眼见真的为实?技术检测“AI换脸术”是防范治理基础
【文/观察者网 尹哲 编辑/周远方】
常言道,眼见为实。然而,随着人工智能的迅猛发展,一些使用Deepfake(深度伪造)技术制作的换脸视频也在网络上屡见不鲜,该技术甚至被别有用心的人利用,成为诈骗、诬陷等罪恶勾当的工具,给社会和个人带来严重威胁。
7月9日,在2021WAIC世界人工智能大会上,北京瑞莱智慧科技有限公司(RealAI)发布DeepReal深度伪造内容检测平台。

瑞莱智慧副总裁唐家渝在演讲中表示:该检测平台能够通过研究深度伪造内容和真实内容的表征差异性辨识、不同生成途径的深度伪造内容一致性特征挖掘等问题,快速、精准地对多种格式与质量的图像进行真伪鉴别,为遏制和防范深度伪造技术的大规模滥用提供技术支撑。

特朗普电视直播曾中招
在接受采访时,瑞莱智慧副总裁唐家渝向观察者网指出,深度伪造技术持续进化,网络数字内容多变、隐匿性强,监管难度大,因此开展主动技术防范与检测工作是必要的。
所谓“深度伪造”,译自英语中新出现的一个组合词Deepfake,是计算机的“深度学习”(Deeplearning)和“伪造”(fake)的组合,出现于人工智能和机器学习技术时代。
众所周知,在2019年红极一时的换脸软件“ZAO”上,用户只需上传一张照片,就能秒变“戏精”,甚至还能与偶像同台飙戏,效果极其逼真;不久前,短视频领域出现的“蚂蚁呀嘿”热潮,其基础也是深度伪造技术。

这种技术被称作一种合成媒体(syntheticmedia),是通过自动化的手段、特别是使用人工智能的算法技术,进行智能生产,操纵、修改数据,最终实现媒体传播行为的一种结果。
通俗理解,“深度伪造”就是把图片和声音输入机器学习的算法,从而可以轻易地进行“面部操作”(facemanipulation)——把一个人的脸部轮廓和表情放置在其他任何一个人的脸上,同时利用对声音的逼真处理,制造出实为合成却看似极真的视频——用以躲避识别、混淆视听、娱乐用户,以及实现其他虚假宣传的目的。
近年来,非法利用AI技术伪造他人肖像吸引流量牟利,甚至从事侮辱、诽谤、网络诈骗、色情宣传等违法犯罪活动的案例已屡见不鲜。
唐家渝以美国前总统特朗普的一次电视直播意外举例。

在一次福克斯旗下的Q13电视台直播中,特朗普一直做出吐舌头的动作,之后信号被掐断。经电视台排查,编辑在直播中利用技术手段播放了伪造视频,最终涉事编辑被解雇。
2019年初,Facebook的CEO扎克伯格也遭遇被伪造,伪造者发布了宣扬侵犯个人隐私数据的不实言论,这些事件将Facebook、随后又将人工智能造假推向了社会舆论的风口浪尖。
此前,常州的王某报警称自己被裸聊诈骗11万余元。他出于好奇,接受了一名女网友请他下载某软件并提出视频邀请,挂电话后不久,王某就收到了一段有自己头像的不雅视频。骗子用AI换脸技术把他的脸合成到他人的视频上,并以此威胁其转账。

因此,基于深度伪造技术存在的社会风险,2020年5月28日,十三届全国人大三次会议表决通过《中华人民共和国民法典》中第1019条规定:“任何组织或者个人不得以丑化、污损,或者利用信息技术手段伪造等方式侵害他人的肖像权。未经肖像权人同意,不得制作、使用、公开肖像权人的肖像,但是法律另有规定的除外”。
该法规总体要求了禁止利用信息技术手段伪造的方式侵犯他人的肖像权和声音。
与此同时,美国、欧盟、德国、新加坡、英国等国也出台了相关的监管政策。
“魔高一尺”更需“道高一丈”
然而,不仅要在法律层面,AI作恶要有“紧箍咒”来约束;在技术层面,“魔高一尺”还要有“道高一丈”来抗衡。

唐家渝向观察者网指出,随着人工智能的广泛应用,整个产业面临的三大困境逐渐浮现:
第一是算法可靠问题。深度学习算法为黑盒,缺乏可理解的决策逻辑和依据,无法量化不同决策的可靠程度,导致难以应用至金融、医疗等高可靠性要求场景;同时,基于对抗样本攻击技术可以破解安防监控、手机刷脸解锁、人脸识别闸机等识别系统,实现身份伪装或隐身逃逸,为个人财产安全与社会公共安全带来全新挑战。
第二是数据安全问题。提升AI能力需要挖掘数据价值,但在特定AI应用场景中,所需要用到的数据往往涉及个人隐私信息,简单明文数据传输和利用很可能导致隐私泄露;而有价值的数据分散形成数据孤岛,在打破数据孤岛的过程中,数据用途和用量难以控制,存在被滥用和复制的可能,同时数据权属不明确,数据收益不清晰。
第三是应用可控问题。AI算法偏差导致不公平性问题,比如人脸识别算法存在种族歧视与性别歧视,AI信贷模型对特定地域人群的歧视等,缺乏有效衡量算法公平性的方法和工具;同时,AI技术的滥用引发道德伦理问题,比如深度伪造技术的滥用带来的个人和社会风险问题。

另外,深度伪造技术检测工作当前面临两大难点:
一是造假算法在不断丰富,伪造图像越发逼真。
最初的伪造视频其实是有一些反常识的特征的,比如一段1分钟的视频中,人没有眨一次眼睛,于是我们可以基于人体的生理特征去对人物的真假进行判定;但是自然而然地,造假者随后也通过在视频中随机生成眨眼动作,很大程度上逃避了这种检测方式。
另外,深度伪造的视频人物,为了与背景有比较好的融合,会对边缘进行简单的高斯模糊处理,而当检测算法基于这样的特征进行检测以后,伪造算法也对人脸边缘做了更精细化的处理。
二是利用深度学习的缺陷绕过检测算法。
通过在图片上添加对抗样本噪音,可能使得伪造视频躲避自动检测。
他坦言:“正是由于深度伪造治理有着巨大的挑战,势必需要有着深厚技术实力和AI对抗经验的团队,才能做出真正能落地的解决方案。”
据他介绍,DeepReal深度伪造检测平台算法基于大数据量进行训练和测试,截至目前,数据量已达到千万级,数据集已覆盖三大类,包括:学术深伪数据集、网络深伪数据集和自研深伪数据集。

同时,通过结合贝叶斯学习框架和深度神经网络,来估计模型在预测新样本时的不确定性。以上,有效保障了DeepReal深伪检测算法的泛化能力。
在测试结果方面,DeepReal在学术数据集和ZAO等主流方式生成的网络数据集中,已达到99%以上的准确率;在实际应用中,DeepReal的检测准确率也已达到业界顶尖水平,远超Facebook此前举办的Deepfake检测挑战赛所公布的最好成绩。
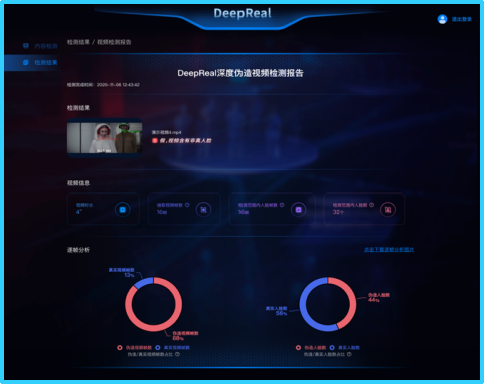
DeepReal深度伪造内容检测平台检测报告示意图
他补充道:该平台对于单张图像的检测耗时不到30毫秒,支持横向扩展与集群部署,适用于大规模实网落地。针对互联网环境中众多的深度伪造类型,平台也进行了全面的覆盖。包括针对真实人物的面部替换、表情操纵,以及完全合成的虚假人物等。
同时,实网环境中的伪造视频不断变化,需要有强对抗的手段加以遏制。
他介绍道,一是使结果具有可解释性,这样才能真正让人信服AI的检测结果是可靠的:“利用贝叶斯深度学习,我们将伪造视频的先验知识进行融合,同时能够输出更加准确的置信度,以此增加对预测结果确定性的预判;结合精细化的具有可解释性的数据集的标注和构建,能够使预测结果的确定性和可解释性都有很大提升”。
另外,要能够快速即时应对新型的深度伪造类型。除了贝叶斯深度学习,还利用了小样本增量学习的方法,使得在初期见到少量新型伪造数据时,便能迅速学习到伪造特征。
他指出:“我们对深度伪造的治理进行了全面的技术布局。比如实战环境中有音视频数据,所以我们会利用多模态分析算法综合分析;对抗环境中使用对抗学习技术,在部署环境中支持多模型和单模型,同时通过不确定量化和配合溯源技术提升可靠性。”
同时,为了进一步提升检测的可靠性,我们不仅做预测,更布局了溯源技术,进一步对深度伪造视频进行具有可解释性、可靠的综合治理。
“虽然成绩颇丰,但我们清醒地认识到针对深度伪造的风险,一定是需要从监管到研究再到落地实战进行全方位的治理。”最后,他呼吁:“我们积极与监管部门、科研机构、实战部门等进行合作,共建深度伪造治理生态。我也代表我们团队,诚挚邀请和欢迎社会各界机构和企业的加入。”
本文系观察者网独家稿件,未经授权,不得转载。


















评论