「Python量化金融」基于核PCA的股票市场动态风险指数
主成分分析(PCA)的定义如下: 主成分分析(PCA)是一种统计过程,它使用正交变换将一组可能相关变量的观察值转换为一组线性不相关变量的值称为主成分。主成分的数目小于或等于原始变量的数目。这种转换的定义是这样的:第一个主成分具有最大的可能方差(即,尽可能多地解释数据中的可变性),而每个后续成分依次具有最大的方差。
本文是一项学术研究工作的一个小部分,也是《Python for Finance 》的习作。我们用机器学习中的核PCA(kernel pca)构造中国和RCEP国家11个成员国股票市场指数的动态风险指数,我们希望该指数能够吸收所有国家股指的主要信息,并对各国股指和宏观经济变化有领先效果。11个国家分别是中国、日本、老挝、新加坡、泰国、韩国、越南、马来西亚、菲律宾、柬埔寨、澳大利亚。
实现过程如下:
# -*- coding: utf-8 -*-
"""
Created on Fri Jan 14 20:07:00 2022
@author: kateg
"""
import numpy as np
import pandas as pd
from sklearn.decomposition import KernelPCA
from sklearn.impute import SimpleImputer # 简单插值
import matplotlib.pyplot as plt
# In[基于主成分分析的动态风险指数]:
# 1 读入数据,数据从Wind金融终端导出
symbols = ['China', 'Laos', 'Singapore', 'Thailand', 'Vietnam',
'Malaysia', 'Philippines', 'Cambodia', 'Japan',
'South Korea', 'Australia']
data = pd.DataFrame()
data = pd.read_csv('D:\Anaconda\workspace\data_analysis\data_financial\RCEP.csv').set_index('Date')
# 只取收盘价
for sym in symbols:
data[sym] = get_price(sym, start_date, end_date, freq = 'D')['Close']
# 用插值法补缺失值
pca_imputer = SimpleImputer(strategy='mean')
data_imputer = pca_imputer.fit_transform(data)
df_data_imputer = pd.DataFrame(data_imputer, columns = data.columns, index = data.index) # 把索引从原来的表重新补回去
df_data_imputer[df_data_imputer.columns[:6]].head()
# 2 应用PCA
scale_function = lambda x:(x - x.mean()) / x.std() # 用于将数据标准化的函数
pca = KernelPCA().fit(df_data_imputer.apply(scale_function)) # 用标准化数据做PCA
len(pca.lambdas_) # 能够提取的主成分,这里因为有11个指数,所以最多能够提取11个主成分
pca.lambdas_[:5].round()
get_we = lambda x: x/x.sum()
# 看每个主成分的相对重要性,这里显示前3个主成分已经足够了,对方差变异的解释超过89%
# 第一个主成分能够解释11种时间序列方差变异的51%
get_we(pca.lambdas_[:5])
get_we(pca.lambdas_)[:3].sum()
# 3 构造基于核PCA的动态风险指数
# 先做只包含一个主成分的指数
pca = KernelPCA(n_components=1).fit(df_data_imputer.apply(scale_function))
df_data_imputer['PCA_1'] = pca.transform(-df_data_imputer)
df_data_imputer.apply(scale_function).plot(figsize = (15, 8))
# 3个主成分的结果
pca = KernelPCA(n_components=3).fit(df_data_imputer.apply(scale_function))
pca_components = pca.transform(-df_data_imputer)
weights = get_we(pca.lambdas_)
df_data_imputer['PCA_3'] = np.dot(pca_components, weights)
df_data_imputer.apply(scale_function).plot(figsize = (20, 10))

# 4 验证各国股指和PCA的关系
import matplotlib as mpl
mpl_dates = mpl.dates.date2num(data.index)
mpl_dates
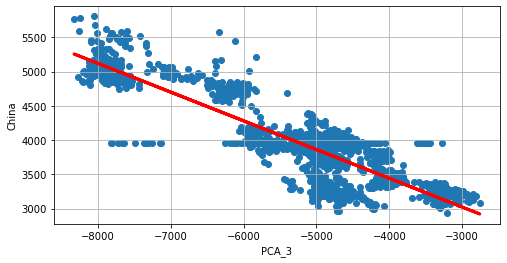
plt.figure(figsize=(8, 4))
plt.scatter(df_data_imputer['PCA_3'], df_data_imputer['China'])
lin_reg = np.polyval(np.polyfit(df_data_imputer['PCA_3'],
df_data_imputer['China'], 1),
df_data_imputer['PCA_3'])
plt.plot(df_data_imputer['PCA_3'], lin_reg, 'r', lw=3)
plt.grid(True)
plt.xlabel('PCA_3')
plt.ylabel('China')





















评论