这是一份 AI 界最强年终总结
AI 科技评论按:年终总结可能会迟到,但不会缺席!
圣诞节+元旦假期过后,谷歌资深 Fellow、谷歌 AI 负责人 Jeff Dean 代表所有谷歌的研究部门发出了他们的 2018 年度科研研究年终总结。这一年,谷歌的科研人员们在人工智能、量子计算、计算图形学、算法理论、软件系统、TPU、开源软件与数据集、机器人技术、AI 应用、医疗保健等许多方面做出了许多新的成果,不仅有许多论文,更有许多实际的技术产品。雷锋网(公众号:雷锋网) AI 科技评论在 2018 年中也曾单独报道过其中的许多项目。
同样由 Jeff Dean 撰写的 2017 年谷歌大脑年终总结见这里:上篇、下篇。如今谷歌把人工智能的相关研究开发拓展到了新品牌「谷歌 AI」下面,曾经的谷歌大脑负责人 Jeff Dean 也就成为了谷歌 AI 的负责人。
现在我们把这篇 Jeff Dean 代表全体谷歌科研人员撰写的谷歌科研成果 2018 年年终总结全文翻译如下。

谷歌资深 Fellow、高级副总裁、谷歌 AI 负责人 Jeff Dean
对于谷歌的研究团队来说,2018 年又是充满激情和干劲的一年。我们的技术研究成果在许多个不同的方向上继续开花结果,包括计算机科学方面的基础科研成果和论文、科研结果在谷歌的更多新兴方向中的应用(比如医疗保健和机器人)、对开源软件的贡献以及和谷歌的产品开发团队之间的紧密协作,所有这些的目标都是为了创建更多有用的工具和服务。下面我们来一起看看 2018 的一些成果,以及对未来的一年做一些展望。更详细尽的汇总可以参见我们的 2018 年论文发表清单(https://ai.google/research/pubs/?year=2018)。
道德准则和 AI
在过去的几年中,我们共同见证了 AI 领域的重大进步,欣喜地看到了 AI 对谷歌的产品产生了积极的影响,这些产品也在日常生活中为谷歌的数十亿用户提供了更多帮助。对于我们这些在 AI 领域工作的人来说,我们非常在意 AI 是否成为了这个世界变得更好的推动力 —— 也就是说,它的使用是符合人类道德的,它用来解决的问题也是对这个社会有益的。2018 年我们发布了谷歌 AI 准则(https://ai.google/principles/),它也带有一系列负责任的 AI 应用的示范样本,描绘出了 AI 应用实践的技术指导。这些准则和示范也一同构成了评价我们谷歌自己的 AI 产品开发的体系框架,我们希望别的组织机构也能够运用这些准则规范他们自己的思路。需要说明的是,由于这个领域的发展速度飞快,我们在某些准则下提供的示范样本(比如「为了避免产生和加强不公平的偏见」、「为了对人类可解释」),也会随着我们在机器学习公平性和模型可解释性等新领域开展研究而不断变化、不断更新。这些研究研究成果反过来也会让谷歌的产品不断进步,让它们更具包容性、更少带有偏倚,比如我们就已经减少了谷歌翻译中的性别偏倚,也探索并发布了内容更为广泛多样的图像数据集和模型(https://ai.google/tools/datasets/open-images-extended-crowdsourced/),以便让计算机视觉模型在整个地球中更加多样化的环境中都可以工作。更进一步地,这些努力也让我们得以把最佳实践分享给更广泛的研究群体,比如我们的机器学习快速课程中的 Fairness Module。
造福整个社会的 AI
如今大家都已经知道,在社会的许多方面、在许多重要的社会问题上,AI 都有潜力带来剧烈的影响。我们在 AI 洪水预测方面的研究就是一个绝佳的例子,它展示了 AI 可以如何在真实世界的问题上帮助人类。在多个谷歌内部团队的合作下,这项研究的目标被定义为「为洪水发生的可能性和可能覆盖地区提供准确、细时间粒度的信息」,而那些在洪水高危地区生活的人们就可以根据这些信息作出更好、更及时的判断,能更好地保护自己、保护自己的财产。

洪水预警系统已经在印度的部分地区投入使用
另一个例子是我们研究如何预测地震的余震,我们展示了机器学习模型预测余震地址可以比传统的基于物理模型的方法准确得多。这项研究还有一个也许影响更为深远的方面,那就是因为我们设计的机器学习模型是具备可解释性的,科学家们得以在这个模型的帮助下对余震的活动作出更好的观察,这不仅让余震的预测变得更加准确,也让我们对余震本身有了更好的了解。
谷歌之外也有许多我们的伙伴。许多研究者和谷歌的研究员、工程师一起借助 TensorFlow 之类的开源软件钻研各种各样的科学和社会学问题,比如用 CNN 识别座头鲸的声音,发现新的系外行星,识别生病的木薯等等。
为了鼓励这个领域产生更多的新点子,我们与 Google.org 一同发起了「谷歌 AI 社会影响竞赛」,参加比赛的个人和组织研究需要一些从想法转化为现实之后可能会带来重大社会影响的项目,然后他们可以获得总数为 2500 万美元的资助资金,而且可以获得谷歌研究科学家、工程师、其它专家的指导。
辅助性技术
在我们围绕机器学习和计算机科学展开的研究中,有很大一部分都是希望帮助我们的用户们更快、更高效地达到他们的目标。通常这都需要科研团队和各种产品团队之间展开合作,研究成果也发布成为各种各样的产品功能和设置。其中一个例子是谷歌 Duplex(https://www.leiphone.com/news/201805/99jY3lvPZ9Oh2m7j.html),这个系统的建设需要我们把自然语言处理、对话理解、语音识别、文本转语音、用户理解以及高效的用户界面 UI 设计多个方面的研究成果集中整合,而它的最终效果是,只需要用户对着自己的手机询问「能不能帮我预定明天下午 4 点做头发」,一个虚拟助手就会替你打电话到理发店敲定相关的细节。
我还可以举一些例子,比如智能写作 Smart Compose(https://www.leiphone.com/news/201806/IcOGoDC98oKc5JZ6.html),这个工具会通过预测模型给出写作提示,帮助用户写作邮件,写作过程可以更快、更轻松;声音搜索 Sound Search,它构建在 Now Playing 功能的基础上,可以快速、准确地帮助用户找到环境中正在播放的音乐;还有安卓系统中的 Smart Linkify,它展示了我们可以使用运行在移动设备上的机器学习模型分析屏幕上正在显示的文本,理解文本内容之后把它划分为不同种类的小节,接着就可以直接点击文本访问对应的应用程序。
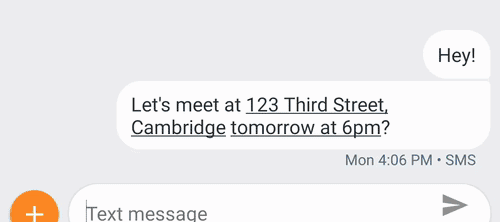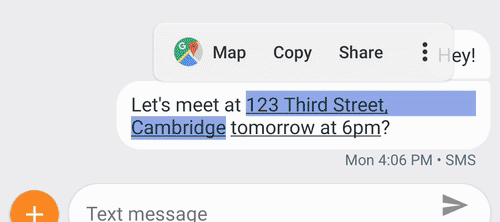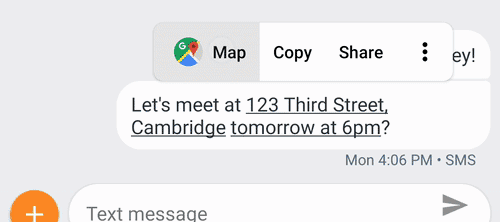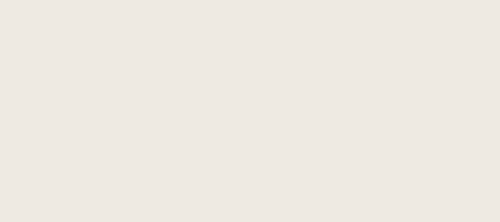
Smart Linkify 智能地把连续的文本分成了一段地址 + 一个时间
我们目前的研究中一个重要的关注点就是让谷歌助手这样的工具支持更多的语言,以及让系统更好地理解语义相似性,就是说即便使用了完全不同的方式来表达,我们也希望它能理解人们希望表达的概念和想法是相同的。我们在提升语音合成质量以及缺乏训练数据的文本转语音任务中的研究成果,未来也可能为谷歌的产品增加新的功能。
量子计算
量子计算是一种正在逐渐发展壮大的计算范式,它有能力解决经典计算机无法解决的非常困难的问题。在过去的几年中我们一直积极地在这个方向上进行科学研究,我们也相信,量子计算机展现出解决多种问题能力(所谓的量子霸权)的那个时刻即将到来,而这也将成为这个领域的分水岭。2018 年里,我们的量子计算实验产生了一系列令人兴奋的新成果,其中包括一个新的 72 位的量子计算设备 Bristlecone(https://www.leiphone.com/news/201803/Z6dmXG3LIdJoQgsr.html),它极大地拓展了量子计算机可以解决的问题的大小。我们距离量子霸权的距离越来越近了。

位于 Santa Barbara 的谷歌量子 AI 实验室中,研究科学家 Marissa Giustina 正在安装一块 Bristlecone 芯片
我们也发布了 Cirq,这是一个为量子计算机开发的开源编程框架,我们也借助它探索了如何在量子计算机上运行神经网络。最后,我们分享了研究量子处理器性能涨落的问题的及经验和技巧(https://www.leiphone.com/news/201809/BBu9s6FGJLm5Yq1y.html),也分享了关于「量子计算机有可能可以成为神经网络的计算性基础设施」的想法。2019 年里,我们期待在量子计算空间里做出更多惊喜的成果。
自然语言处理
对于自然语言处理领域,2018 年里谷歌收获颇丰,我们有许多科研成果,也有许多关注于产品的内部团队合作成果(https://ai.googleblog.com/search/label/Natural%20Language%20Understanding)。我们在 2017 年发布的 Transformer 基础上做了改进,得到了一个新的时间并行的模型版本,我们把它称作 Universal Transformer(前往https://www.leiphone.com/news/201808/1nhPCi9jWWNGv6aw.html阅读相关文章),它在包括翻译、语意推理等许多自然语言任务中都展现出了极大的性能提升。我们也开发了BERT,这是首个深度双向、无监督的语言表示,它只需要在普通的文本语料上预训练,然后就可以通过迁移学习精细调节到许多种不同的自然语言任务上。相比之前的最佳表现的模型,BERT 在 11 种自然语言任务中都取得了显著的表现提升。
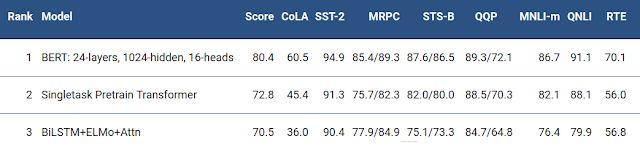
在极具挑战的 GLUE benchmark 中,相比之前的最佳水平模型,BERT 把分数的绝对值提升了 7.6%
除了和许多谷歌内部的产品团队合作开发了上文提到的 Smart Compose 和 Duplex 之外,我们也探索改进了谷歌助手,让它能够更好地处理多语言混用的场景。我们的最终目的是希望所有的用户都可以与它自然地用语言交流。
感知
我们在感知方面的研究攻克了让计算机理解图像、声音、音乐和视频等有难度的问题,同时也为图像捕捉、压缩、处理、创意表达以及增强现实提供了更多更有力的工具。2018 年,我们把新技术融合进了谷歌照片 app,它可以更好地整理用户在意的照片内容,比如人和宠物。谷歌 Lens 和谷歌助手则可以帮助用户了解自然世界、实时回答问题,谷歌图像中的 Lens 还有更多新功能。我们曾经表示过,谷歌 AI 的使命中有一个重要的方面就是要给人类赋能、让他们从技术中受益,这一年中我们也对谷歌 API 做了许多升级,改进了它的功能、更新了它的基础组件。一些例子包括谷歌云机器学习 API 中的视觉和视频的升级的新功能,以及通过 ML Kit 实现的许多运行在移动设备上基础组件,提供了面部识别相关一些功能。
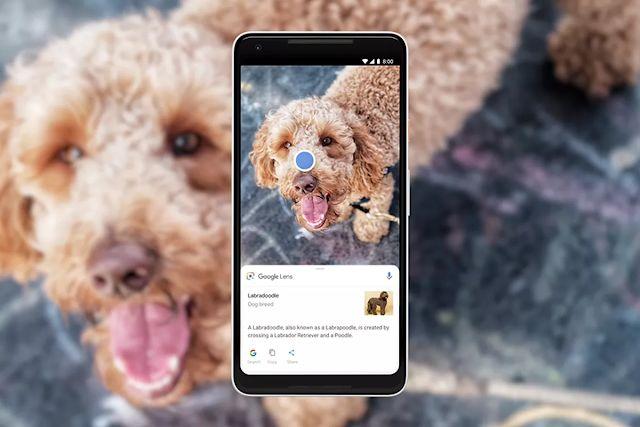
谷歌 Lens 可以帮助你更好地了解身边的世界。比如,Lens 就分辨出了这条小狗的种类
2018 年中,我们对学术研究的贡献包括了深度学习三维场景理解方面的进展,比如立体变换(stereo magnification,https://arxiv.org/abs/1805.09817),它可以为一个场景生成全新角度、而且具有逼真画质的图像。我们也有一些持续进行中的研究,可以更好地理解图像和视频,也就可以帮助用户更好地发现、组织、增强以及改进谷歌产品(谷歌图像、YouTube、谷歌搜索等)中出现的图像和视频。这一年中值得一提的改进包括:用于快速联合姿态估计以及人体实例分割的自底向上模型(https://arxiv.org/abs/1803.08225),一个用于复杂动作可视化的系统(http://mosculp.csail.mit.edu/),一个可以对人和物体之间的的时间-空间关系建模的系统(https://ai.google/research/pubs/pub47219),以及借助蒸馏(https://arxiv.org/abs/1812.08249)和 3D 卷积技术(https://ai.google/research/pubs/pub47220)改进视频动作识别。
在语音领域,我们提出了一种方法用于语义音频表示的无监督学习(https://ieeexplore.ieee.org/abstract/document/8461684),也提出了「高表现力、仿人类语音生成」的重大技术改进(Tacotron,https://arxiv.org/abs/1803.09047)。同时,多模态感知也是一个越来越重要的研究话题。「通过看来听」(https://arxiv.org/abs/1804.03619)综合了输入视频中的视觉和音频线索,然后可以抽取、增强视频中指定说话者的声音。这种技术有广泛的应用场景,从视频增强和识别、到视频通话、再到更好的听力辅助设备都可以运用,尤其适合同时有多个人说话的场景。
在资源有限的平台上实现感知也越来越重要。我们的第一代移动平台计算机视觉模型 MobileNets 已经在学术界和工业界得到了广泛应用,而我们也在 2018 年发布了第二代模型 MobileNetV2(https://arxiv.org/abs/1801.04381)。在 MorphNet (https://arxiv.org/abs/1711.06798)中,我们提出了一种高效的方法学习深度神经网络的架构,它在符合计算资源限制的情况下为图像和音频模型提供了全面的性能改进,而更新的自动网络生成方面的研究(前往https://www.leiphone.com/news/201808/7sF5igkvPVZyswor.html阅读相关报道)则表明了可以针对硬件设计表现更加优异的模型。
计算图像学
在过去的几年中,手机摄像头画质以及易用性的提升可以说是叹为观止。其中一部分改进自然来自于手机摄像头使用的感光器越来越先进,但同时更大的功劳在于计算图像学领域的科学技术改进。我们谷歌的研究团队发表了自己的最新研究成果,也和谷歌的安卓系统团队、消费级硬件团队紧密协作,把这项成果搭载在最新的 Pixel 手机以及其它的设备上,并最终送达用户手中。早在 2014 年,我们就发布了 HDR+ 技术,它让手机快速连拍多张曝光不同的照片,然后在软件中对齐这几张照片,并通过计算软件把它们合并为一张照片。最初 HDR+ 的设计目的是让照片具有比只拍一张照片更大的动态范围,后来,快速连拍多张照片并基于它们做计算性分析已经成了一种通用的模式,2018 年的手机摄像头基于这种模式开发了更多的功能,比如 Pixel 2 手机中的运动照片,以及动作静止照片中的增强现实模式。

动作静止照片中的增强现实模式中的一只小鸡
今年,我们在计算图像学研究上的主要努力是为手机摄像头开发了一种新的能力,夜视,可以让 Pixel 手机在夜里看得更清晰,这项功能也获得了媒体和用户的一致好评。当然了,夜视仅仅是谷歌团队开发的帮助用户拍出完美照片的众多功能之一,这些功能都基于软件、服务于摄像头,它们包括:用机器学习带来更好的人像模式照片,通过超级清晰变焦看得更清楚、更远,以及用 Top Shot 和谷歌 Clips 捕捉特殊瞬间。

左:iPhone XS;右:带有夜视功能的 Pixel 3 手机
算法与理论
算法是谷歌各个系统背后的支撑骨架,各种算法决定着从谷歌旅行的路程规划系统,到谷歌云的持续哈希系统等等的所有谷歌产品的表现。在过去的一年中,我们继续在算法和理论方面进行着深入的科学研究(https://ai.google/research/pubs/?area=AlgorithmsandTheory&year=2018),从理论基础到实用算法,以及从图挖掘(https://ai.google/research/teams/algorithms-optimization/graph-mining/)到保持隐私的计算方法。我们在优化算法方面的探索覆盖了许多领域,从用于机器学习的连续优化,到分布式的组合优化。在前一个领域,我们研究训练神经网络时的随机优化算法的收敛性的论文获得了 ICLR 2018 的最佳论文奖,这篇论文展示了热门的基于梯度的优化方法存在的问题(比如 ADAM 的一些变种),同时也为一些新的基于梯度的优化方法提供了扎实的理论基础。(https://ai.google/research/pubs/pub47409)
对于分布式优化问题,我们研究了如何改进组合优化问题中的轮数和沟通复杂度,比如通过轮数压缩(https://ai.google/research/pubs/pub46793)和核心组的图中的匹配(https://ai.google/research/pubs/pub46793),以及子模最大化(https://ai.google/research/pubs/pub46927)和 k 核分解(https://ai.google/research/pubs/pub47742)。对于更偏向应用的方面,我们开发了新算法解决通过草图大规模设定封面(https://ai.google/research/pubs/pub46927),以及解决具有万亿条边的图的平衡分区以及层次化分簇问题。我们研究在线投递服务的论文(https://doi.org/10.1145/3178876.3186104)得到了 WWW 2018 的最佳论文提名。还有,我们的开源优化平台 OR-tools (https://developers.google.com/optimization/)也在 2018 Minizinc 限定编程比赛中赢得了 4 面金牌。
对于算法选择理论,我们提出了一些新的模型(https://doi.org/10.1145/3159652.3159702),也对重建问题(https://doi.org/10.1137/1.9781611975031.38)和多项式分对数的学习问题(http://proceedings.mlr.press/v80/chierichetti18a.html)做了一些调研。我们也研究了神经网络可以学习到的函数的类型(https://doi.org/10.4230/LIPIcs.ITCS.2018.22),以及如何使用机器学习的思想改进经典在线算法(http://papers.nips.cc/paper/8174-improving-online-algorithms-via-ml-predictions)。
对于谷歌来说,了解一些有强有力的隐私保证的算法是有着重要意义的。在这样的背景下,我们开发了两种新的方法,通过迭代(https://ai.google/research/pubs/pub47118)和随机排序(https://ai.google/research/pubs/pub47557)进一步分析并增强差分隐私。我们也使用差分隐私技术设计可以感知动机的学习方法(https://ai.google/research/pubs/pub46913),它们在博弈中很鲁棒。类似这样的学习技巧都在高效的在线市场设计中得到了应用。我们在市场相关的算法领域也有一些新的研究,比如帮助广告商测试广告投放的动机兼容性的技术(https://ai.google/research/pubs/pub46968),以及优化 app 内广告的刷新方式的技术(https://ai.google/research/pubs/pub46847)。我们也在重复拍卖问题中把当前最优的动态机制又向前推进了一步,我们的动态拍卖对于缺少未来预期(https://ai.google/research/pubs/pub47744)、预测有噪声(https://ai.google/research/pubs/pub47745)、异质买家行为(https://ai.google/research/pubs/pub46969)等状况都可以保持鲁棒,我们的结果还可以拓展到动态双拍卖的场景中(https://ai.google/research/pubs/pub47734)。最后,在在线优化和在线学习鲁棒性问题中,我们开发了新的在线分配算法处理带有流量峰值的随机输入(https://dl.acm.org/citation.cfm?id=3105446),以及对损坏的数据鲁棒的修补算法(https://ai.google/research/pubs/pub47732)。
软件系统
我们对于软件系统的研究很大部分都继续与构建机器学习模型有着种种联系,尤其是与 TensorFlow 有许多联系。比如,我们针对 TensorFlow 1.0 发布了动态控制流的设计和实现(https://dl.acm.org/citation.cfm?id=3190551)。我们在后来的研究中介绍了一个称作 Mesh TensorFlow 的系统,通过它可以很方便地定义具有并行模型的大规模分布式计算,这样的系统可以包含多达几十亿个参数。另一个例子是,我们还发布了一个用于可拓展的深度神经排序的 TensorFlow 库。
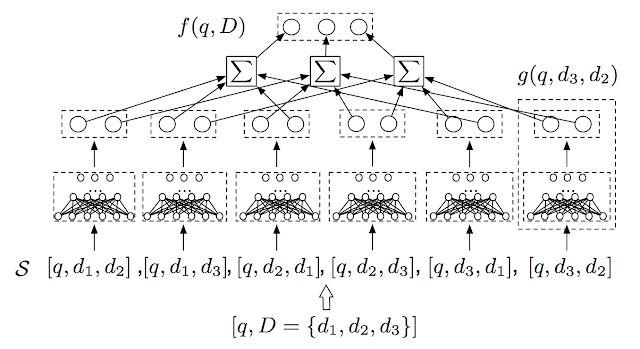
TF 排序库支持多项目评分架构,是传统的多项目评分的拓展
我们也发布了 JAX(https://github.com/google/jax),这是一个带有加速器的 NumPy 的变种,它可以支持 Python 函数的任意阶自动微分。虽然 JAX 并不包含在 TensorFlow 中,它所使用的部分底层基础软件其实是和 TF 相同的(比如 XLA,https://www.tensorflow.org/xla/),而且 JAX 的一些想法和算法也对 TF 起到了不小帮助。我们在机器学习的安全和隐私方面也做了更多研究,我们开发的安全、保证隐私的开源框架也用在了更多的 AI 系统中,比如 CleverHans (https://github.com/tensorflow/cleverhans)和 TensorFlow Privacy(https://github.com/tensorflow/privacy)。
我们看重的另一个研究方向是机器学习在软件系统中的应用,这可以发生在许多不同的层次上。比如,我们持续地研究用层次化模型向不同的设备分配计算任务(https://openreview.net/pdf?id=Hkc-TeZ0W),以及我们参与了学习内存访问模式的研究(http://proceedings.mlr.press/v80/hashemi18a/hashemi18a.pdf)。我们也继续探索如何用模型学习到的索引在数据库和存储系统中替代传统的索引结构(https://www.leiphone.com/news/201712/ribgRj0jjhYy9Qbq.html)。正如我在去年的总结中写的,对于如何在计算机系统中使用机器学习,我们目前的认识其实还处在非常早期。
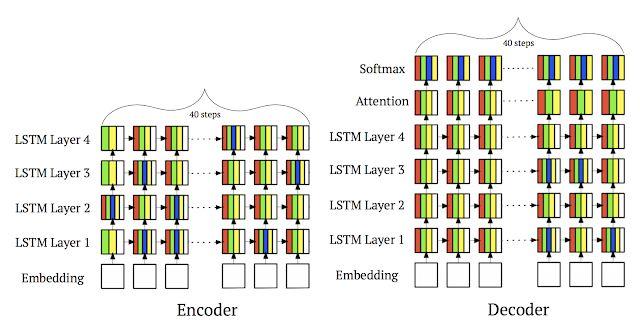
层次化分配器(https://openreview.net/pdf?id=Hkc-TeZ0W)对一个四层的神经机器翻译模型的计算量的分配。其中白色表示 CPU,四种不同的彩色表示 GPU。值得注意的是,每一层的每一步计算都是分配给了多个 GPU 在执行的。这种分配方式比人类专家设计的分配方式快 53.7%。
2018 年里我们也结识了 Spectre 和 Meltdown 这两个现代计算机处理器带有的严重安全漏洞,它们也正是在谷歌的零计划(Project Zero)团队与其他团队的合作中发现的。这些漏洞以及其它相关的漏洞着实让计算机架构研究人员们忙活了一阵子。在我们持续地对 CPU 的行为建模的过程中,我们的编译器研究团队把他们的测量机器指令延迟和端口压力的工具集成进了 LLVM 中,这让编译器得以做出更好的决定。
谷歌具有为计算、存储和网络构建大规模、可信赖、高效的技术架构的能力,谷歌的消费者产品、谷歌的云端服务以及机器学习模型的推理就都高度依赖于这种能力。在过去的一年中,这些方面的研究亮点包括谷歌最新进化的软件防御网络 WAN(https://ai.google/research/pubs/pub47191);一个独立工作、联邦式的查询处理平台,它可以在以不同的文件形式存储的数据上、在许多不同的存储系统上执行 SQL 查询语句(https://ai.google/research/pubs/pub47224);以及一个关于我们谷歌的代码审查做法的详细报告,包含了谷歌的代码审查背后的动机、目前的惯例、开发者的满意状况以及挑战(https://ai.google/research/pubs/pub47025)。
运行一个内容存储之类的大规模网络服务需要在不断变化的环境中做稳定的负载均衡。我们开发了一个持续的哈希方案(https://dl.acm.org/citation.cfm?id=3175309),它对于每一个服务器的最大负载有一个严密、可证明的保证,我们把它部署在了谷歌云的 Pub/Sub (https://cloud.google.com/pubsub/)上,为谷歌云的客户提供服务。在发布了最初版本的论文(https://arxiv.org/abs/1608.01350)之后,Vimeo 的工程师注意到了这篇论文,实现了它并把它开源到 haproxy,然后在 Vimeo 的负载均衡项目中使用它。它带来了显著的改进,这些算法思想的运用大幅降低了服务器缓存的带宽需求,几乎只有原先的 1/8,消除了一个重大性能瓶颈。
AutoML
AutoML 也被称作「元学习」,主要通过机器学习方式让机器学习的某些方面实现「自动化」。多年来我们一直在该领域进行研究,目标是开发出一个懂得借鉴过往积累的见解与能力,进而自动发现并解决新问题的系统。早期我们使用得最多的是强化学习,如今我们也将目光锁定在了进化算法上。去年,我们向大家展示了如何通过进化算法为视觉任务自动发掘最先进的神经网络架构。此外,我们也探索了强化学习在神经网络架构检索以外的更多作用,最后成功证明可用于下列问题的解决上:
1)自动生成图像变换序列,提高各种图像模型的准确性;
2)找到一种全新的符号优化表达形式,比起常用的优化规则效果更好。
我们在 AdaNet 的工作展示了如何创建一个学习效果有保障、使用上快速灵活的 AutoML 算法。
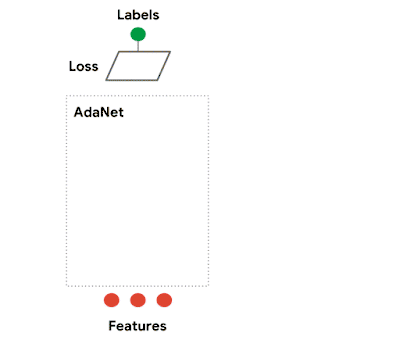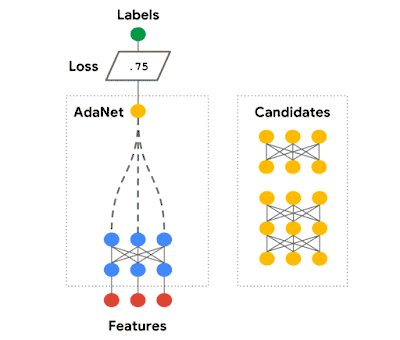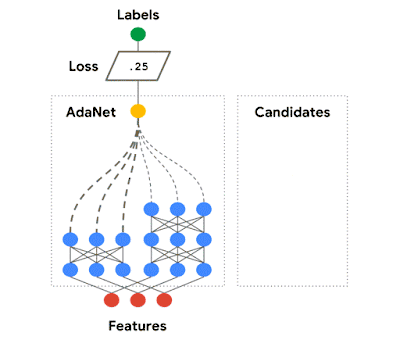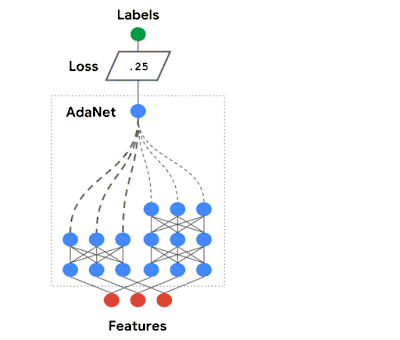
AdaNet 自适应地增强了神经网络的集成。它在每次迭代的过程中计算每个候选者的集合损失,再从中挑选最优秀的候选者进入下一轮迭代。
我们另外一项工作重点是自动发掘计算效率最高的神经网络架构,以便它们能在一些计算资源和推理时间有限的环境中(如移动电话、自动驾驶车辆等)运行。为此,我们证明只要在强化学习架构搜索的奖励函数中把模型的准确率与推理时间进行结合,就能找到既满足高度准确性又符合特定性能约束的模型。此外,我们还探索了如何通过 ML 来学习自动压缩 ML 模型,以更少的调试参数和计算资源消耗的方式。
TPUs
Tensor Processing Units (TPUs) 是谷歌内部自主研发的 ML 硬件加速器,最开始的设计初衷就是为了用于大规模的训练与推理上。TPUs 让谷歌的许多研究得以实现突破,比如广为人知的 BERT(前文提过),此外,通过开源的方式,它能让世界各地的研究人员对谷歌的研究进行拓展并实现突破。最典型的例子,任何人都可以通过 Colab 免费在 TPUs 上对 BERT 进行微调,这里要提一下 TensorFlow Research Cloud,它使数以千计的研究人员得以从大体量的免费云 TPU 供给的计算能力中受惠。此外,我们还将多代 TPU 硬件作为商用云 TPUs 对外出售,其中包括被称作 Cloud TPU Pod 的 ML 超级计算机,这使大规模的 ML 训练服务变得触手可及。仅就谷歌内部而言,除了让 ML 研究取得快速进步,TPUs 还推动了谷歌核心产品的重大改进,其中包括谷歌检索、YouTube、Gmail、Google 智能助理和谷歌翻译等。我们期待看到来自谷歌内部和其他地方的 ML 团队可以通过 TPUs,以其前所未有的计算规模在 ML 领域取得更多突破。

单个 TPU v3 设备(左)与 TPU v3 Pod 的部分部件展示(右)。TPU v3 是谷歌最新一代的 Tensor Processing Unit(TPU)硬件。它以云 TPU v3 的形式对外出售,采用液体冷却技术以获得最佳性能(计算机芯片 + 液体 = 太有意思了!),而完整的 TPU v3 Pod 将可以为全球最大的 ML 任务提供高达 100 petaflops 的计算能力。
开源软件与数据集
发布开源软件与创建全新的公共数据集,是我们为软件工程研究社区做贡献的最主要两种方式。这方面我们最大的贡献之一要属 TensorFlow,这是一款发布于 2015 年 11 月的 ML 计算系统,这些年来倍受欢迎。2018 年我们刚为 TensorFlow 庆祝完第 3 个生日,这期间 TensorFlow 已经被被下载超过 3000 万次,且有超过 1700 名的贡献者添加了 45 000 次的 commits。我们在 2018 年为 TensorFlow 更新了 8 个主要版本,增加了动态图机制和分发策略等主要功能。在研发过程中,我们启动了吸引社区注意力的公众设计评审活动,通过组建特殊兴趣小组留住贡献者。随着 TensorFlow Lite、TensorFlow.js 和 TensorFlow Probability 等产品的相继推出,TensorFlow 生态系统也在 2018 年迎来了大幅增长。
我们很高兴得知 TensorFlow 作为顶级机器学习和深度学习框架在 Github 上拥有强大的号召力。TensorFlow 团队也一直致力于实现快速解决 Github 上存在的问题,为外部贡献者提供更顺畅的操作通道。根据谷歌学术检索,我们已公开发表的论文持续为全世界的大部分机器学习和深度学习研究提供了有效支持。TensorFlow Lite 仅推出 1 年,便在全球超过 15 亿的设备上获得使用;成为 JavaScript 使用排名第一的 ML 框架;同时在对外放出的短短 9 个月内,已在 Github 获得超过 2 百万次的内容分发网络(CDN)点击量、20.5 万次下载量以及超过 1 万次的星星点亮。
除了继续耕耘现有的开源生态系统,2018 年我们还做了以下事情:
引入一个用于灵活、可再现强化学习的全新框架
https://ai.googleblog.com/2018/08/introducing-new-framework-for-flexible.html
引入一个可以快速习得数据集特征的可视化工具(无需编写任何代码)
https://ai.googleblog.com/2018/09/the-what-if-tool-code-free-probing-of.html
增加一个涉及 learning-to-rank 算法(以最大化整个列表效用的方式对项目列表进行排序的过程,适用于包括搜索引擎、推荐系统、机器翻译、对话系统甚至是计算生物学等领域)的高级机器学习问题库
http://ai.googleblog.com/2018/12/tf-ranking-scalable-tensorflow-library.html
发布一个快速、灵活的 AutoML 解决方案框架
发布一个通过 TensorFlow.js 执行浏览器实时 t-SNE 可视化工作的库
增加用于处理电子医疗数据(会在本文医疗保障环节提到)的 FHIR 工具 & 软件
针对完整 MNIST 数据集的 tSNE 嵌入实时演变过程。该数据集包含 60,000 个手写数字图像。现场演示请点击:https://nicola17.github.io/tfjs-tsne-demo/
公共数据集是触发灵感的绝佳来源,可带领许多领域取得重大进步,因为公共数据集能够为社区带来有趣的数据和问题,并在许多任务的解决上形成有益的竞争氛围。今年我们很高兴能够发布谷歌数据集检索工具(Google Dataset Search),这是一款可以让我们从各个网络渠道查找想要的公共数据集的全新工具。从数百万的通用注释图像或视频数据集、到用于语音识别的孟加拉人群源数据集、再到机器人手臂抓取数据集,这些年我们策划并发布了多个崭新数据集,即使在 2018 年,数据集的清单也还在不断增加中。

通过 Crowdsource 软件添加到 Open Images Extended 的图片(源自印度 & 新加坡)
我们还发布了 Open Images V4,这是一个包含 15.4 M 基于 600 种类别多达 1.9 M 图像的边框数据以及 30.1 M 源自 19,794 种类别的人工验证图像级标签的数据集。我们通过 crowdsource.google.com 为数据集添加了 5.5M 由世界各地数百万用户提供的生成注释数据,有效丰富了数据集在人和场景方面的多样性。我们还发布了具备视频视听注解功能的 Atomic Visual Actions (AVA) 数据集,可以有效提升机器理解视频中人类的行为与语言的能力。此外,我们还官宣了最新的 YouTube-8M 挑战赛和第二届 YouTube-8M Large-Scale Video 理解挑战赛与 Workshop。其他发布的数据集,如 HDR + Burst Photography 旨在为计算摄影领域的各种研究提供帮助;Google-Landmarks 是一个作用于地标识别的全新数据集。除了发布数据集,我们还探索了相关的一些新技术,比如 Fluid Annotation 可以让我们快速创建可视化数据集,通过一种探索性的 ML 驱动接口实现更快的图像注释行为。
Fluid Annotation 基于 COCO dataset 图像的可视化效果。图片来源:gamene,原始图片。
我们时不时还会给研究界树立新挑战,以便聚合大家一同来解决棘手的研究问题。一般来说,我们会通过发布新的数据集来达到这个目的,但也有例外的时候。比如今年,我们就围绕包容性图像挑战赛制定了全新的挑战,致力于创造免除偏见、更具鲁棒性的模型;iNaturalist 2018 挑战赛旨在让计算机得以细致区分物体的类别(如图像中的植物种类);在 Kaggle 上发起的 "Quick, Draw!" Doodle Recognition 挑战赛试图为 QuickDraw 游戏创建更好的分类器;还有 Conceptual Captions 作为大规模的图像字幕数据集挑战赛,旨在推动更好的图像字幕模型研究。
机器人学
2018 年,我们在理解机器学习如何教机器人行动这个目标方面取得了重大进展,在教机器人掌握新事物的能力方面达到了新的里程碑(2018 年 CORL 的最佳系统论文)。我们还通过结合机器学习和基于采样的方法(2018 年 ICRA 的最佳服务机器人论文)以及研究机器人的几何构造,在机器人运动学习方面取得了进展。我们在机器人通过自主观察更好地感知世界结构这一能力上取得了很大的进步。我们第一次成功地在真正的机器人上在线训练了深层强化学习模型,并且正在寻找新的理论方法,学习控制机器人的稳定方法。

人工智能在其他领域的应用
2018 年,我们将深度学习应用于物理和生物科学的一系列问题中。使用深度学习,我们可以为科学家提供相当于数以百计的挖掘数据研究助理,从而提高他们的创造力和生产力。
我们关于神经元高精度自动重建的论文提出了一个新的模型,与以前的深度学习技术相比,它将连接体数据(connectomics data)自动解释的准确性提高了一个数量级。
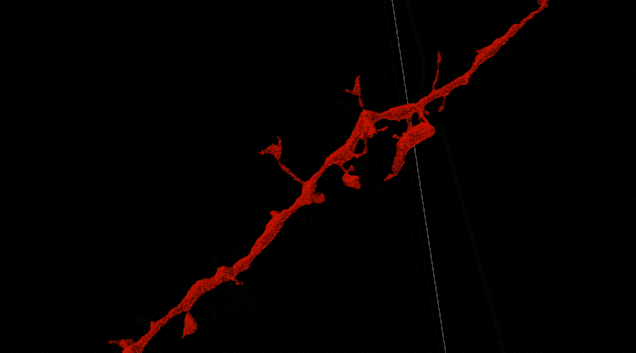
图为我们的算法正在跟踪鸣禽大脑中的一个神经突触
将机器学习应用于科学的其他一些示例有:
通过对恒星的光曲线数据进行挖掘,发现太阳系外的新行星
识别短 DNA 序列的起源或功能
自动检测离焦显微镜图像
用数字技术构建同一个细胞带有污点的图像
自动绘制肽链的质谱分析图
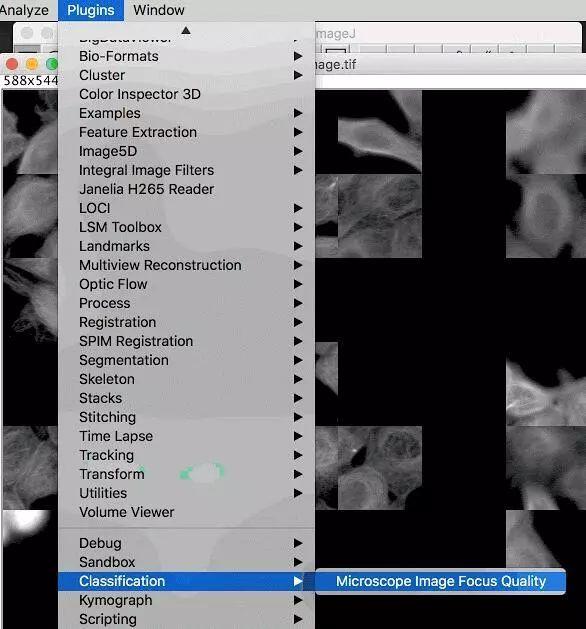
在 Fiji(图像 J)里面,一个 TensorFlow 模型对显微镜细胞拼接图像的聚焦质量进行了评估。边界的色调表示预测的焦点质量,边界亮度表示预测的不确定性。
健康
在过去的几年中,我们一直在将机器学习应用于健康领域,这一领域影响着我们每一个人,我们相信通过机器学习可以增强专业医疗人员的直觉和经验,从而为医疗领域带来巨大的改变。我们一般会与医疗保健组织合作,解决基础研究问题(利用临床专家的反馈使我们的结果更加可信),然后将结果发表在权威的同行评审的科学和临床期刊上。一旦研究得到临床和科学验证,我们就进行用户和 HCI 研究,以了解在现实的临床环境中如何部署它。2018 年,我们将临床任务预测也纳入了计算机辅助诊断的领域。
在 2016 年底,我们发表的研究表明,在一项回顾性研究中,接受过糖尿病视网膜病变体征视网膜底图像评估训练的模型在这项任务中的表现比美国医学委员会认证的眼科医师略好。2018 年,我们能够证明,通过让视网膜专家对培训图像进行标记,并使用一个判定方案(在该方案中,多个视网膜专家聚集在一起,对每个眼底图像进行一次单独的集体评估),我们可以得出一个与视网膜专家相当的模型。后来,我们发表了一份评估报告,展示了眼科医生如何利用这种机器学习模型,使他们做出比单独做出比不使用机器学习时更准确的决定。我们已经在印度的 Aravind 眼科医院和泰国卫生部附属的 Rajavithi 医院等 10 多个地点与我们 Alphabet 的同事合作,共同部署了这种糖尿病视网膜病变检测系统。
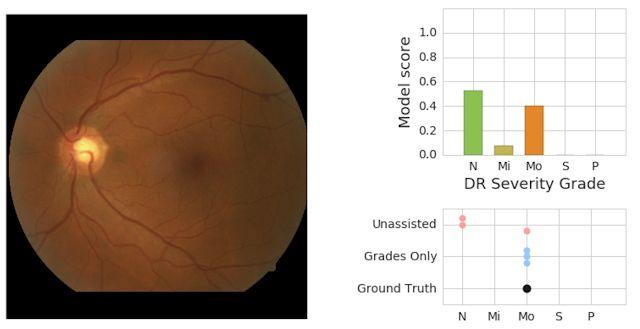
左侧是一张视网膜眼底图像,被眼科专家评审小组评定为中度 DR(「MO」)。右上角是模型预测得分的图示(「N」=无 DR,「MI」=轻度 DR,「MO」=中度 DR)。右下角是医生在没有帮助的情况下给出的一组分数。
我们还发表了一个机器学习模型的研究,这个模型可以通过视网膜图像评估心血管病患病风险。这是一种新型的无创生物标记方法,它可以帮助临床医生更好地了解患者的健康状况。
我们今年还继续关注病理学,展示了如何使用机器学习改善前列腺癌的分级,通过深度学习来检测转移性乳腺癌,并开发了一个增强现实显微镜的原型,它可以通过将从计算机视觉模型中获得的视觉信息实时叠加到显微镜学家的视野中,辅助病理学家和其他科学家的工作。
在过去的四年中,我们在利用电子健康记录数据进行深度学习,从而做出临床相关预测方面做了大量的研究工作。2018 年,我们与芝加哥大学医学院、加州大学旧金山分校和斯坦福大学医学院合作,并将研究成果发表在《自然数字医学》杂志上。我们的研究是关于如何将机器学习模型应用于未识别的电子病历中,与当前的最佳临床实践相比,它可以对各种临床相关任务做出更准确的预测。作为这项工作的一部分,我们开发了一些工具,使得在人物差异很大,底层 EHR 数据集也非常不同的情况下,创建这些模型变得更加容易。我们开发了快速医疗保健协作资源(Fast Healthcare Interoperability Resources (FHIR))标准相关的开源软件,以帮助更容易和更标准化地处理医疗数据(请参阅此 Github 代码库)。最近,团队与合作伙伴共同努力,在《Nature Biotechnology》上发表了同行评议论文。
在将机器学习应用于历史收集的数据时,重要的是要了解过去经历过人类结构偏差的人群,以及这些偏差是如何在数据中编码的。机器学习提供了一个机会来检测和解决偏见,并积极推进健康公平,这也正是我们正在努力推进的一个方面。
研究推广
我们采用了许多不同的方式与外部研究团体互动,包括教师参与和学生支持。我们很荣幸接收数百名本科生、硕士和博士生作为实习生,并为北美、欧洲和中东地区的学生提供多年的博士奖学金。除了财政支持,每个奖学金获得者都被指派一个或多个谷歌研究人员作为导师,我们召集所有的研究员参加一年一度的谷歌博士奖学金峰会,在那里他们可以接触到谷歌正在进行的最先进的研究,并有机会与谷歌的研究人员以及其他来自世界各地的博士生建立联系。可以查看视频:https://youtu.be/7RcUokN_eCg。
Google AI 实习生服务是这项奖学金计划的补充,它的形式是,让想要学习进行深度学习研究的人花一年时间与 Google 的研究人员一起工作并接受指导。2018 年是这项服务的第三年,全球的谷歌员工都加入了不同的团队,从事机器学习、感知、算法和优化、语言理解、医疗保健等领域的研究。目前该项目第四年的申请已经结束,我们很期待看到研究人员在 2019 年将进行的研究。
每年,我们还通过我们的 Google Faculty Research Awards 计划为一些研究项目的教员和学生提供支持。2018 年,我们还继续在谷歌(Google)为特定领域的教职员工和学生举办研讨会,包括在印度班加罗尔办事处举办的人工智能/机器学习研究与实践研讨会、在苏黎世办事处举办的算法与优化研讨会、在桑尼维尔举办的机器学习医疗保健应用研讨会、在剑桥举办了关于公平与偏见的研讨会。
我们认为,公开向对广泛的研究群体作出贡献是支持健康、高效的研究环境的关键部分。除了开放源代码和发布数据集之外,我们的大部分研究成果都在顶级会议和期刊上公开发布,我们还积极参与各种不同学科范围的会议组织和赞助。我们参与了 ICLR 2018、NAACL 2018、ICML 2018、CVPR 2018、NEURIPS 2018、ECCV 2018 和 EMNLP 2018。同时,2018 年谷歌还广泛参与了 ASPLOS、HPCA、ICSE、IEEE Security & Privacy、OSDI、SIGCOMM 等会议。
新地方,新面孔
2018 年,我们很高兴地迎来了许多具有不同背景的新人加入我们的研究机构。我们宣布成立在非洲的第一个人工智能研究实验室,它位于加纳共和国的首都阿克拉。我们扩大了在巴黎、东京和阿姆斯特丹的人工智能实验室规模,并在普林斯顿开设了一个研究实验室。我们将继续在全球各地的办公室招聘人才,您可以了解更多有关加入我们的信息。
展望 2019 年
这篇博文只总结了 2018 年我们进行的研究的一小部分。回顾 2018 年,我们为我们所取得成就的广度和深度感到兴奋和自豪。2019 年,我们期待对谷歌的方向和产品产生更大的影响,也期待着对更广泛的研究和工程界产生更大的影响!
via:
https://ai.googleblog.com/2019/01/looking-back-at-googles-research.html
















评论