想知道哪些RL技术用在了增材制造中,不妨看下这篇文章
机器之心分析师网络
作者:Wu Jiying
编辑:H4O
本文作者结合三篇近期的研究论文,简述了在增材制造(3D打印)领域中强化学习方法的应用。增材制造通过降低模具成本、减少材料、减少装配、减少研发周期等优势来降低企业制造成本,提高生产效益。因此,增材制造代表了生产模式和先进制造技术发展的趋势。
0 引言
我们在这篇文章中讨论一个加工制造领域的问题:增材制造(Additive Manufacturing,AM)。增材制造(Additive Manufacturing,AM)俗称 3D 打印(3D Printing),是一种融合了计算机辅助设计(Computer-aided design,CAD)、材料加工与成型技术,以数字模型文件为基础,通过软件与数控系统将专用的金属材料、非金属材料以及医用生物材料,按照挤压、烧结、熔融、光固化、喷射等方式逐层堆积,制造出实体物品的制造技术[1]。相对于传统的减材制造(Subtractive Manufacturing)技术,增材制造是现代工业范式的一种有效的数字方法,已经在全世界范围内得到了广泛的关注。增材制造通过离散 - 堆积使材料逐点逐层累积叠加形成三维实体,具有快速成形、任意成型等特点。
通过利用 3D 计算机辅助设计模型逐层累积叠加制造物体,增材制造具有以下优点[2]:(1)它能创造出具有复杂形状的产品,例如拓扑优化结构,这些产品利用传统的铸造或锻造工艺是很难实现的;(2)它可以用于生成材料的新特性,如位错网络(dislocation networks)[2],这对于学术研究人员来说是非常有意义的;(3)它能够减少材料浪费,能够为工业生成节省成本。不过增材制造本身还存在一些问题,与传统的通过减材制造技术生成的铸造和锻造零件中出现的缺陷不同,AM 零件中存在的缺陷包括:由于缺乏融合和气体夹带而产生的孔隙,相对于印刷方向的垂直和平行方向的严重各向异性的微观结构,以及由于高冷却速度和大温度梯度的巨大残余应力而导致产生的变形等。因此,更好地理解粉末的冶金参数、印刷工艺以及 AM 零件的微观结构和机械性能之间的复杂关系至关重要,也是推广应用增材制造技术的关键。
增材制造涵盖了多种成形方式,有激光增材制造(Laser Additive Manufacturing,LAM )、电子束增材制造(Electron beam additive manufacturing,EBM)以及电弧增材制造(Wire Arc Additive Manufacture,WAAM)等粉末床熔成型(Powder Bed Fusion ,PBF)方法,还有黏合剂喷射(Binder jetting,BJ)、熔融沉积式 (Fused Deposition Modeling,FDM)材料挤出成型方法等。其中,LAM 是目前应用比较多的工艺,已经应用于一些结构复杂、尺寸较小、表面精度高的零部件打印中。但是,一些定制大尺寸、强度高的零部件不适于用 LAM 成形。针对这些更大型、性能要求更高的零部件,WAAM 则是首选。作为示例,具体的粉末床熔成型 AM 技术路线分类图如图 1 所示[4]。

图 1. AM 技术分类[4]
我们在这篇文章中,并不具体探讨 AM 技术中存在的问题与改进方式,而是聚焦于强化学习(Reinforcement Learning)在 AM 中的应用。近年来,强化学习已经成为解决相对高维空间中复杂控制场景的一种有效方法,并应用于不同的场景中。其中,深度强化学习(Deep RL,DRL)是一种深度学习方法,它通过收集模拟环境中的经验和反馈,反复改进最初的随机控制策略。强化学习算法在解决未知工艺参数和动态变化的条件方面显示出巨大的优势,因为它们能够利用更丰富的信息来告知决策过程。在增材制造领域中,RL 也可用于构建复杂的控制策略以解决缺陷形成问题,以及多材料复合过程的过程质量监控、学习 - 纠偏、多设备调度等问题。
我们根据三篇近期发表的论文一起来了解增材制造中的强化学习。其中,第一篇文章针对原位工艺学习和控制问题,提出了一种基于模型的强化学习与矫正框架。该框架可以应用于机器人电弧增材制造的过程控制,以使得打印零件具有更好的表面光洁度和更多的近净形状(near-net-shape)的输出[5]。第二篇文章提出了一种提高激光粉末熔床产品质量的深度强化学习方法。通过迭代优化策略网络以最大化熔化过程中的预期奖励,可通过近端策略优化(Proximal Policy Optimization,PPO)算法生成能够减少缺陷形成的控制策略[6]。第三篇文章主要是使用光纤布拉格光栅(fiber Bragg grating,FBG)作为声学传感器对 AM 过程进行现场和实时监测,并使用强化学习(RL)进行数据处理,是 RL 在 AM 现场监测中的应用[7]。
1 基于模型的强化学习与校正框架在机器人电弧增材制造过程控制中的应用[5]

1.1 背景介绍
电弧增材制造(Wire Arc Additive Manufacturing,WAAM)是一种定向能量沉积制造技术,利用运动系统在基体上逐层构建金属零件。通常情况下,它利用电弧作为能量来源,电线作为原料,工业机器人手臂作为运动系统。最近,这种技术由于其高沉积率和低买飞比(buy-to-fly ratio),在生产近净形(near-net-shape)的大型金属零件方面得到了学术界和工业界越来越多的关注。WAAM 通过在水平(多道(multi-bead))和垂直(多层(multi-layer))方向沉积重叠的焊珠来构建 3D 零件,每个沉积层都作为后续层的基底。因此,重要的是要确保打印层质量足够高,以便为后续层的沉积提供一个较好的基底。不规则的层表面通常会导致几何误差的累积,随着打印的垂直推进而导致不理想的凹 / 凸表面,如图 2 所示。

图 2. 单道(single-bead)方法通常不够精确,无法预测 3D 打印的输出行为,通常会导致累积误差(如图中示出的不规则或凹凸表面光洁度)。另一方面,多层多道(multi-layer multi-bead,MLMB)方法开销相当大。本文的工作为多层多道工艺提供了一种经济有效的方法,即在打印实际零件时通过现场学习不断改进,从而获得更好的表面光洁度和更接近近净形(near-net-shape)的输出。
为了解决 MLMB 打印的单道模型不准确性问题,研究人员引入了基于视觉的复杂控制方法,通过实时调节工艺参数和沉积,以提高打印输出的质量。然而,实施这样的反馈控制需要开发一个复杂的在线监测系统,由于存在高强度焊接电弧,该系统容易出现噪声和不准确的情况。此外,还可以通过层间铣削(inter-layer milling)来达到所需的表面平整度。但是这种混合制造方法由于混入了传统的减材制造工艺,会造成时间和材料的浪费,从而影响了 WAAM 制造工艺本身的成本效益和优势。
本文提出了一个用于 MLMB 打印的综合学习校正框架(an integrated learning-correction framework),该框架引入了基于模型的强化学习方法。在该框架中,过程模型被反复学习,随后被用来补偿每一层的平整度误差,"原位(in situ)" 补偿。这样做的好处是,这个学习框架可以与零件的实际打印结合起来使用(因此是 in situ 的),最大限度地减少了所需的前期训练时间和材料浪费。作者表示,这项工作是一项初步研究,也是向机器人 WAAM 的原位学习范式迈出的第一步,目的是促进 MLMB 工艺研究,在保证执行和交付制造功能的前提下提高打印质量。
1.2 基于模型的强化学习方法介绍
根据强化学习理论,时间步骤 t 内的 agent 状态为 s_t,采取某些动作 a_t 后,会得到奖励 r_t=r(s_t,a_t),并根据未知的动态函数 f:SxA→S 转换到下一个状态 s_t+1。强化学习的目标是在每个时间步骤中学习一个策略,该策略能够使 agent 采取使未来奖励总和最大化的动作。上述方法可以在已知和未知环境动态模型的情况下实现,分别称为基于模型(model-based)和无模型(model free)的 RL,每一种方法都有自己的优点和缺点。
无模型 RL 的优点是能够对广泛的任务进行策略学习,缺点是它需要非常多的样本数据才能有效。而基于模型的 RL 的样本效率更高,但需要对环境动态有一定了解。作者分析,由于原位 WAAM 工艺研究的学习框架的目的是要求系统能够根据最初的几个样本学习后就能够学习到准确的工艺输入 - 打印输出关系,因此基于模型的 RL 更适合于本文讨论的工作。
在基于模型的 RL 中,使用系统动态模型来进行预测,随后使用该模型进行动作选择。令 ^f_θ表征学习到的离散时间动态函数。通过解决优化问题,可以确定未来 H 个时间步骤的动作:
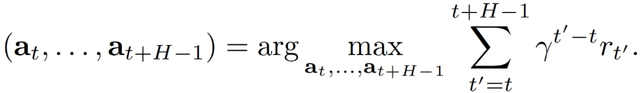
动态函数 ^f_θ可以通过交替收集 N 个新的数据点和使用汇总的数据重新训练模型来迭代学习,以减弱噪声,从而提高模型的预测性能。
1.3 综合学习校正框架介绍
图 3 给出了本文提出的利用 Kriging 动态函数的 WAAM 过程的综合学习校正框架。框架中的 agent 表示打印层路径上的一个离散点(waypoint)。状态空间 s_t 包括可观察到的打印输出行为(高度、宽度、温度、声音等),动作空间 a_t 包括可能的输入工艺参数(割炬速度、送丝率、喷嘴到基材的距离、割炬角度等)。所有 agents 的共同目标是实现均匀的表面高度。
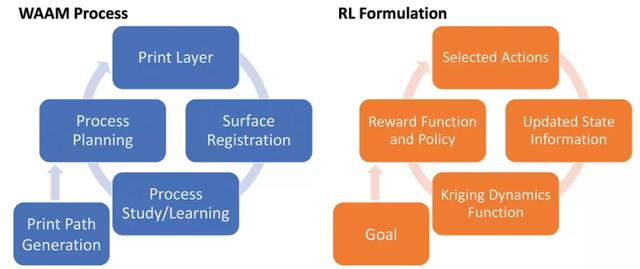
图 3. 本文所提出的应用于 WAAM 过程的综合学习矫正框架(左)和相应的 RL 表达式(右)
1.3.1 第一次迭代初始化
对于第一次迭代,通常采取随机动作并用于初始化第一个训练数据集。然而,焊接是一种危险的操作,在其可接受的工艺参数之外操作是不安全的。因此,作者将动作空间限制在焊接过程窗口内,即焊接过程参数的下限和上限范围内,而且这个上限、下限值对于不同的材料是不同的。
1.3.2 学习动态函数
1) 训练数据集。为了学习动态函数,需要建立一套训练数据集。由于打印路径是一个连续的轨迹,在将该轨迹其离散为 waypoints 后产生了多个 agents,每个 agent 都有自己的局部状态,并可以被分配独立的动作。因此,作者采用了一个针对多 agent 的并行 RL 框架,其中打印路径上的 waypoints 作为多个 agents 并行学习相同的任务,并汇集他们的经验进行训练更新,从而提高了学习率。训练数据集后,每个打印层都为:
![]()
其中,n_t 表示每个时间步骤(层)t 的 agents 的数目。agent 可以在每个时间步骤中进入和离开(即被更新),以适应打印复杂几何形状的层间打印路径的变化。
2)Kriging 动态函数。在过程建模中,神经网络一直是单道过程研究中常用的方法。作者将学到的动态函数 ^f_θ参数化为高斯过程回归(Gaussian Process Regression,GPR)模型,也被称为 Kriging 模型,该模型在有噪声的观察和小数据集的情况下能够实现更好的预测。
GPR 模型是根据观察到的输入 - 反应对 (X, Y) 构建的。该模型根据输入空间中的评价点的定位,预测未评价的输入 X 的反应 Y。假定观察到的和未观察到的反应(Y 和 Y),都具有有限维的高斯分布。基于贝叶斯定理,高斯分布 P 表示为
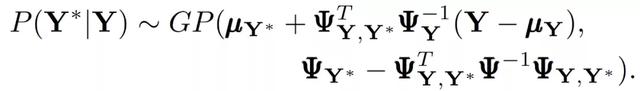
其中,平均值的集合,μ,可以用多项式回归模型βH 表示,H 是一组设计参数的基础函数,可以采取任何顺序,β是相应的系数向量,其先验为高斯β~GP(b,B)。最优预测为:
![]()
预测方差为:
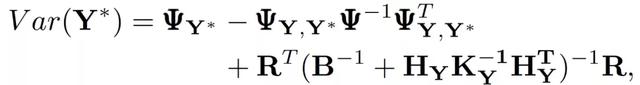
![]()
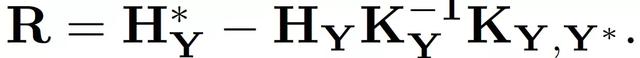
基于 Kriging 模型,我们可以学习一个动态函数,预测在动作 a_t 下 agent 的状态 s_t 的变化,即:

其中,学习过程使用的是累积的训练数据集 D_T。
1.3.3 目标描述
在强化学习中,目标(goal)定义了 agent 需要达到的状态。在打印完第 t 层后,通过扫描顶层获得表面点云 z_t(x; y)来量化该层的表面质量以及进行必要的修正。为了更新时间步骤 t+1 的目标,将下一层的打印路径切片化处理后根据扫描层的最大高度 z_t,max 生成三维 CAD 模型。作者将一个简单的交替方向策略应用于打印路径,以减轻电弧撞击和熄灭的影响[8]。全部 agents 的共同目标是实现统一的表面高度:
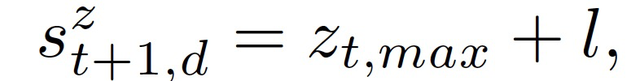
其中,l 表征打印下一层后的预期打印高度增量。
1.3.4 奖励函数和策略
奖励函数是这样制定的:如果 agent 选择了预计会导致偏离预期目标状态的动作时,就会受到惩罚。agent 得到的奖励是来自所学动态函数的预测σ_θ的预测标准偏差的加权 k 值,以鼓励 agent 进行小范围内的探索,特别是在最初的学习迭代过程中。每个 agent i 的奖励函数定义为:
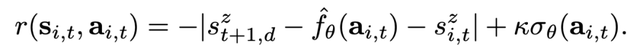
此外,在奖励函数中也纳入 agent 当前的高度状态(s^z)_i,t,因此鼓励每个 agent 选择实现下一个目标状态的动作,同时纠正自己当前与上一个目标状态的偏差。根据奖励函数,每个 agent i 会根据贪婪策略选择奖励最大化的行动,即
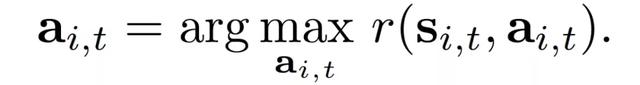
针对本文所述问题中涉及到的非线性动力学函数,作者采用非概率的系统抽样方法进行求解:从动作窗口的下限开始,以固定的抽样间隔生成 K 个候选动作集,直到上限结束。学习完成后,使用学到的动力学函数预测相应的状态、计算奖励,并选择具有最高预期奖励的候选动作集。
Algorithm 1 总结了用于 WAAM 的现场工艺研究和控制的基于模型的并行强化学习方法。在打印一个全新的零件但继续学习的情况下,第 1 行和第 2 行可以省略。

1.4 实验环境设置
为了证明和评估所提出的用于过程研究和控制的综合学习 - 纠正框架的可行性,作者在新加坡科技大学(SUTD)开发的机器人 WAAM 系统上实施了该框架,如图 4 所示。该系统包括一个机器人操纵器(ABBIRB 1660ID),一个配备焊枪(Fronius WF 25i RobactaDrive)的焊接电源(Fronius TPS 400i),一个由三个线性轨道(PMI KM4510)组成的笛卡尔坐标机器人,由三个舵机(SmartMotorSM34165DT)驱动,以及一个 2D 激光扫描仪(Micro-Epsilon scan-CONTROL 2910-100)。龙门系统被控制在三维空间中移动线型激光扫描仪,以获得打印层表面的三维点云。

图 4. 新加坡科技设计大学(SUTD)开发的机器人 WAAM 系统
为了初步评估所提出的学习框架,作者把焊枪速度和送丝速度作为 agent 的动作,把打印高度作为观察到的 agent 状态,因为它们是已知的影响打印行为的关键变量和参数,对于调节打印动作至关重要。如图 5 所示,agent 的局部状态是从打印表面的激光扫描输出中获得的,方法是取距 agent 半径δ毫米内的打印高度的平均值。
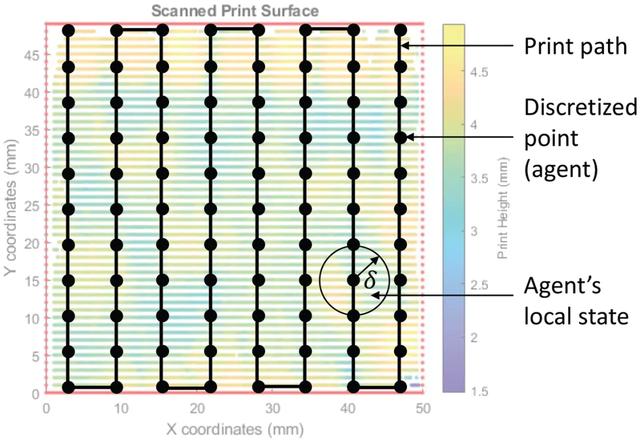
图 5. 在本文所提出的框架中,该层打印路径上的每个离散点都作为一个具有局部状态和独立动作的 agent,进行基于模型的并行强化学习并校正。其中,agent 的本地状态是通过取距离 agent 一个单位内的观测值的平均值来获得的。
为了证明该方法的稳健性和适应性,作者使用两种不同的金属,青铜(ERCuNiAl)和不锈钢(ER316LSi)进行了实验。对于青铜材料,打印了两个尺寸为 50x50x50mm 的六面体,一个使用所提出的学习校正框架,一个使用经典的单道工艺,以便直接比较所提出的学习框架的效果。对于不锈钢材料,作者使用单道工艺打印了一个六面体,以进行结果比较,而使用本文提出的学习校正框架打印了一个更复杂的代表扭锁销形状的零件,其总高度为 460ms。在整个打印过程中有几个不同的沉积路径,最高高度为 360ms,以证明使用本文提出的学习框架打印具有不同打印路径的实际零件并获得更整齐的近净形(near-net-shape)输出的可能性。作者在不使用本文所提出框架的情况下,打印了剩余的 100ms 的扭锁销,以便在不浪费材料的情况下直接比较输出。
1.5 实验结果分析
在打印零件之前,作者先进行了单道研究实验以获得工艺参数窗口值,作者使用文献 [9] 中的方法确定具体的工艺参数以及收集一些数据以初始化所学的动力学函数。图 6 给出了所进行的单道研究的输出样本。对于单道研究,作者使用不同的工艺参数打印了几个焊珠。然后使用移动的二维激光扫描仪对焊珠进行扫描。首先使用移动平均滤波器对点云数据进行过滤,并从过滤后的数据的二阶导数中提取焊珠的趾部点。在单道研究的基础上,作者最终为实验选择的工艺窗口是:青铜的割炬速度为[6, 10]mm/s,送丝速度为[6, 7]m/min。不锈钢的割炬速度为[7, 13]mm/s,送丝速度为[3, 5]m/min。

图 6. 单道研究的照片,与分析的点云叠加以提取数据
1.5.1 青铜材料
在青铜器实验中,作者使用单道研究结果推荐的参数打印了一个六面体,而另一个六面体则通过本文所提出的学习框架打印。图 7 给出了使用基于 agent 的本地状态的算法选择的动作样本。然后,图 8 显示了打印零件的最终输出。从照片中可以看出,利用本文提出的框架生成的打印零件(左边的六面体)具有更均匀的表面高度,从而生成更接近近净形的输出。
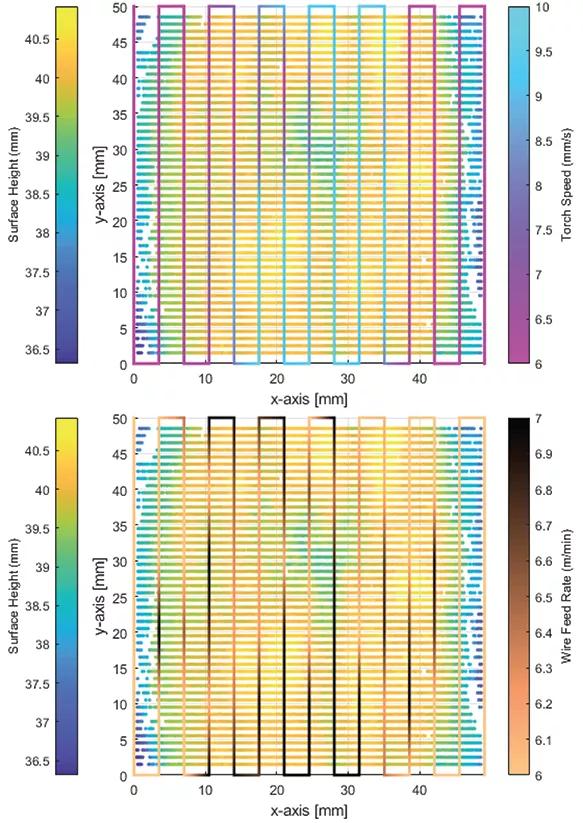
图 7. 基于 agent 的本地状态选择的动作示例

图 8. 青铜材料的打印输出:使用本文提出学习框架(左),以及使用单道推荐的参数(右)
1.5.2 不锈钢材料
对于不锈钢材料,作者使用单道工艺的参数打印了一个六面体,以进行结果比较,同时使用所提出的学习框架打印了一个更复杂的实际零件:一个高度为 460mm 的扭锁销的形状,最高高度为 360mm。该材料的剩余 100mm 不使用框架,而是直接比较打印输出,如图 9 所示。从照片中可以看出,本文框架打印的结果零件(左)具有平坦的表面,而没有使用该框架的打印零件(右)则表现出一个深谷,且随着打印零件高度的增加而不断累积。

图 9. 打印输出不锈钢扭锁销的零件
1.5.3 定量分析
为了进一步定量比较打印零件的表面均匀性,利用表面扫描输出计算每个打印层的表面高度的标准偏差(STD),青铜材料的数值见图 10,不锈钢打印品的数值见图 11。从图中可以看出,使用推荐的单道参数打印的层的表面高度的标准偏差随着两种材料的打印高度的垂直发展而有增加的趋势。
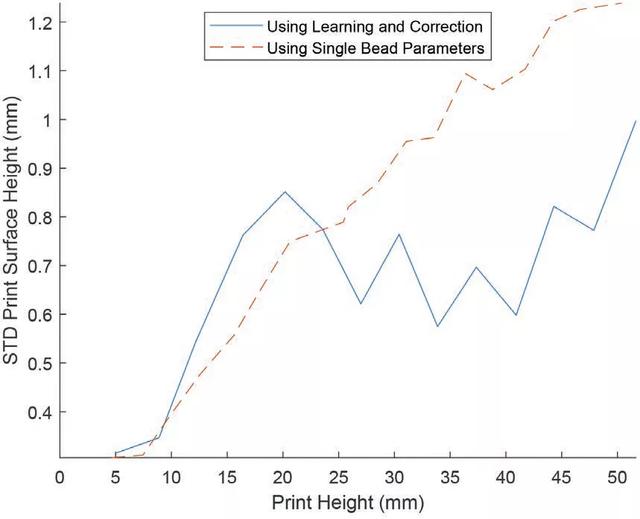
图 10. 使用学习校正框架打印的青铜材料层表面光洁度的标准偏差(STD)与单道研究的推荐参数之间的比较
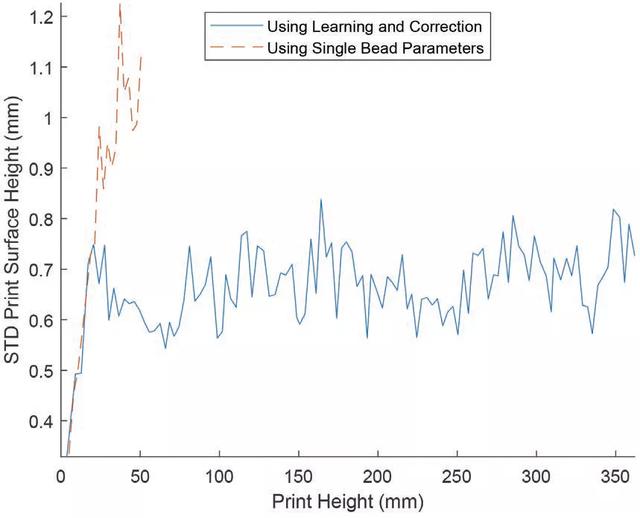
图 11. 使用学习校正框架打印的不锈钢层表面光洁度的标准偏差(STD)与单道工艺推荐参数之间的比较
作者表示,从实验结果来看,使用本文提出的学习框架获得的打印输出表现出更好的表面光洁度和更多的近净形状。这证明了本文提出的学习架构在原位工艺学习和控制方面的可行性。这项研究的研究结果为进行具有成本效益的 MLMB 过程学习提供了可能性。
2 基于深度强化学习的激光粉末床熔的热控制方法[6]

2.1 工艺背景介绍
本文为来自 CMU 的研究人员于 2021 年发表在 Additive Manufacturing 中的一篇文章。激光粉末床熔融(Laser Powder Bed Fusion,LPBF)是 AM 的一个子类别,它通过使用热源将金属粉末层熔融在一起而创造出熔融产品。粉末床融合(Powder Bed Fusion,PBF)方法已被用于从金属合金中构建复杂的晶格产品,并在生物医学和航空航天工业中应用。然而,由于 PBF 生产的零部件容易出现缺陷和低劣的物理性能问题,进而导致特定应用的失败,因此这些方法的广泛推广使用仍面临着挑战。这些缺陷包括不良的表面处理、增加的孔隙、分层和开裂,导致低劣的机械性能和不良的几何一致性等等。以前的实验研究表明,与扫描过程有关的熔融区的特性是造成成品缺陷的重要因素。熔池可以产生钥匙孔和缺乏融合的孔隙,而熔化过程中产生的温度梯度也可以影响形成的微观结构并导致裂缝。为了避免在扫描路径中由于不利的熔池行为以及过热而产生的缺陷,最好能够根据扫描轨迹中不断变化的温度分布调整工艺参数。粉末床融合是一个固有的复杂的多尺度过程,发生在粉末和连续尺度的物理效应决定了最终材料的特性。本文工作聚焦于连续尺度的影响,忽略热源的对流和辐射传热,以考虑热传导对温度场的影响。
在传统的应用中,通常通过引入经典的优化方法制定控制策略以减少机械缺陷的发生。然而,这些方法要求模型的阶数较小,并且考虑到计算费用,它们能够处理的数据量也受到限制。此外,一些统计方法也被用来优化 AM 工艺,如方差分析(analysis of variance)和响应面方法(response surface methodology)等,这些数据驱动的方法由于缺乏对物理环境的感知而受限。当然,陆续已有一些更高级的分析、优化方法不断引入 LPBF 问题中。
近年来,深度强化学习(Deep Reinforcement Learning,DRL)已经成为解决相对高维空间中复杂控制场景的一种有效方法。DRL 是一种深度学习方法,通过收集模拟环境的经验和反馈,对最初的随机控制策略进行迭代改进。强化学习能够利用信息生成决策,非常适用于解决 LPBF 的未知工艺参数和动态变化问题。本文提出了一个 DRL 框架,以创建一个复杂的控制策略来解决 AM 缺陷形成的关键机制,即在熔化过程中熔池深度的变化。
2.2 方法介绍
2.2.1 仿真描述
在这项工作中,作者考虑了移动热源在矩形域中的热传导,使用 [10] 中开发的框架来提高性能。为了使强化学习在计算上可行,需将粉床融合的复杂多尺度效应抽象为材料的连续温度分布。为了做到这一点,首先要做如下几个假设。(1)只考虑传导的传热模式,(2)热性能与温度无关,(3) 粉床被建模为固体连续体,忽略表面粗糙度效应。将该过程建模为与移动热源相关的二维传导,其更新方程如下:
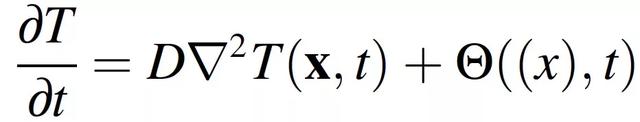
(2.1)
其中,D 表征热扩散性,Θ根据密度和热容量对热源 Q 归一化。该过程相关参数列于表 1。当公式(2.1)使用无限介质中热传导的 Green 函数进行求解时,生成公式(2.2),公式(2.2)具体描述了温度场 T(x, t)。进一步,公式(2.2)可以被分解为对温度解决方案的两个独立贡献,第一项代表热源的作用,第二项代表热扩散过程:

(2.2)
热源的作用可以用 Eagar-Tsai 的传导解决方案来模拟,使用图像法来实现边界条件:
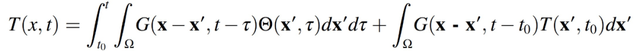
(2.3)
应用如下 Green 函数:
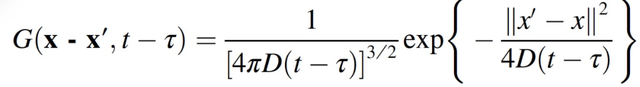
(2.4)
热源可以被参数化为一个在板块表面移动的高斯分布:
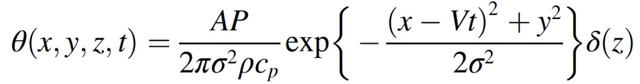
(2.5)
其中,A 是材料的吸收率,P 是激光的功率,V 是激光的速度,σ是激光的直径。由此得到瞬态热传导的 Eagar-Tsai 模型(公式(2.4)),表征在 X 方向速度为 V 的某个Δt 的移动热源所引起的温度分布:
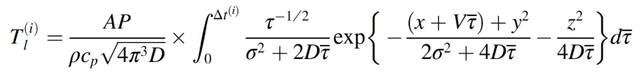
(2.6)
该方法的具体细节由图 12 所示。在求解过程中,作者引入重复使用存储线解决方案方法(Repeated Use of Stored Line Solutions Method,RUSLS)解决 Eagar-Tsai (ET)模型存在的较小的线迹问题,并在考虑到问题的几何形状而进行修改后,重新利用该解决方案来生成激光器随后的热分布。Eagar Tsai 模型的解适用于可适当平移和旋转的移动点源,以表示从给定位置 (x, y) 开始并以θ角移动的运动(公式(2.5)中从时间 t=0 到时间 t=Δt)。对 T_l(i)进行翻译和旋转,以使 (x, y, θ) 与激光在域中的当前位置和方向相匹配。将其添加到现有的温度分布 T′(x, y)中,形成时间 t 的温度分布。为了在现有温度分布的位置继续推进激光,首先对时间 t 到时间 t+Δt 的热扩散进行建模,形成 T′(x, y)_t。然后,再次将 T_l(i)定向到正确的位置,并加入到 T′(x, y)中,形成时间 t+Δt 的 T(x, y)。与标准的有限元分析方法相比,这种处理方式可以在相对较短的时间内迭代许多候选控制策略,从而减少了计算消耗。

表 1. 热学和工艺参数
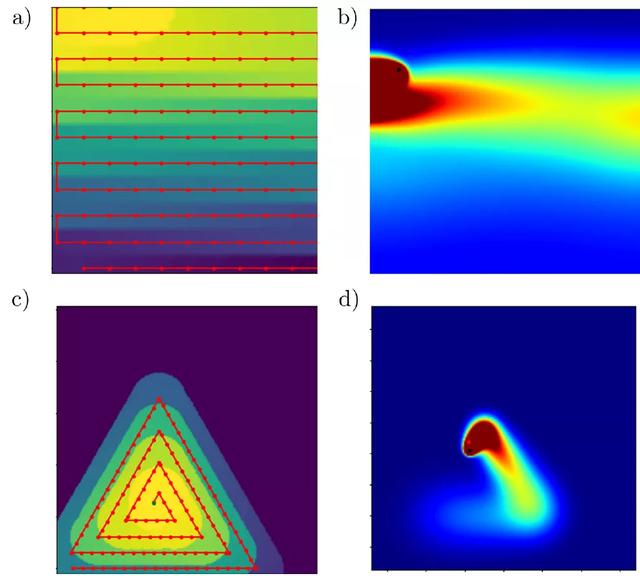
图 12. 用于评估深度强化学习框架性能的扫描路径图示
2.2.2 卷积和边界条件
在域的边界附近,需要修改 Eagar-Tsai 模型以生成合适的线解。如果激光距离区域边界的距离接近 4sqrt(2kΔt/ρc_p),则使用图像法来说明边界对热分布的影响。在计算线解时,在边界另一侧的相同距离处模拟虚拟热源。因此,可以通过在相关边界上镜像法线解来计算边解和角解,以考虑边界与规则动力学的交互作用。该虚拟热源通过修改式(2.6)中的维度积分来实现:
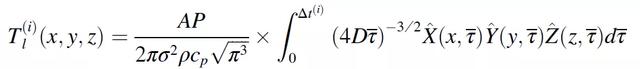
(2.7)
为了说明板上现有温度分布的热扩散历史,在该方法中将公式(2.2)的第二项作为卷积运算实现。由于给定向量场的拉普拉斯算子充当局部平均算子,因此可以通过应用卷积滤波器来近似该算子,其权重由高斯分布确定。该操作可被视为高斯模糊(Gaussian blur),其强度由材料的热特性、发生扩散的时间尺度和激光强度决定。
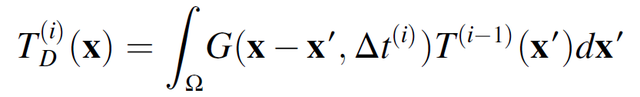
(2.8)
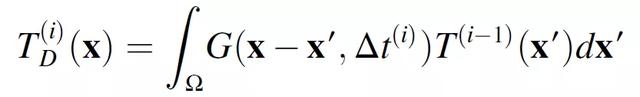
(2.9)
由于卷积滤波器是通过域中每个像素在等距正方形网格中的温度值的加权平均值来执行的,在卷积滤波器可能延伸到网格边界的边界附近必须进行特殊考虑。在边界条件被限制为绝热的情况下,人为地扩展域卷积滤波器的大小。此扩展中的值作为边界附近温度值的镜像。在边界条件被约束为特定温度值的情况下,该扩展部分由参考温度值减去边界附近温度分布的镜像来填充。
熔池深度用作衡量模型成功与否的指标,通过沿 y 轴插值温度场来计算,并找到表面温度最高的位置,然后沿 z 轴插值,以找到表面以下温度处的点,该点首先大于材料的熔化温度。这是通过使用根查找算法(a root finding algorithm)来实现的,该算法基于当前网格离散化最小化材料温度和熔点之间的距离。
2.2.3 增强学习框架
在强化学习中,策略根据环境输入确定要采取的最佳控制动作。这种动作随后会影响环境,而这种影响通过奖励来量化。具体来说,状态空间 S 定义为环境当前状态的低维表示,动作空间 A 定义为 agent 可用的潜在动作,奖励量化了在前一步骤中为实现规定目标而采取的动作的效果。一个 episode 定义为环境的初始状态和最终状态之间的时间段。在这种情况下,每个 episode 被视为激光沿整个扫描路径的一次穿越,初始状态为 t=0,终端状态出现在路径的末端。图 13(a)描述了用于实现 DRL 算法的总体工作流,图 13(b)和图 13(c)分别描述了状态和策略网络的附加上下文。

图 13. 深度强化学习框架
强化学习优化范式的目标是在一个 episode 中获得最大的奖励,这是通过生成一个策略π来实现的。策略π根据 agent 的当前状态选择一个操作,以便最大化未来预期奖励。agent 根据策略π完成动作,给定状态的未来预期收益记为值函数 V^π(s),而在采取特定动作 a 之后,以及随后根据策略π完成动作时,给定状态的未来预期奖励称为动作值函数 Q^π(s,a)。对策略进行迭代优化,以找到使 Q^π(s,a)的值最大化的最优策略π。
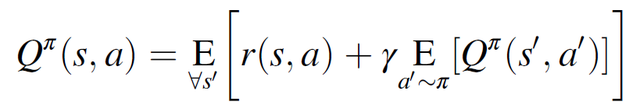
(2.10)
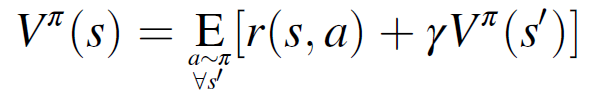
(2.11)
其中 s′是指 agent 在采取动作 a 后的下一个状态,a′是指在状态 s′中要采取的动作,r(s,a)是 agent 在采取动作 a 后在状态 s 中观察到的奖励。在公式(2.11)中,状态空间定义为特定视图和方向上的温度场观测值。状态空间作为 9 个二维热图传递给策略网络,该热图显示了激光当前位置周围的局部温度分布。具体地说,在激光器周围定义了一个 160μm×160μm 的区域,在 x-y 横截面上以激光器为中心,在 y-z 和 x-z 横截面上从域表面向下延伸。这组温度场的三个横截面快照与之前在事件轨迹期间观察到的两组快照相衔接。对温度值进行白化处理,减去平均值,再除以状态空间的标准偏差,以逼近数据的标准正态分布。
将行动空间定义为对激光特性进行的工艺参数更新,这些更新表征改变熔化过程的行为。对于速度控制方案,提供了激光从轨迹中的一个预定点到下一个点的速度,同时为基于功率的控制指定了功率。将这些动作调整到 [-1, 1] 范围内,以避免出现激活函数中常见的梯度消失问题。
![]()
(2.12)
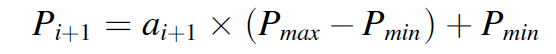
(2.13)
公式(2.12)和(2.13)中,v 和 P 分别表示基于规定动作的速度和功率。奖励函数量化了控制策略在一个 episode 中的性能,奖励定义为目标熔化深度和当前深度之间的绝对误差。此外,还增加了一个避免 “欺骗(cheating)” 的正则化项,该正则化项的作用是惩罚在 episode 期间观察到的最小和最大熔融深度之间的距离,从而避免可能导致熔融深度突然峰值的异常策略。

(2.14)
2.2.4 逼近策略优化
为了优化策略网络,作者使用了策略梯度法(Policy Gradient methods)的一个子类:近端策略优化(Proximal Policy Optimization,PPO)算法。策略梯度法通过梯度上升概率地搜索最优策略。该策略基于优势函数 A^π进行优化,A^π表示通过执行特定动作产生的预期奖励的变化,A^π与从给定状态开始的一组可能动作的预期未来平均奖励相关。
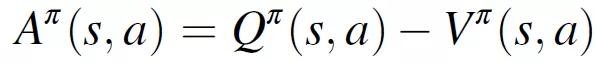
(2.15)
近端策略优化基于新策略利用观察到的预期奖励的相对增加来限制梯度上升步骤的最大值。之所以选择这种方法,是因为相对于信赖域策略优化(Trust Region Policy Optimization),PPO 在实现上是流线型的,并且与类似的强化学习方法相比,它需要更少的超参数调整和 Actor-Critic 优化。此外,它更适合于连续控制问题。策略梯度方法是 episodic 的,因为策略网络在一个 episode 完成后根据累积的奖励进行更新。在此设置中,每一个 episode 被定义为激光完成整个扫描路径的整个过程。本文实现了一个近端策略优化的矢量化版本,其中并行部署多个 agent 以收集经验流并更新相同的策略网络。将 PPO 矢量化处理可以减少算法收集必要经验以学习最佳策略所需的时间。
2.2.5 经验生成和模型训练
近端策略优化算法针对 15000 个 episodes 更新进行训练。策略网络用于将状态映射到其对应的行动中,策略网络由两个隐藏层组成,其中,每个隐藏层具有 64 个神经元和双曲正切激活函数。该算法在八个环境中并行训练,来自这些并行环境的经验被用于同步更新模型。在预定的轨迹间隔内采取控制措施,水平扫描路径为 100μm,三角形扫描路径为 50μm,其中,每个间隔定义为 DRL 框架的单步迭代。表 1 给出了描述介质热特性的参数以及激光热源的尺寸。
2.3 实验分析
2.3.1 速度控制
作者应用上述 PPO 支持的深度强化学习算法来优化单层制造过程中形成的熔池深度。该方法适用于两种不同的轨迹,一种是激光粉末床聚变工业应用中常用的水平交叉阴影策略(图 12a),另一种是一系列同心三角形,用于放大次优激光轨迹或粉末床密闭部分发生的过热现象(图 12c)。由于 DRL 算法能够找到随时间变化的工艺参数的策略,因此作者将每个控制策略的性能与在整个熔炼过程中工艺参数保持不变而产生的熔池深度进行比较。
图 14 给出了在熔化过程中严格控制激光速度时发现的水平交叉阴影轨迹控制策略。在整个轨迹使用相同速度的情况下,轨迹每四分之一间隔处的熔体深度都有明显的峰值。在这些区域,熔池深度增加多达 20μm。我们观察到的熔化深度增加是由于在激光改变方向的位置处能量的积累,以及阻止热能逃逸的绝热边界条件。引入 DRL 算法优化控制策略,能够通过修改轨迹上某些点的速度来限制这些影响。当激光接近域的边缘时,激光的速度会增加,以减少转移到域的能量,从而避免由于热量扩散的能力降低而导致最大熔化深度的峰值。与恒定激光速度的性能相比,学习到的控制策略能够使熔池深度的变化远远小于恒定工艺参数。虽然在熔化过程中熔化深度在某些点上略微低于目标熔化深度,但熔化深度所占据的范围比在未受控制的情况下观察到的范围要窄很多。因此,假设熔池的面积可以与轨迹上任何给定点的熔池深度相关联,应用速度控制的结果是熔池的面积更加一致,明显不容易形成锁眼(keyhole)。图 15(a)和 16(a)显示了控制策略所显示的变化的减少。
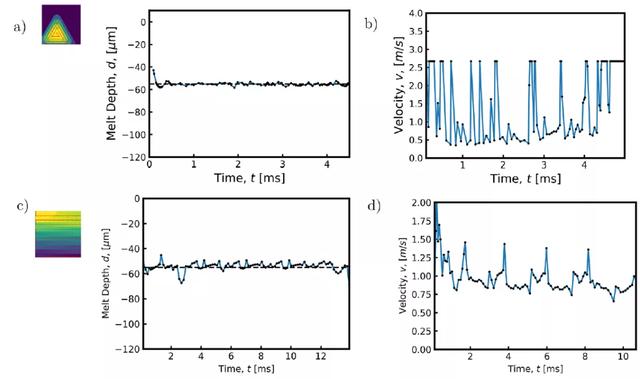
图 14. (a) 发现的水平交叉阴影扫描路径的控制策略。当激光在边界附近反转方向以减少这些区域的热能积累时,速度增加。(b) 按照导出的控制策略,同心三角形扫描路径实现的熔体深度。(c) 根据导出的控制策略,水平交叉阴影扫描路径达到的熔化深度。(d) 导出了同心三角形路径的控制策略。当激光改变方向时,速度增加,当激光接近扫描路径中心时,平均速度逐渐增加

图 15. (a) 对于水平交叉阴影扫描路径,由控制策略生成的熔体深度与由恒定速度生成的熔体深度相比较。与在整个熔化过程中采用恒定速度相比,熔池深度更稳定。(b) 控制策略生成的熔体深度与同心三角形扫描路径恒定速度生成的熔体深度进行比较。与在整个熔化过程中采用恒定速度相比,熔池深度更稳定

图 16. (a) 控制策略生成的熔体深度直方图与水平交叉阴影扫描路径恒定速度生成的熔体深度直方图进行比较。熔融过程中产生的熔池深度平均值更接近目标熔池深度,且标准偏差较小。(b) 控制策略生成的熔体深度直方图,与同心三角形扫描路径恒定速度生成的熔体深度进行比较。熔融过程中产生的熔池深度平均值更接近目标熔池深度,且标准偏差较小
在同心三角形轨迹上训练模型时,算法也能通过修改激光接近域中心时的速度来学习合适的策略。在未受控制的情况下,每次激光扭转方向完成同心三角形轨迹时,熔池深度都会大大增加。此外,在接近轨迹末端时,由于轨迹的重叠段和方向反转频率的增加,热能积聚在轨迹中心。在轨迹的最后 20% 处的熔池深度中也可以看到这种热能积累,其中,突然增加了 40μm。与恒定工艺参数的情况相比,利用 DRL 学习到的策略能够避免在轨迹结束时出现的熔体深度的大跳跃。当激光改变行进方向时,速度增加,与水平交叉划线扫描路径类似。另外,激光的平均速度在接近扫描路径的中心时增加,速度保持在可能的最大值以减少过热现象。图 15(b)详细说明了引入控制策略可以保证熔池稳定,图 16(b)则说明了在稳定的熔池中没有出现过热现象。
2.3.2 能量控制
针对能量控制问题,作者通过改变激光的功率来优化熔池的深度。由于激光运动的物理限制,在一个层的运行过程中快速改变速度并不是一定可行的。此外,过高的速度值会在熔池中诱发 Rayleigh 不稳定性,从而导致成球缺陷(balling defects )。因此,作者还研究了用于控制熔池深度的基于功率的控制机制。该方法适用于前面研究的相同轨迹,如图 12 所示,具有表 1 所示的相同物理参数。如图 17 和图 18 所示,当激光通过扫描路径移动时,agent 能够成功学习调节激光功率以实现恒定熔池深度的策略。激光功率在拐角处和残余热浓度较大的区域降低,使熔池随时间保持一致。在比较功率控制策略和速度控制策略的性能时,我们可以观察到水平轨迹的稳定性略有增加(累积误差减少 68.2% vs 63.8%),三角形轨迹的稳定性略有下降(累积误差减少 74.6% vs 90.6%)。

图 17. (a) 按照导出的控制策略,同心三角形扫描路径实现的熔体深度。(b) 发现的水平交叉阴影扫描路径的控制策略。当激光在边界附近反转方向以减少这些区域的热能积累时,功率降低。(c) 导出了同心三角形路径的控制策略。当激光改变方向时,功率降低,随着激光接近扫描路径中心,平均功率也逐渐降低。(d) 根据导出的控制策略,水平交叉阴影扫描路径达到的熔化深度

图 18.(a) 功率控制策略生成的熔深与水平交叉阴影扫描路径的恒定功率生成的熔深相比。与在整个熔化过程中施加恒定功率和速度相比,熔池深度更稳定。(b) 功率控制策略生成的熔体深度与同心三角形扫描路径的恒定功率和速度生成的熔体深度相比。与在整个熔化过程中施加恒定功率相比,熔池深度更稳定
本文提出了一种提高激光粉末熔床产品质量的深度强化学习方法。通过迭代优化策略网络以最大化熔化过程中的预期奖励,利用 PPO 生成能够减少缺陷形成的控制策略。通过上述实验,作者发现有效的控制策略能够减少模拟中不同扫描路径下观察到的熔池变化,进而证明了该方法的有效性。具体来说,基于速度的控制和基于功率的控制方法能够降低由于激光区域和轨迹的几何形状而导致的过热问题,同时减少了熔池深度的变化。利用观察熔化过程中特定速度或功率选择所生成的奖励,DRL 的策略能够做到在热量可能积聚的地方增加速度或减少功率,从而降低了缺陷形成的可能性。
3 基于声频发射(Acoustic Emission)的 AM 现场质量监测:一种强化学习方法[7]

3.1 方法思路介绍
本文聚焦 AM 领域中的一个技术难题:现场质量监测。尽管 AM 技术拥有很多优势,但将其应用于大规模生产仍然存在很多问题,其中一个主要的原因是工件之间缺少工艺可再现性和质量保证。因此,人们迫切需要一种可靠的、经济高效的 AM 现场实时质量监测技术。
AM 质量监测的发展主要集中在三个主要领域:(a)通过高温计或高速摄像机测量熔池温度;(b) 工件各层表面图像分析;(c) 整个工件的 x 射线相衬成像(x-ray phase-contrast imaging,XPCI)和 / 或 x 射线计算机断层扫描(xray computed tomography,XCT)。上述每种技术都存在限制其大规模生产适用性的缺点。首先,熔体池的温度测量仅限于熔体表面,没有关于整个深度内复杂液体运动和热量分布的信息。其次,图像处理方法在生成整个层后评估质量,并且只能检测正在构建的层表面的缺陷,并不能检测熔池内产生的缺陷,如气孔。再次,两种 x 射线方法都是昂贵和耗时的。XPCI 仅能用于实验室条件下的现场和实时监测,无法应用于实时处理。XCT 只有在工件从造板上移除后才能执行,由于成本高,只能在有限的情况下由行业应用。
本文首次提出了结合声频发射(Acoustic Emission,AE)和强化学习(RL)的对粉末床熔融添加剂制造(Powder Bed Fusion Additive Manufacturing,PBFAM)过程进行现场和实时质量监测的方法。AE 能够捕获过程的表面下动力学信息(subsurface dynamics of the process),RL 为一种机器学习方法。AE 的优点是通过实用、经济高效的硬件能够实现可靠地监测多种物理现象。
3.2 实验设置、材料和数据集
作者使用一台工业 ConceptM2 PBFAM 机器来收集 AE 数据集并重现工业环境。Concept M2 配备了一个以连续模式工作的光纤激光器,波长为 1071nm,光斑直径为 90μm,光束质量为 M^2=1.02。此外,为了监测在调幅过程中产生的空气中的 AE 信号,在机器上安装了一个被称为光纤布拉格光栅(fiber Bragg Grating,FBG)的光声传感器。使用 CL20ES 不锈钢(1.4404/316L)粉末完成 AM 制造,粒度分布范围为 10 至 45 μm。实验制造了一个尺寸为 10 x 10 x 20 mm^3 的长方体工件。激光功率(P)、孵化距离(h)和加工层厚度(t)在实验中保持恒定,P = 125 W,h = 0.105 mm,t = 0.03 mm。使用了三种扫描速度 v:800、500 和 300 mm/s,从而产生了三个质量级别(不同的孔隙浓度)。对应的能量密度(E_density)和质量等级为:(1)800mm/s,50J/mm^3,较差质量 = 1.42±0.85%;(2)500mm/s,79J/mm^3,较高质量 = 0.07±0.02%;(3)300mm/s,132J/mm^3,中等质量 = 0.3±0.18%。利用公式(3.1)计算能量密度,其中,孔隙的浓度是通过光学显微镜图像的视觉检查从截面上测量的:
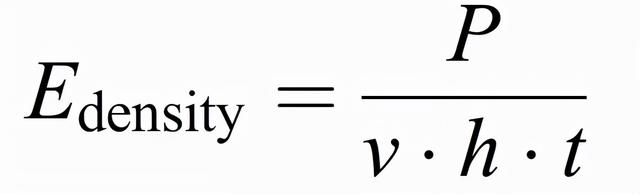
(3.1)
图 19 给出了制造出来的工件的总体视图(在取了一小块来做横截面之后),以及在材料介质内的孔隙浓度方面的相应质量。在整个制造过程中,使用一个 FBG 来记录 AE 信号。将光纤光栅安装在室内,与加工区的距离约为 20 厘米。为了提高 FBG 的灵敏度,如图 20(a)所示,将它放置在纤维的纵轴与声波垂直的地方。图 2(b)展示了 FBG read-out 系统的方案。与压电式传感器相比,FBG 传感器有几个优点。FBG 既可以夹在机器上使用,也可以在空中使用。它较小(总直径为 125lm,长度为 1cm),对声音信号(0-3MHz)高度敏感,对灰尘和磁场不敏感,并提供亚纳秒级的时间分辨率,因此符合在肮脏和嘈杂环境中的实际应用需求。使用 Vallen(Vallen Gmbh,德国)的专用软件以 10MHz 的原始采样率记录 AE 信号。然后,信号被下采样为 1MHz 的采样率,以适应该过程的动态范围(0 Hz-200 kHz)。然后根据质量水平对 AM 过程中记录的 AE 信号进行分类。

图 19. (a)用三种孔隙度含量生产的测试工件;(b-d)各区域的典型光镜横截面图像
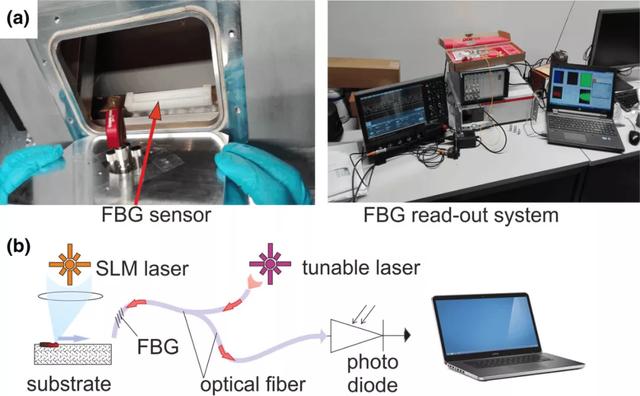
图 20. (a) AM 室内的 FBG 位置图,室内面板上有光学真空电极(optical feedthrough)(左)和 FBG read-out 系统(右);(b) FBG read-out 系统方案
3.3 数据处理
本文具体研究强化学习(RL)对 AM 质量监测问题的适用性。本文采用了 Silver 和 Huang 的 RL 实现方法[11],这是因为作者认为它很有可能用于未来的 AM 质量监测系统。作者引入 RL 的考虑是,AM 过程的特点是复杂的基本物理现象,涉及大量的瞬间事件(加热、熔化、固化等),每一个都对过程的状态变化有至关重要的影响。这使得获取一个详细的训练数据集变得非常复杂,对数据打标签往往非常昂贵和耗时。在这种情况下,RL 可能会需要在极其有限的有监督数据条件下提供声频发射信号和检测到的瞬间事件之间的关联信息。
将所有收集到的信号分成独立的数据集,每个单独的模式的时间跨度为 160ms。从小波包变换中提取了每个模式的相对能量。图 21 给出一个时间跨度为 160ms 的 AE 信号的典型示例和相应的小波谱图。小波谱图是一个信号的时间 - 频率域,它包含了窄频带在时间上的演变信息。使用小波谱图的原因有三个。首先,小波谱图是信号的稀疏表示,与 AE 原始信号相比,减少了分析的输入数据量。其次,它保持了相同的分类精度。最后,它通过选择非噪声频段来降低噪声。表 2 给出了不同参数的空间分辨率。将提取的小波谱图直接输入 RL 算法。初始总数据集(训练 + 测试数据集)包括总共 180 个谱图,平均分布在三个质量等级。
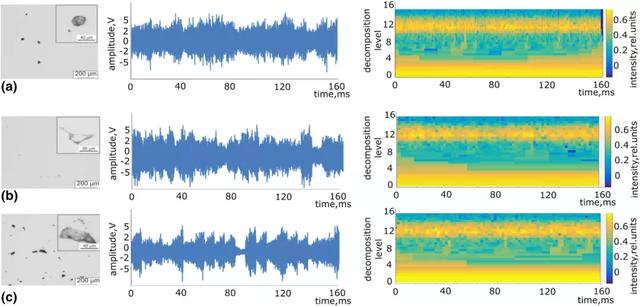
图 21. (左)典型的光镜截面图像,(中)相应的 AE 信号,时间跨度为 160ms,(右)相应的小波谱图,生成区域为(a)300mm/s,132mm^3(中等质量),(b)500mm/s,79mm^3(高质量)和(c)800mm/s,50mm^3(质量差)

表 2. 不同工艺参数下的工艺空间分辨率
3.4 强化学习
RL agent 与给定环境的交互是一个马尔可夫过程,其特征为元组(S,A,P,R),其中 S 表示 agent 的状态空间,A 为动作空间,其中每个动作 a_i 从状态 s 转移到 s^l。P 为马尔可夫模型,R 为奖励空间。初始状态设定为 s_0,RL 算法通过获得最优奖励的动作达到目标 s_g。最优奖励的评价方程为:
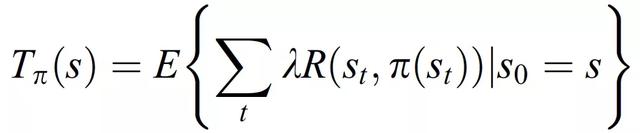
(3.2)
其中,E 为期望,λ为折扣系数,π(s_t)为将状态映射到动作的策略。最佳策略的搜索是一个迭代过程,因此在第 i 个迭代步骤中,计算 T_(π,i),其中 (π, i) 表征当前策略,根据公式(3.3)计算 Q 值:

(3.3)
此外,作者利用了 Glover 和 Laguna 的 Tabu 搜索[12]。在这个框架中,通过分析状态空间的一个限定子集来进行近似最优路径的搜索,从而在大数据集的情况下减少探索并保留计算时间。针对 multi-class 的问题,作者采用 one-against all 策略。agent 的环境是由小波谱图创建的,小波谱图是信号的时频空间的二维图。在这种情况下,通过对上述领域的成本构建来寻找最佳策略。
3.5 实验分析
图 21 给出三种不同质量的典型光镜横截面图像(左),其对应的 160ms 时间跨度的 AE 信号(中)和其对应的小波谱图(右)。根据这个图,可以得出两个结论。首先,AE 信号是可以区分的。尽管所有 AE 信号的振幅相似,但信噪比似乎随着扫描速度的增加而增加。其次,在小波谱图中也可以看到明显的差异,特别是在 4 到 12 的分解级别中。因此,我们使用小波谱图,因为与 AE 原始信号相比,它们具有更高的稳健性。
每个类别都有一个包含 60 个小波谱图的数据集。这些信号被分成两个完全独立的数据集;一个用于训练,一个用于测试。需要强调的是,在训练过程中,全部测试数据都是算法未知的。训练数据集包含 40 个谱图,而每个类别的其他 20 个谱图被用来测试 RL 算法。谱图的选择是随机进行的。利用类似蒙特卡洛的方法进行两百次测试,即对于这两百次测试中的每一次,用于建立特定训练和测试数据集的信号都是从最初收集的数据集中随机选择的。这种策略允许改变算法的输入条件,并通过不同的训练 / 测试组合来研究其性能,以获得对 AE 信号收集的可靠统计测试。每项测试的准确性被计算为真阳性的数量除以测试的总数量(如测试数据集中的样本数量)。总的准确性被计算为一个平均值,确定为:
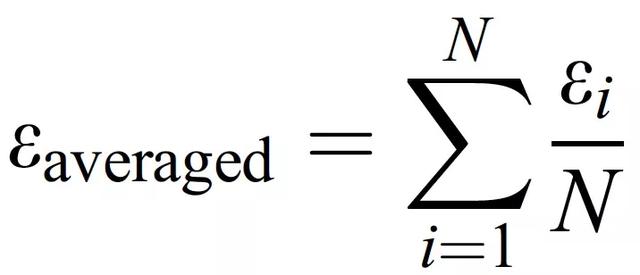
(3.3)
其中,N 等于 200(测试总数)。相比之下,分类误差的计算方法是用真阴性的数量除以每类测试的总数量。分类测试结果见表 3,分类准确率在 74% 到 82% 之间(见对角线单元格中的黑体数字)。这些结果证明了本文提出的方法对 AM 过程进行质量监测的可行性。由表 3 可以看出,质量差的准确率最高(82%),其次是中等质量(79%)和高质量(74%)。此外,对分类误差结构的分析可以根据表 3 中的非对角线行进行评估。从统计学上看,表中的误差结构恢复了来自预定的质量类别的不同特征之间的重叠。表 3 显示,对于较差质量和中等质量,激光扫描速度差异较小的类之间的错误分类误差较大(反之亦然)。因此,对于具有中等激光扫描速度(500mm/s)的高质量,错误分类误差也大约在中等质量(12%)和差质量(14%)之间平分。同时,中等质量和较差的质量之间显示出较少的重叠误差,因为它们在激光扫描速度上有较大的差异。

表 3. 不同类别的测试结果(百分比)(行)与真实值(列)的对比
4 小结
我们结合三篇近期的研究论文,简述了在增材制造(3D 打印)领域中强化学习方法的应用。增材制造通过降低模具成本、减少材料、减少装配、减少研发周期等优势来降低企业制造成本,提高生产效益。因此,增材制造代表了生产模式和先进制造技术发展的趋势。
增材制造也有不同的细分方法,本文介绍了电弧增材制造(Wire Arc Additive Manufacturing,WAAM)、激光粉末床熔融(Laser Powder Bed Fusion,LPBF)以及粉末床熔融添加剂制造(Powder Bed Fusion Additive Manufacturing,PBFAM)三个细分领域中强化学习的应用,主要是对制造过程中的温度、声频等的控制,具体分别为过程控制的应用和实时监测的应用。强化学习具有根据环境学习控制策略的能力,因此对有标注的数据集要求较低,且通过自学能够提高对 AM 过程控制的准确度。从我们介绍的三篇文章可以看出,在 AM 中引入强化学习能够提高增材制造打印零件的质量水平。
增材制造本身由于技术工艺的约束还未能大规模的广泛推广使用,而在增材制造中引入强化学习还主要是实验研究。目前看,在增材制造中引入强化学习方法具有节省时间、减少材料浪费等优点,基于这一积极的初步结果,我们相信未来会有越来越多的工作将引入强化学习的框架扩展到全面的增材制造过程学习中。
本文参考引用的文献:
[1]https://baike.baidu.com/item/%E5%A2%9E%E6%9D%90%E5%88%B6%E9%80%A0/3642267?fr=aladdin
[2] Qi X , Chen G , Li Y , et al. Applying Neural-Network-Based Machine Learning to Additive Manufacturing: Current Applications, Challenges, and Future Perspectives[J]. 工程(英文), 2019, 5(4):9.
[3] Liu L, Ding Q, Zhong Y, Zou J, Wu J, Chiu YL, et al. Dislocation network in additive manufactured steel breaks strength–ductility trade-off. Mater Today 2018;21(4):354–61.
[4] http://www.tsc-xa.com/article/index/id/12/cid/2.
[5] Audelia G. Dharmawan, Yi Xiong, Shaohui Foong, and Gim Song Soh, A Model-Based Reinforcement Learning and Correction Framework for Process Control of Robotic Wire Arc Additive Manufacturing,ICRA 202, 4030-4036.
[6] Ogoke F , Farimani A B . Thermal Control of Laser Powder Bed Fusion Using Deep Reinforcement Learning. Additive Manufacturing, 46(2021).
[7] Wasmer K , Le-Quang T , Meylan B , et al. In Situ Quality Monitoring in AM Using Acoustic Emission: A Reinforcement Learning Approach. Journal of Materials Engineering and Performance, 2019.
[8] J. Xiong, Z. Yin, and W. Zhang, “Forming appearance control of arc striking and extinguishing area in multi-layer single-pass gmawbased additive manufacturing,” The International Journal of Advanced Manufacturing Technology, vol. 87, no. 1-4, pp. 579–586, 2016.
[9] S. Suryakumar, K. Karunakaran, A. Bernard, U. Chandrasekhar, N. Raghavender, and D. Sharma, “Weld bead modeling and process optimization in hybrid layered manufacturing,” Computer-Aided Design, vol. 43, no. 4, pp. 331–344, 2011.
[10] A.J. Wolfer, J. Aires, K. Wheeler, J.-P. Delplanque, A. Rubenchik, A. Anderson, S. Khairallah, Fast solution strategy for transient heat conduction for arbitrary scan paths in additive manufacturing, Addit. Manuf. 30 (2019), 100898.
[11] D. Silver and A. Huang, Mastering the Game of Go with Deep Neural Networks and Tree Search, Nature, 2016, 529, p 484–489. https://doi.org/10.1038/nature16961
[12] F. Glover and M. Laguna, Tabu Search, Kluwer Academic Publishers, 1997
分析师介绍:
本文作者为Wu Jiying,工学博士,毕业于北京交通大学,曾分别于香港中文大学和香港科技大学担任助理研究员和研究助理,现从事电子政务领域信息化新技术研究工作。主要研究方向为模式识别、计算机视觉,爱好科研,希望能保持学习、不断进步。
关于机器之心全球分析师网络 Synced Global Analyst Network
机器之心全球分析师网络是由机器之心发起的全球性人工智能专业知识共享网络。在过去的四年里,已有数百名来自全球各地的 AI 领域专业学生学者、工程专家、业务专家,利用自己的学业工作之余的闲暇时间,通过线上分享、专栏解读、知识库构建、报告发布、评测及项目咨询等形式与全球 AI 社区共享自己的研究思路、工程经验及行业洞察等专业知识,并从中获得了自身的能力成长、经验积累及职业发展。