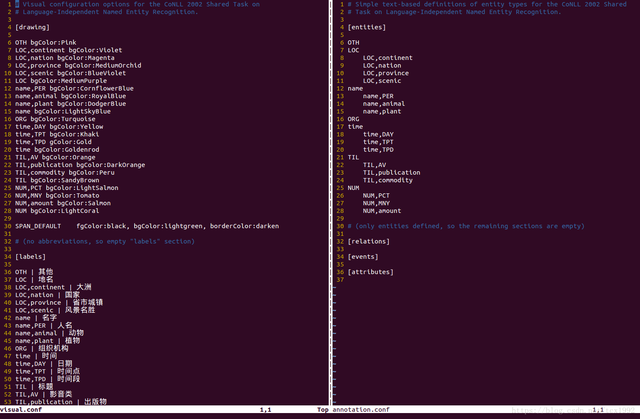
如上面:
[labels]
label1 | 攻击行为
label2 | 违纪行为
2,Chinese-Annotator
https://github.com/deepwel/Chinese-Annotator
该工具灵感来自于Prodigy,每一次的标注只需要用户解决一个case的问题。以文本分类为例,对于算法给出的分类结果,只需要点击“正确”提供正样本,“错误”提供负样本,“略过”将不相关的信息滤除,“Redo”让用户撤回操作,四个功能键以最简模式让用户进行标注操作。真正应用中,应该还要加入一个用户自己加入标注的交互方式,比如用户可以高亮一个词然后选择是“公司”,或者链接两个实体选择他们的关系等等。 主要可以用来做命名实体。
优点是界面友好,面向OSX的,没试过win10可不可用
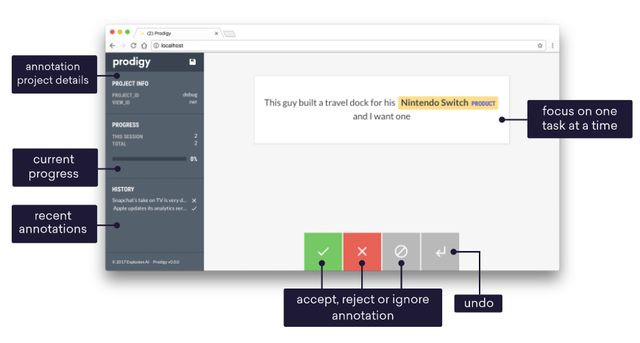
我们的任务更多的是对一段文本的信息进行标注,判断是否这段文本表示了我们预先定义的一个label,所以这个工具不太适合,也没有具体安装使用。
3,YEDDA
YEDDA是由新加坡科技大学yangjie等人开发的,前身也就是SUTDAnnotator,https://github.com/jiesutd/YEDDA
开发用于在文本(几乎所有语言,包括英语、中文)、符号甚至表情符号上注释块/实体/事件。它支持快捷注释,手工注释文本非常有效。用户只需选中文本并按快捷键如A,就会自动标注。它还支持命令注释模型,该模型可以批量注释多个实体,并支持将带注释的文本导出为序列文本。此外,更新版本还包括智能推荐和管理员分析。与所有主流操作系统兼容,在win10可以直接用,但是是基于python2开发的,所以安装需要用python2。
需要标注的文档用txt文件导入,编码方式为utf-8,如果编码方式不对,会显示乱码。
标注结果参考brat,用.ann文件来保存。
目前仍在更新,获得2018ACL best demo nomination

优点是安装方便,标注方便,如果要实现给同一个实体加多个标签,也可以实现,还有其他功能做的很赞
但是为了标注方便,可以通过按键实现,使得快捷键设置不宜过多,我们的工作中要求标注标签在50个以上,所以这个工具不适合,无法添加这么多工具,最后没有采用,如果你的标注标签要求较少,这个工具很适合。
4,IEPY
IEPY主要特色在关系抽取,基于java开发的,是一种开源的信息抽取工具
在github可以下载Python开发 https://github.com/machinalis/iepy。可以阅读https://iepy.readthedocs.io/en/latest/。
我们将数据加载到数据库的方式是从csv文件导入数据。使用应用程序文件夹中提供的脚本csv_to_iepy来执行此操作。特别擅长对大型数据集进行关系抽取。
感觉不是很好用,而且我们主要是加标签的工作,不适合。
5,DeepDive (Mindtagger)
2017年后已经不再更新,DeepDive是一个从黑暗数据中提取价值的系统。与暗物质一样,暗数据是隐藏在文本、表格、图形和图像中的大量数据,缺乏结构,因此现有软件基本上无法处理这些数据。通过从非结构化信息(文本文档)创建结构化数据(SQL表),并将这些数据与现有的结构化数据库集成,DeepDive可以帮助将黑暗数据暴露出来。DeepDive用于提取实体之间复杂的关系,并对涉及这些实体的事实进行推断。深潜帮助人们处理各种各样的问题
Labeling DeepDive data with Mindtagger
http://deepdive.stanford.edu/labeling
A tool for labeling data
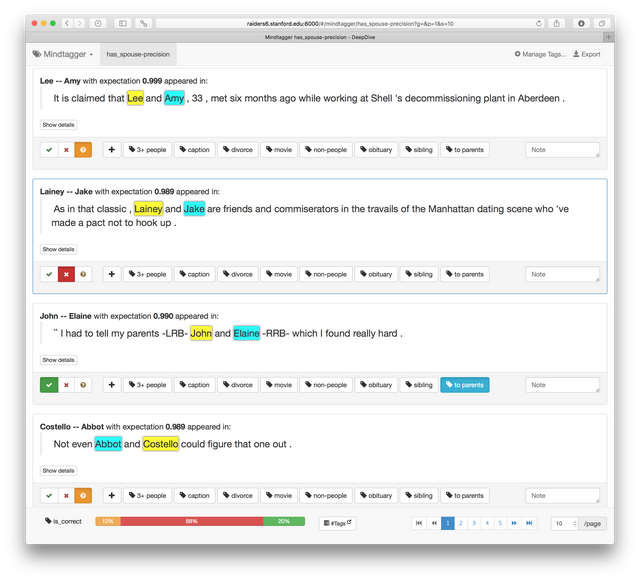
不好用,但是可以统计最后的标注标签以及导出标注信息可以保存为不同格式。
6,snorkel
https://github.com/HazyResearch/snorkel
用于快速创建、建模和管理培训数据的系统。当今最先进的机器学习模型需要大量标记的训练集,而这些训练集通常不存在于实际应用中。相反,Snorkel是基于新的数据编程范式的,在这种范式中,开发人员将重点放在编写一组标记函数上,这些函数只是通过编程方式标记数据的脚本。生成的标签是有噪声的,但是Snorkel会自动为这个过程建模——从本质上说,是学习,哪个标签函数比其他函数更准确——然后使用它来训练一个目标
调研后发现不适合我们的工作。但是这个项目有兴趣的可以跟一下。
7,Prodigy
https://prodi.gy/docs/
一个由主动学习驱动的注释工具。具体的可以看文档。
8,其他标注方式
https://www.jianshu.com/p/6d80d9ff43b4
9,图像标注软件将来再介绍
https://www.cnblogs.com/alexanderkun/p/6936732.html
NLP相关问题可以关注我的公众号 京西凌烟
一起学习讨论